 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeloTrans: A Text to Symbolic Music Generation Model Following Human Composition Habit
Oct 17, 2024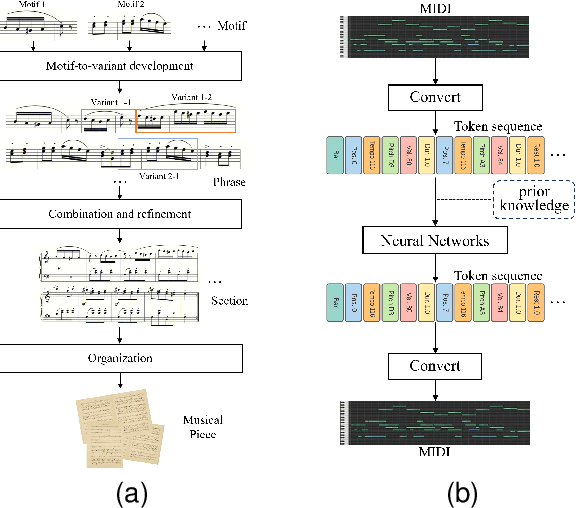

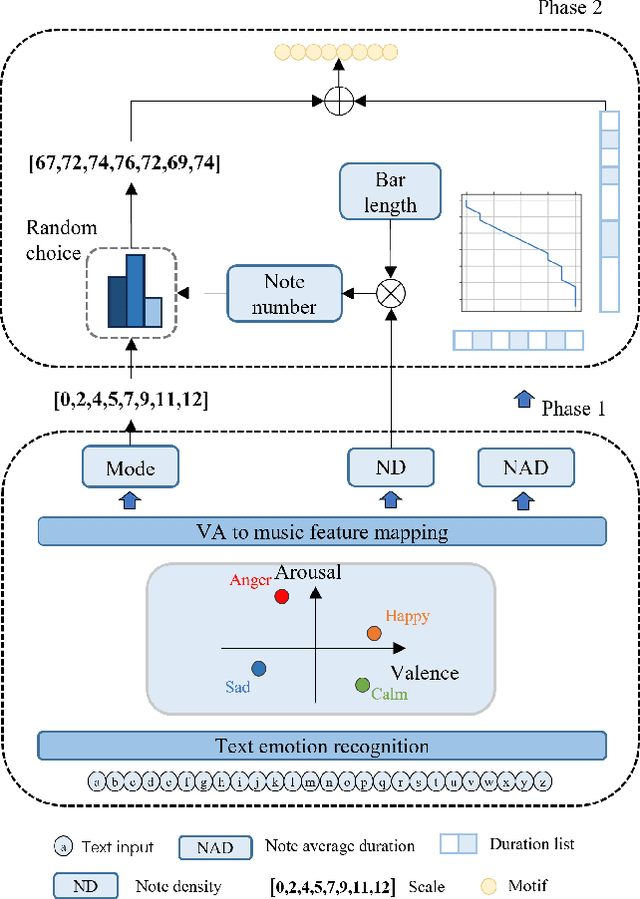
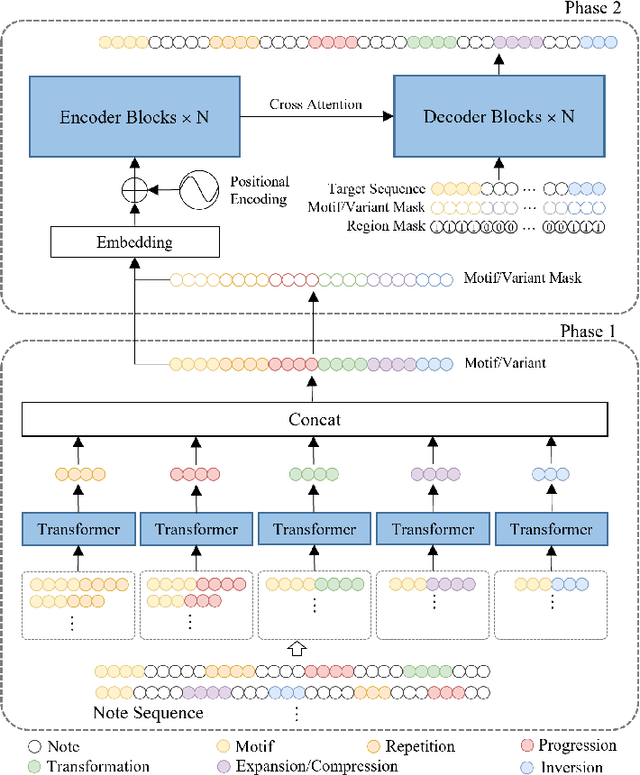
At present, neural network models show powerful sequence prediction ability and are used in many automatic composition models. In comparison, the way humans compose music is very different from it. Composers usually start by creating musical motifs and then develop them into music through a series of rules. This process ensures that the music has a specific structure and changing pattern. However, it is difficult for neural network models to learn these composition rules from training data, which results in a lack of musicality and diversity in the generated music. This paper posits that integrating the learning capabilities of neural networks with human-derived knowledge may lead to better results. To archive this, we develop the POP909$\_$M dataset, the first to include labels for musical motifs and their variants, providing a basis for mimicking human compositional habits. Building on this, we propose MeloTrans, a text-to-music composition model that employs principles of motif development rules. Our experiments demonstrate that MeloTrans excels beyond existing music generation models and even surpasses Large Language Models (LLMs) like ChatGPT-4. This highlights the importance of merging human insights with neural network capabilities to achieve superior symbolic music generation.