 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeloTrans: A Text to Symbolic Music Generation Model Following Human Composition Habit
Oct 17, 2024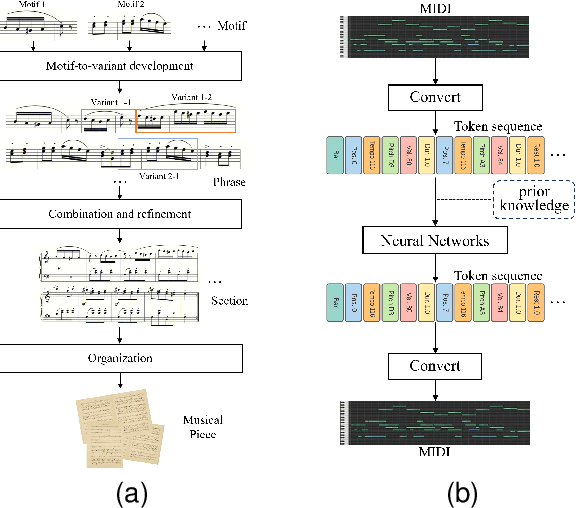

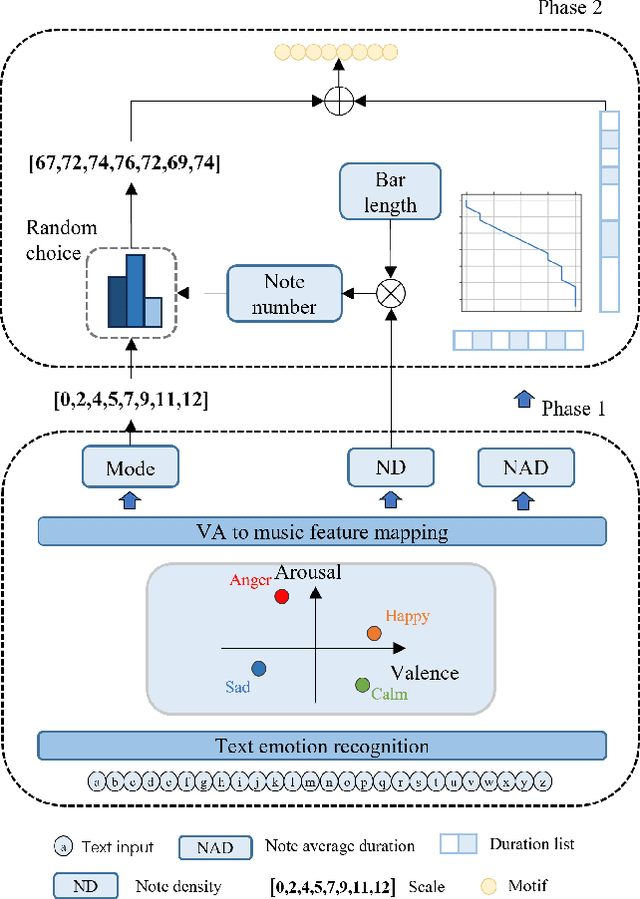
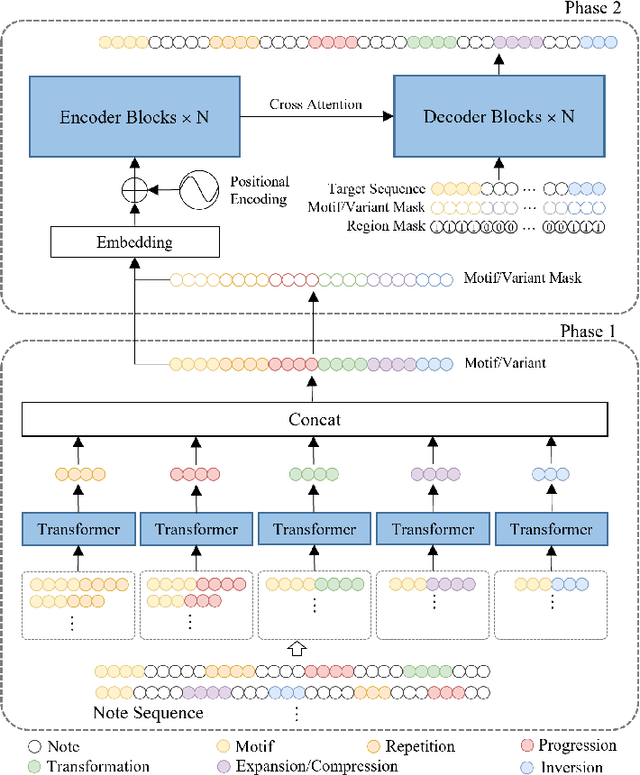
At present, neural network models show powerful sequence prediction ability and are used in many automatic composition models. In comparison, the way humans compose music is very different from it. Composers usually start by creating musical motifs and then develop them into music through a series of rules. This process ensures that the music has a specific structure and changing pattern. However, it is difficult for neural network models to learn these composition rules from training data, which results in a lack of musicality and diversity in the generated music. This paper posits that integrating the learning capabilities of neural networks with human-derived knowledge may lead to better results. To archive this, we develop the POP909$\_$M dataset, the first to include labels for musical motifs and their variants, providing a basis for mimicking human compositional habits. Building on this, we propose MeloTrans, a text-to-music composition model that employs principles of motif development rules. Our experiments demonstrate that MeloTrans excels beyond existing music generation models and even surpasses Large Language Models (LLMs) like ChatGPT-4. This highlights the importance of merging human insights with neural network capabilities to achieve superior symbolic music generation.
Mimicking the Mavens: Agent-based Opinion Synthesis and Emotion Prediction for Social Media Influencers
Jul 30, 2024



Predicting influencers' views and public sentiment on social media is crucial for anticipating societal trends and guiding strategic responses. This study introduces a novel computational framework to predict opinion leaders' perspectives and the emotive reactions of the populace, addressing the inherent challenges posed by the unstructured, context-sensitive, and heterogeneous nature of online communication. Our research introduces an innovative module that starts with the automatic 5W1H (Where, Who, When, What, Why, and How) questions formulation engine, tailored to emerging news stories and trending topics. We then build a total of 60 anonymous opinion leader agents in six domains and realize the views generation based on an enhanced large language model (LLM) coupled with retrieval-augmented generation (RAG). Subsequently, we synthesize the potential views of opinion leaders and predicted the emotional responses to different events. The efficacy of our automated 5W1H module is corroborated by an average GPT-4 score of 8.83/10, indicative of high fidelity. The influencer agents exhibit a consistent performance, achieving an average GPT-4 rating of 6.85/10 across evaluative metrics. Utilizing the 'Russia-Ukraine War' as a case study, our methodology accurately foresees key influencers' perspectives and aligns emotional predictions with real-world sentiment trends in various domains.
Clifford Algebra-Based Iterated Extended Kalman Filter with Application to Low-Cost INS/GNSS Navigation
Nov 15, 2023



The traditional GNSS-aided inertial navigation system (INS) usually exploits the extended Kalman filter (EKF) for state estimation, and the initial attitude accuracy is key to the filtering performance. To spare the reliance on the initial attitude, this work generalizes the previously proposed trident quaternion within the framework of Clifford algebra to represent the extended pose, IMU biases and lever arms on the Lie group. Consequently, a quasi-group-affine system is established for the low-cost INS/GNSS integrated navigation system, and the right-error Clifford algebra-based EKF (Clifford-RQEKF) is accordingly developed. The iterated filtering approach is further applied to significantly improve the performances of the Clifford-RQEKF and the previously proposed trident quaternion-based EKFs. Numerical simulations and experiments show that all iterated filtering approaches fulfill the fast and global convergence without the prior attitude information, whereas the iterated Clifford-RQEKF performs much better than the others under especially large IMU biases.
An Efficient Temporary Deepfake Location Approach Based Embeddings for Partially Spoofed Audio Detection
Sep 06, 2023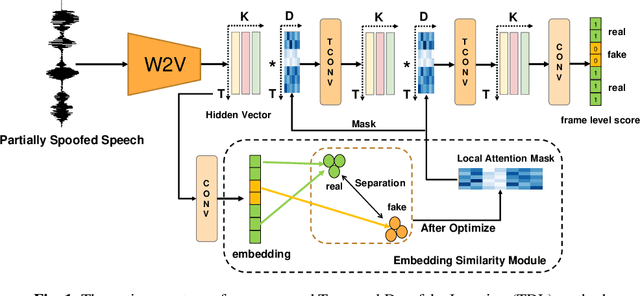
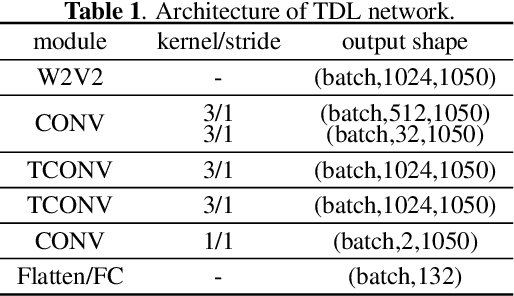
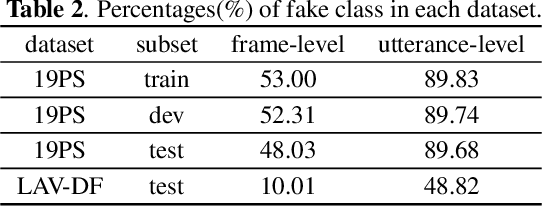
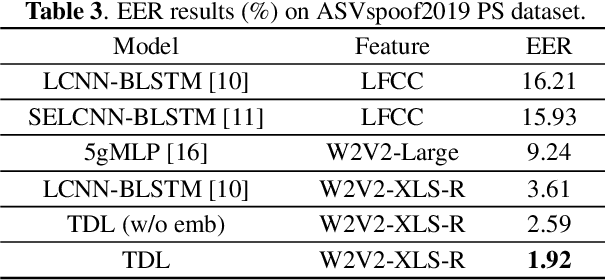
Partially spoofed audio detection is a challenging task, lying in the need to accurately locate the authenticity of audio at the frame level. To address this issue, we propose a fine-grained partially spoofed audio detection method, namely Temporal Deepfake Location (TDL), which can effectively capture information of both features and locations. Specifically, our approach involves two novel parts: embedding similarity module and temporal convolution operation. To enhance the identification between the real and fake features, the embedding similarity module is designed to generate an embedding space that can separate the real frames from fake frames. To effectively concentrate on the position information, temporal convolution operation is proposed to calculate the frame-specific similarities among neighboring frames, and dynamically select informative neighbors to convolution. Extensive experiments show that our method outperform baseline models in ASVspoof2019 Partial Spoof dataset and demonstrate superior performance even in the crossdataset scenario. The code is released online.
Unsupervised Quantized Prosody Representation for Controllable Speech Synthesis
Apr 07, 2022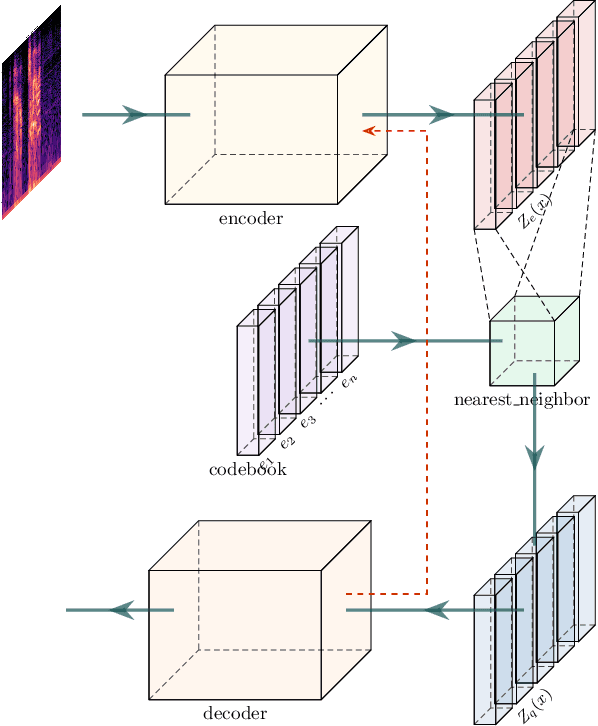
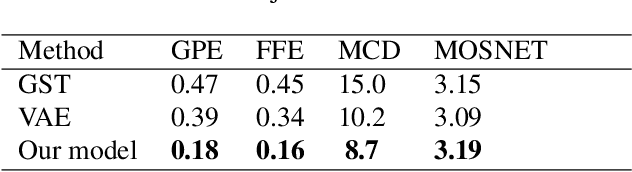
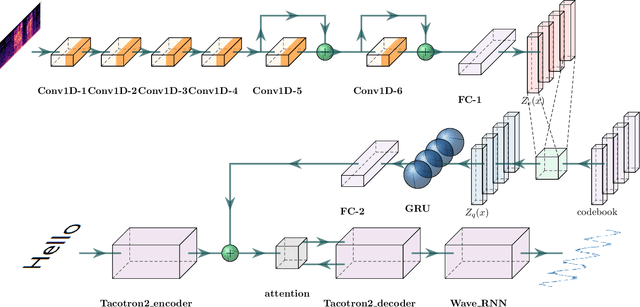
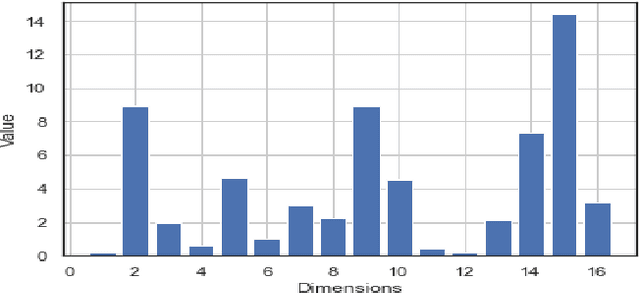
In this paper, we propose a novel prosody disentangle method for prosodic Text-to-Speech (TTS) model, which introduces the vector quantization (VQ) method to the auxiliary prosody encoder to obtain the decomposed prosody representations in an unsupervised manner. Rely on its advantages, the speaking styles, such as pitch, speaking velocity, local pitch variance, etc., are decomposed automatically into the latent quantize vectors. We also investigate the internal mechanism of VQ disentangle process by means of a latent variables counter and find that higher value dimensions usually represent prosody information. Experiments show that our model can control the speaking styles of synthesis results by directly manipulating the latent variables. The objective and subjective evaluations illustrated that our model outperforms the popular models.
Optimizing Shoulder to Shoulder: A Coordinated Sub-Band Fusion Model for Real-Time Full-Band Speech Enhancement
Mar 30, 2022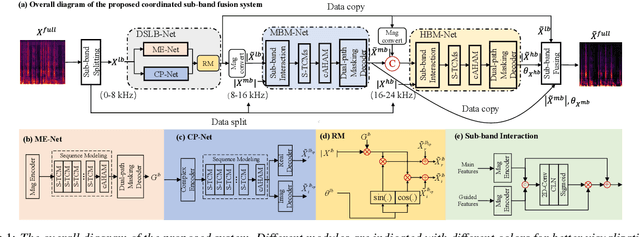
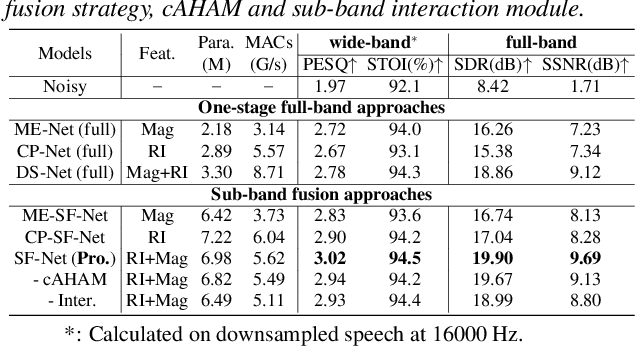
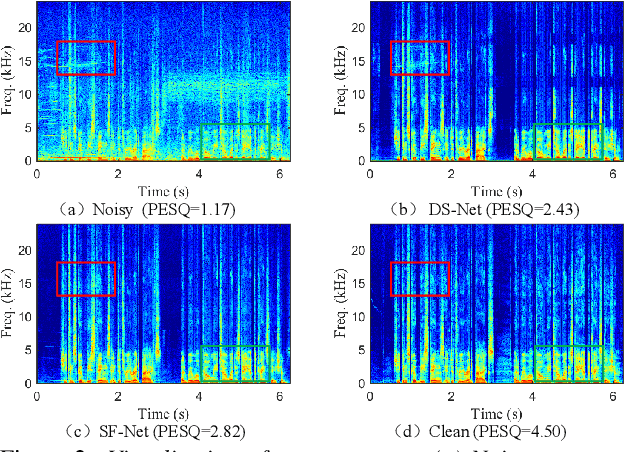
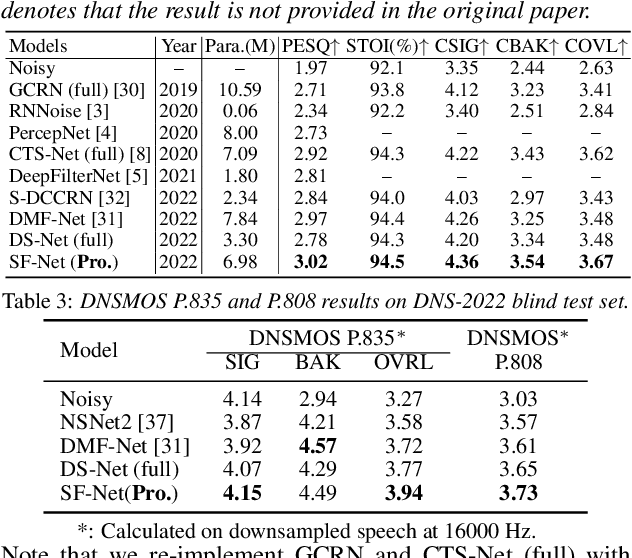
Due to the high computational complexity to model more frequency bands, it is still intractable to conduct real-time full-band speech enhancement based on deep neural networks. Recent studies typically utilize the compressed perceptually motivated features with relatively low frequency resolution to filter the full-band spectrum by one-stage networks, leading to limited speech quality improvements. In this paper, we propose a coordinated sub-band fusion network for full-band speech enhancement, which aims to recover the low- (0-8 kHz), middle- (8-16 kHz), and high-band (16-24 kHz) in a step-wise manner. Specifically, a dual-stream network is first pretrained to recover the low-band complex spectrum, and another two sub-networks are designed as the middle- and high-band noise suppressors in the magnitude-only domain. To fully capitalize on the information intercommunication, we employ a sub-band interaction module to provide external knowledge guidance across different frequency bands. Extensive experiments show that the proposed method yields consistent performance advantages over state-of-the-art full-band baselines.
DBT-Net: Dual-branch federative magnitude and phase estimation with attention-in-attention transformer for monaural speech enhancement
Feb 16, 2022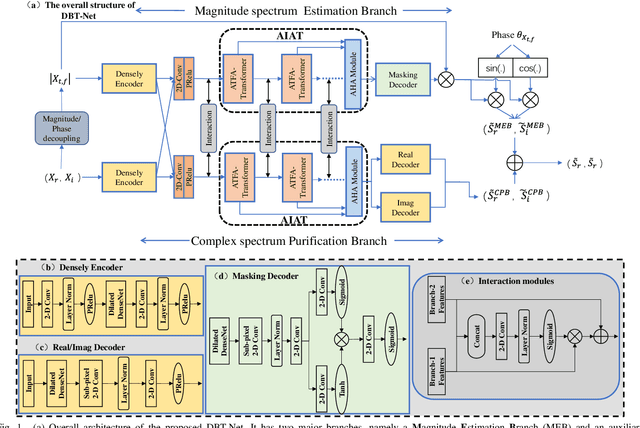
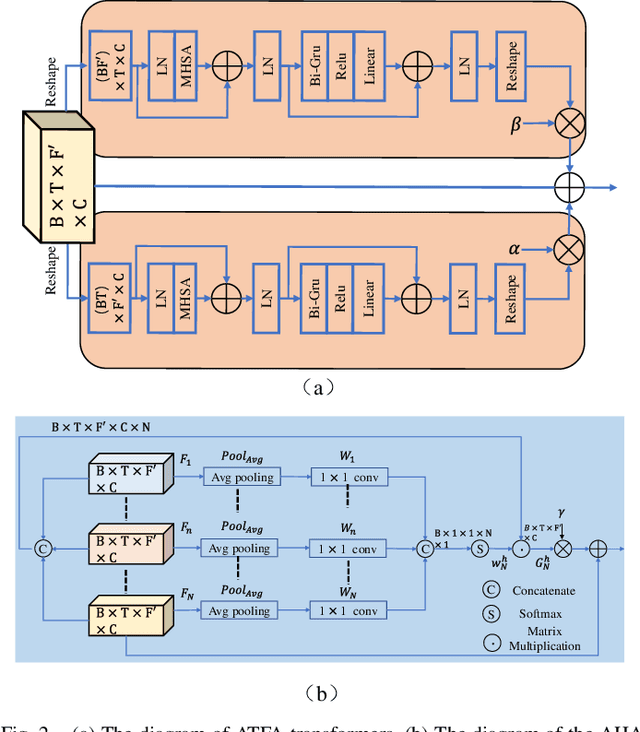
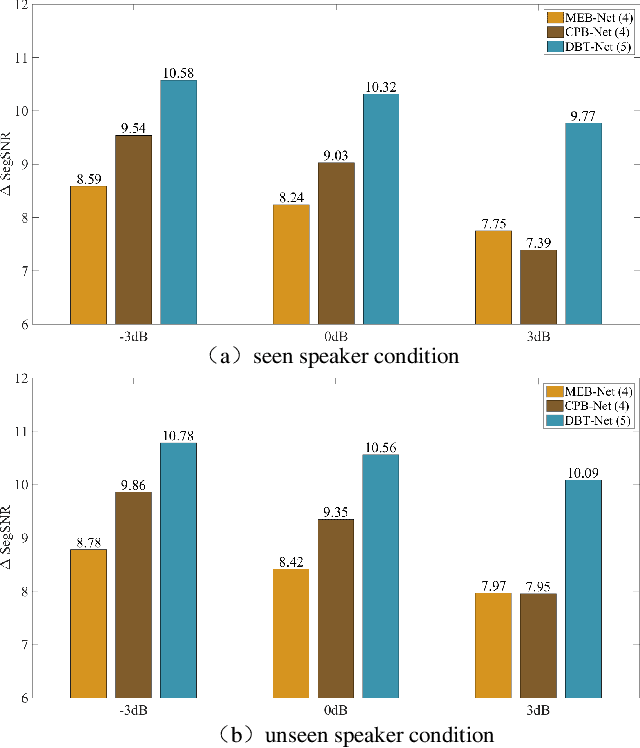
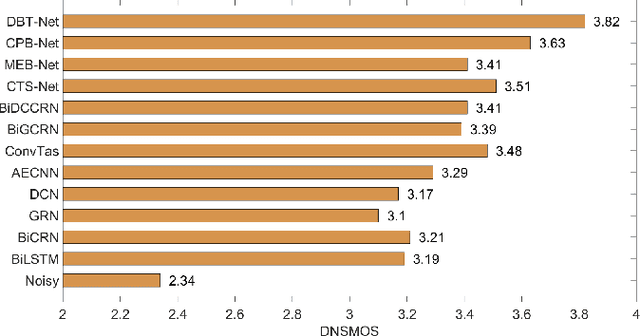
The decoupling-style concept begins to ignite in the speech enhancement area, which decouples the original complex spectrum estimation task into multiple easier sub-tasks (i.e., magnitude and phase), resulting in better performance and easier interpretability. In this paper, we propose a dual-branch federative magnitude and phase estimation framework, dubbed DBT-Net, for monaural speech enhancement, which aims at recovering the coarse- and fine-grained regions of the overall spectrum in parallel. From the complementary perspective, the magnitude estimation branch is designed to filter out dominant noise components in the magnitude domain, while the complex spectrum purification branch is elaborately designed to inpaint the missing spectral details and implicitly estimate the phase information in the complex domain. To facilitate the information flow between each branch, interaction modules are introduced to leverage features learned from one branch, so as to suppress the undesired parts and recover the missing components of the other branch. Instead of adopting the conventional RNNs and temporal convolutional networks for sequence modeling, we propose a novel attention-in-attention transformer-based network within each branch for better feature learning. More specially, it is composed of several adaptive spectro-temporal attention transformer-based modules and an adaptive hierarchical attention module, aiming to capture long-term time-frequency dependencies and further aggregate intermediate hierarchical contextual information. Comprehensive evaluations on the WSJ0-SI84 + DNS-Challenge and VoiceBank + DEMAND dataset demonstrate that the proposed approach consistently outperforms previous advanced systems and yields state-of-the-art performance in terms of speech quality and intelligibility.
Dual-branch Attention-In-Attention Transformer for single-channel speech enhancement
Nov 05, 2021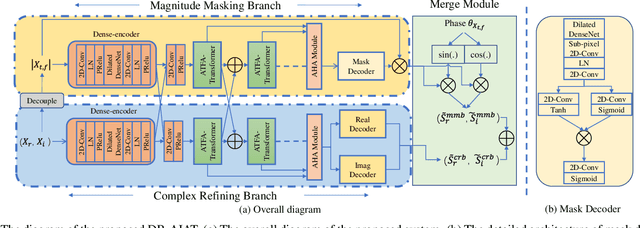
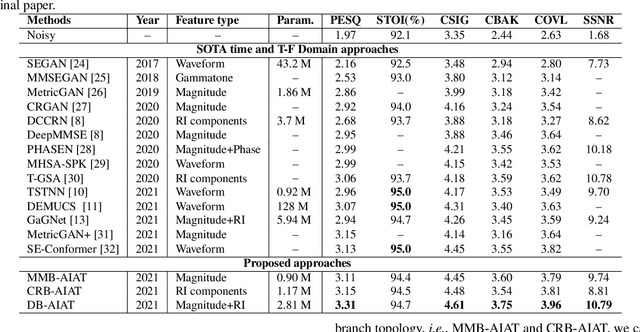
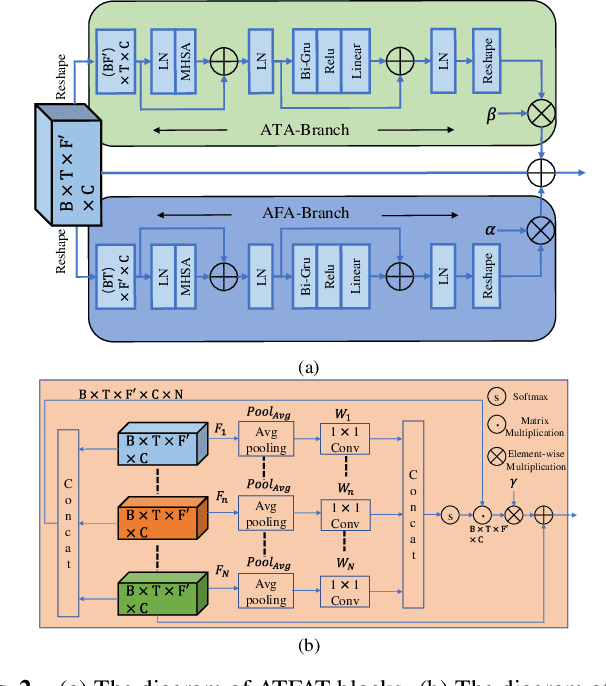
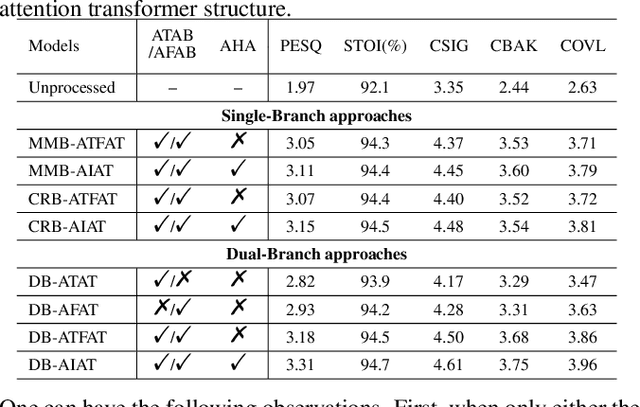
Curriculum learning begins to thrive in the speech enhancement area, which decouples the original spectrum estimation task into multiple easier sub-tasks to achieve better performance. Motivated by that, we propose a dual-branch attention-in-attention transformer dubbed DB-AIAT to handle both coarse- and fine-grained regions of the spectrum in parallel. From a complementary perspective, a magnitude masking branch is proposed to coarsely estimate the overall magnitude spectrum, and simultaneously a complex refining branch is elaborately designed to compensate for the missing spectral details and implicitly derive phase information. Within each branch, we propose a novel attention-in-attention transformer-based module to replace the conventional RNNs and temporal convolutional networks for temporal sequence modeling. Specifically, the proposed attention-in-attention transformer consists of adaptive temporal-frequency attention transformer blocks and an adaptive hierarchical attention module, aiming to capture long-term temporal-frequency dependencies and further aggregate global hierarchical contextual information. Experimental results on Voice Bank + DEMAND demonstrate that DB-AIAT yields state-of-the-art performance (e.g., 3.31 PESQ, 95.6% STOI and 10.79dB SSNR) over previous advanced systems with a relatively small model size (2.81M).
Joint magnitude estimation and phase recovery using Cycle-in-Cycle GAN for non-parallel speech enhancement
Oct 13, 2021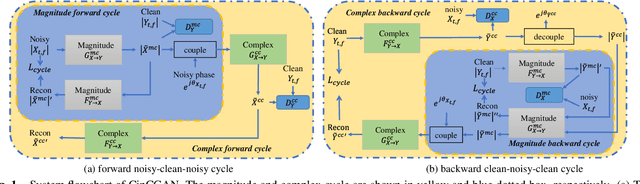

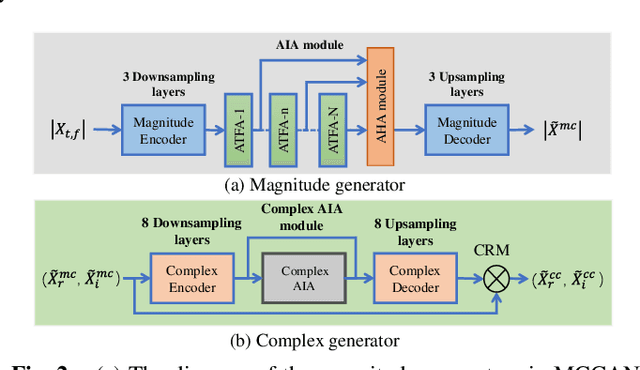

For the lack of adequate paired noisy-clean speech corpus in many real scenarios, non-parallel training is a promising task for DNN-based speech enhancement methods. However, because of the severe mismatch between input and target speech, many previous studies only focus on the magnitude spectrum estimation and remain the phase unaltered, resulting in the degraded speech quality under low signal-to-noise ratio conditions. To tackle this problem, we decouple the difficult target w.r.t. original spectrum optimization into spectral magnitude and phase, and a novel Cycle-in-Cycle generative adversarial network (dubbed CinCGAN) is proposed to jointly estimate the spectral magnitude and phase information stage by stage under unpaired data. In the first stage, we pretrain a magnitude CycleGAN to coarsely estimate the spectral magnitude of clean speech. In the second stage, we incorporate the pretrained CycleGAN in a complex-valued CycleGAN as a cycle-in-cycle structure to simultaneously recover phase information and refine the overall spectrum. Experimental results demonstrate that the proposed approach significantly outperforms previous baselines under non-parallel training. The evaluation on training the models with standard paired data also shows that CinCGAN achieves remarkable performance especially in reducing background noise and speech distortion.
A Two-stage Complex Network using Cycle-consistent Generative Adversarial Networks for Speech Enhancement
Sep 05, 2021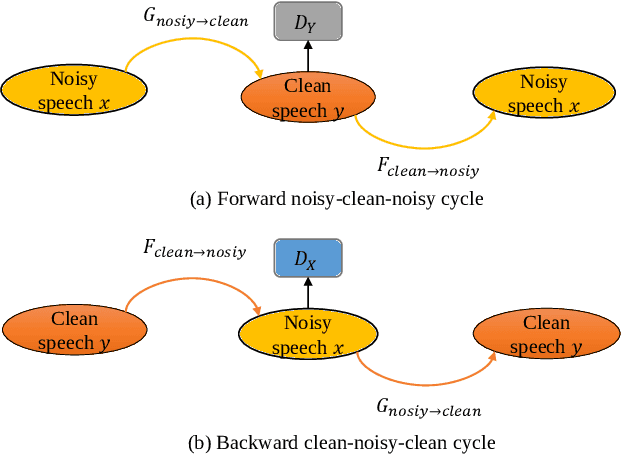
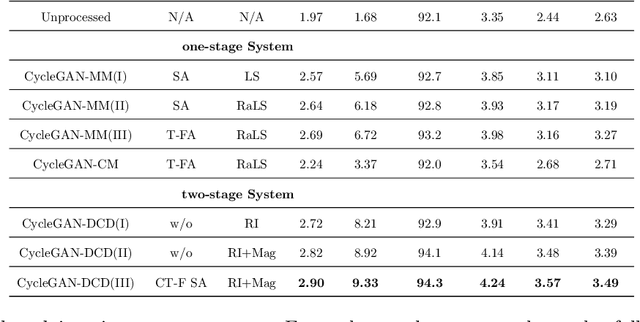
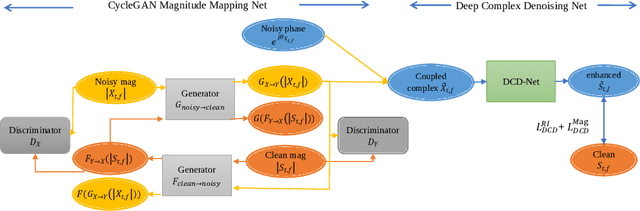
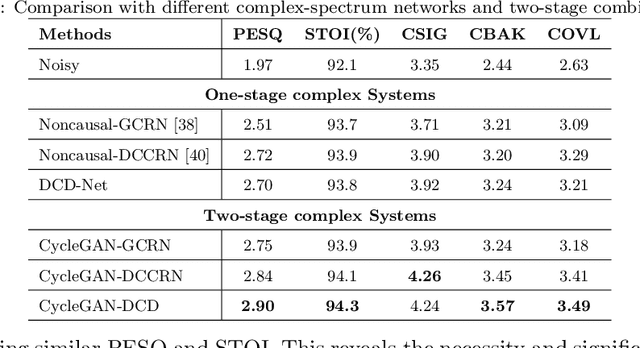
Cycle-consistent generative adversarial networks (CycleGAN) have shown their promising performance for speech enhancement (SE), while one intractable shortcoming of these CycleGAN-based SE systems is that the noise components propagate throughout the cycle and cannot be completely eliminated. Additionally, conventional CycleGAN-based SE systems only estimate the spectral magnitude, while the phase is unaltered. Motivated by the multi-stage learning concept, we propose a novel two-stage denoising system that combines a CycleGAN-based magnitude enhancing network and a subsequent complex spectral refining network in this paper. Specifically, in the first stage, a CycleGAN-based model is responsible for only estimating magnitude, which is subsequently coupled with the original noisy phase to obtain a coarsely enhanced complex spectrum. After that, the second stage is applied to further suppress the residual noise components and estimate the clean phase by a complex spectral mapping network, which is a pure complex-valued network composed of complex 2D convolution/deconvolution and complex temporal-frequency attention blocks. Experimental results on two public datasets demonstrate that the proposed approach consistently surpasses previous one-stage CycleGANs and other state-of-the-art SE systems in terms of various evaluation metrics, especially in background noise suppression.