 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Quantized Prosody Representation for Controllable Speech Synthesis
Paper and Code
Apr 07, 2022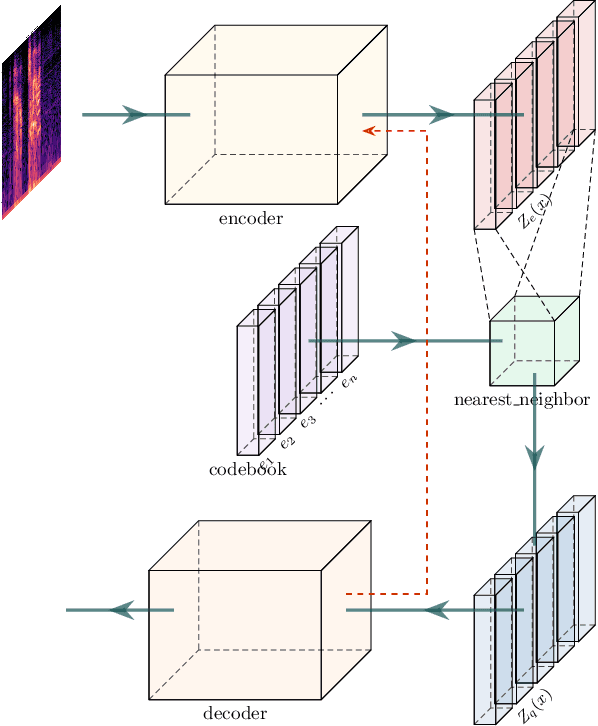
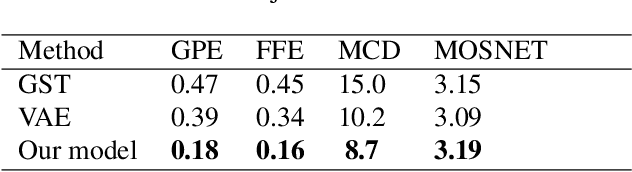
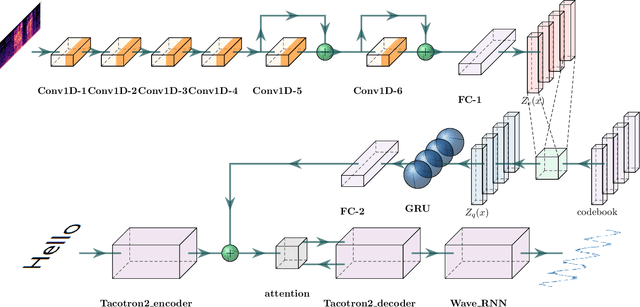
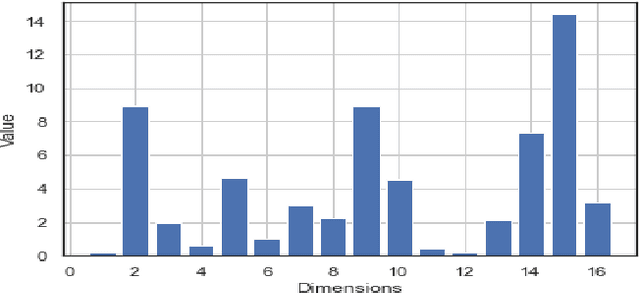
In this paper, we propose a novel prosody disentangle method for prosodic Text-to-Speech (TTS) model, which introduces the vector quantization (VQ) method to the auxiliary prosody encoder to obtain the decomposed prosody representations in an unsupervised manner. Rely on its advantages, the speaking styles, such as pitch, speaking velocity, local pitch variance, etc., are decomposed automatically into the latent quantize vectors. We also investigate the internal mechanism of VQ disentangle process by means of a latent variables counter and find that higher value dimensions usually represent prosody information. Experiments show that our model can control the speaking styles of synthesis results by directly manipulating the latent variables. The objective and subjective evaluations illustrated that our model outperforms the popular models.