 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Explicit Acoustic Evidence Perception in Audio LLMs for Speech Deepfake Detection
Jan 30, 2026Speech deepfake detection (SDD) focuses on identifying whether a given speech signal is genuine or has been synthetically generated. Existing audio large language model (LLM)-based methods excel in content understanding; however, their predictions are often biased toward semantically correlated cues, which results in fine-grained acoustic artifacts being overlooked during the decisionmaking process. Consequently, fake speech with natural semantics can bypass detectors despite harboring subtle acoustic anomalies; this suggests that the challenge stems not from the absence of acoustic data, but from its inadequate accessibility when semantic-dominant reasoning prevails. To address this issue, we investigate SDD within the audio LLM paradigm and introduce SDD with Auditory Perception-enhanced Audio Large Language Model (SDD-APALLM), an acoustically enhanced framework designed to explicitly expose fine-grained time-frequency evidence as accessible acoustic cues. By combining raw audio with structured spectrograms, the proposed framework empowers audio LLMs to more effectively capture subtle acoustic inconsistencies without compromising their semantic understanding. Experimental results indicate consistent gains in detection accuracy and robustness, especially in cases where semantic cues are misleading. Further analysis reveals that these improvements stem from a coordinated utilization of semantic and acoustic information, as opposed to simple modality aggregation.
Interpretable All-Type Audio Deepfake Detection with Audio LLMs via Frequency-Time Reinforcement Learning
Jan 06, 2026Recent advances in audio large language models (ALLMs) have made high-quality synthetic audio widely accessible, increasing the risk of malicious audio deepfakes across speech, environmental sounds, singing voice, and music. Real-world audio deepfake detection (ADD) therefore requires all-type detectors that generalize across heterogeneous audio and provide interpretable decisions. Given the strong multi-task generalization ability of ALLMs, we first investigate their performance on all-type ADD under both supervised fine-tuning (SFT) and reinforcement fine-tuning (RFT). However, SFT using only binary real/fake labels tends to reduce the model to a black-box classifier, sacrificing interpretability. Meanwhile, vanilla RFT under sparse supervision is prone to reward hacking and can produce hallucinated, ungrounded rationales. To address this, we propose an automatic annotation and polishing pipeline that constructs Frequency-Time structured chain-of-thought (CoT) rationales, producing ~340K cold-start demonstrations. Building on CoT data, we propose Frequency Time-Group Relative Policy Optimization (FT-GRPO), a two-stage training paradigm that cold-starts ALLMs with SFT and then applies GRPO under rule-based frequency-time constraints. Experiments demonstrate that FT-GRPO achieves state-of-the-art performance on all-type ADD while producing interpretable, FT-grounded rationales. The data and code are available online.
EnvSSLAM-FFN: Lightweight Layer-Fused System for ESDD 2026 Challenge
Dec 23, 2025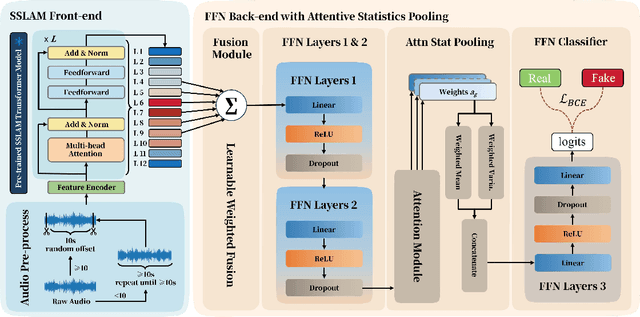
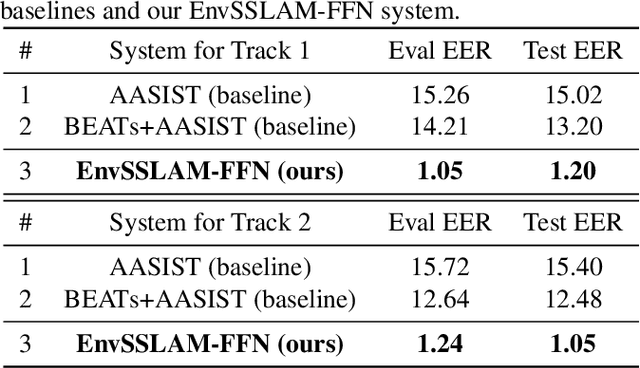
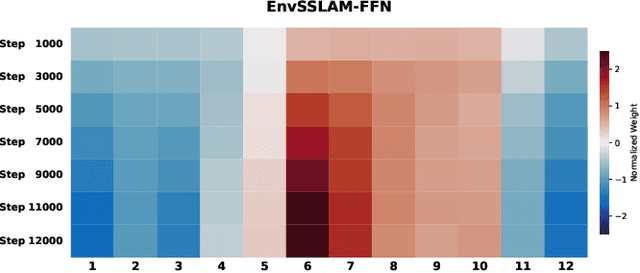
Recent advances in generative audio models have enabled high-fidelity environmental sound synthesis, raising serious concerns for audio security. The ESDD 2026 Challenge therefore addresses environmental sound deepfake detection under unseen generators (Track 1) and black-box low-resource detection (Track 2) conditions. We propose EnvSSLAM-FFN, which integrates a frozen SSLAM self-supervised encoder with a lightweight FFN back-end. To effectively capture spoofing artifacts under severe data imbalance, we fuse intermediate SSLAM representations from layers 4-9 and adopt a class-weighted training objective. Experimental results show that the proposed system consistently outperforms the official baselines on both tracks, achieving Test Equal Error Rates (EERs) of 1.20% and 1.05%, respectively.
Detect All-Type Deepfake Audio: Wavelet Prompt Tuning for Enhanced Auditory Perception
Apr 09, 2025



The rapid advancement of audio generation technologies has escalated the risks of malicious deepfake audio across speech, sound, singing voice, and music, threatening multimedia security and trust. While existing countermeasures (CMs) perform well in single-type audio deepfake detection (ADD), their performance declines in cross-type scenarios. This paper is dedicated to studying the alltype ADD task. We are the first to comprehensively establish an all-type ADD benchmark to evaluate current CMs, incorporating cross-type deepfake detection across speech, sound, singing voice, and music. Then, we introduce the prompt tuning self-supervised learning (PT-SSL) training paradigm, which optimizes SSL frontend by learning specialized prompt tokens for ADD, requiring 458x fewer trainable parameters than fine-tuning (FT). Considering the auditory perception of different audio types,we propose the wavelet prompt tuning (WPT)-SSL method to capture type-invariant auditory deepfake information from the frequency domain without requiring additional training parameters, thereby enhancing performance over FT in the all-type ADD task. To achieve an universally CM, we utilize all types of deepfake audio for co-training. Experimental results demonstrate that WPT-XLSR-AASIST achieved the best performance, with an average EER of 3.58% across all evaluation sets. The code is available online.
Temporal Variability and Multi-Viewed Self-Supervised Representations to Tackle the ASVspoof5 Deepfake Challenge
Aug 13, 2024
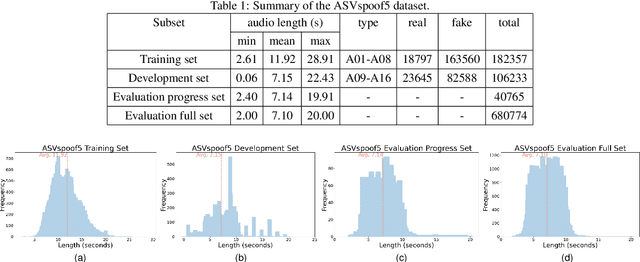
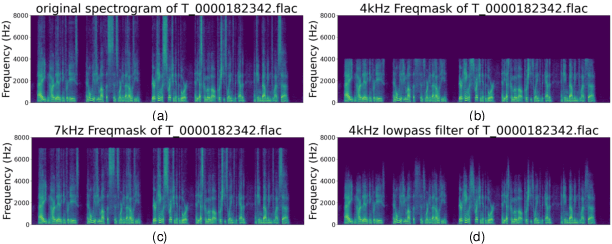
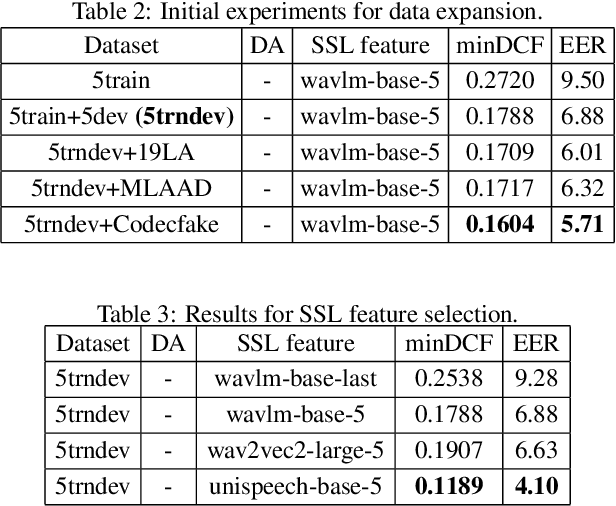
ASVspoof5, the fifth edition of the ASVspoof series, is one of the largest global audio security challenges. It aims to advance the development of countermeasure (CM) to discriminate bonafide and spoofed speech utterances. In this paper, we focus on addressing the problem of open-domain audio deepfake detection, which corresponds directly to the ASVspoof5 Track1 open condition. At first, we comprehensively investigate various CM on ASVspoof5, including data expansion, data augmentation, and self-supervised learning (SSL) features. Due to the high-frequency gaps characteristic of the ASVspoof5 dataset, we introduce Frequency Mask, a data augmentation method that masks specific frequency bands to improve CM robustness. Combining various scale of temporal information with multiple SSL features, our experiments achieved a minDCF of 0.0158 and an EER of 0.55% on the ASVspoof 5 Track 1 evaluation progress set.
The Codecfake Dataset and Countermeasures for the Universally Detection of Deepfake Audio
May 08, 2024



With the proliferation of Audio Language Model (ALM) based deepfake audio, there is an urgent need for effective detection methods. Unlike traditional deepfake audio generation, which often involves multi-step processes culminating in vocoder usage, ALM directly utilizes neural codec methods to decode discrete codes into audio. Moreover, driven by large-scale data, ALMs exhibit remarkable robustness and versatility, posing a significant challenge to current audio deepfake detection (ADD) models. To effectively detect ALM-based deepfake audio, we focus on the mechanism of the ALM-based audio generation method, the conversion from neural codec to waveform. We initially construct the Codecfake dataset, an open-source large-scale dataset, including two languages, millions of audio samples, and various test conditions, tailored for ALM-based audio detection. Additionally, to achieve universal detection of deepfake audio and tackle domain ascent bias issue of original SAM, we propose the CSAM strategy to learn a domain balanced and generalized minima. Experiment results demonstrate that co-training on Codecfake dataset and vocoded dataset with CSAM strategy yield the lowest average Equal Error Rate (EER) of 0.616% across all test conditions compared to baseline models.
An Efficient Temporary Deepfake Location Approach Based Embeddings for Partially Spoofed Audio Detection
Sep 06, 2023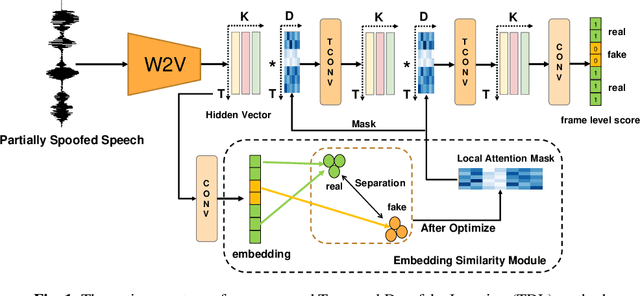
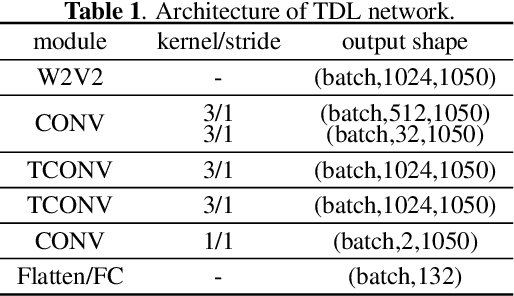
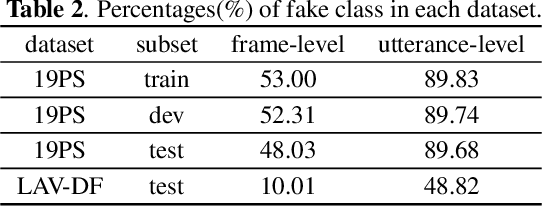
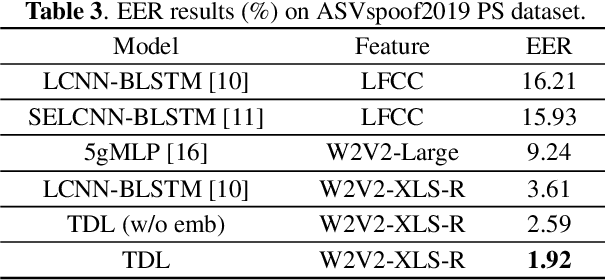
Partially spoofed audio detection is a challenging task, lying in the need to accurately locate the authenticity of audio at the frame level. To address this issue, we propose a fine-grained partially spoofed audio detection method, namely Temporal Deepfake Location (TDL), which can effectively capture information of both features and locations. Specifically, our approach involves two novel parts: embedding similarity module and temporal convolution operation. To enhance the identification between the real and fake features, the embedding similarity module is designed to generate an embedding space that can separate the real frames from fake frames. To effectively concentrate on the position information, temporal convolution operation is proposed to calculate the frame-specific similarities among neighboring frames, and dynamically select informative neighbors to convolution. Extensive experiments show that our method outperform baseline models in ASVspoof2019 Partial Spoof dataset and demonstrate superior performance even in the crossdataset scenario. The code is released online.
FSD: An Initial Chinese Dataset for Fake Song Detection
Sep 06, 2023



Singing voice synthesis and singing voice conversion have significantly advanced, revolutionizing musical experiences. However, the rise of "Deepfake Songs" generated by these technologies raises concerns about authenticity. Unlike Audio DeepFake Detection (ADD), the field of song deepfake detection lacks specialized datasets or methods for song authenticity verification. In this paper, we initially construct a Chinese Fake Song Detection (FSD) dataset to investigate the field of song deepfake detection. The fake songs in the FSD dataset are generated by five state-of-the-art singing voice synthesis and singing voice conversion methods. Our initial experiments on FSD revealed the ineffectiveness of existing speech-trained ADD models for the task of song deepFake detection. Thus, we employ the FSD dataset for the training of ADD models. We subsequently evaluate these models under two scenarios: one with the original songs and another with separated vocal tracks. Experiment results show that song-trained ADD models exhibit a 38.58% reduction in average equal error rate compared to speech-trained ADD models on the FSD test set.