 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Variability and Multi-Viewed Self-Supervised Representations to Tackle the ASVspoof5 Deepfake Challenge
Paper and Code
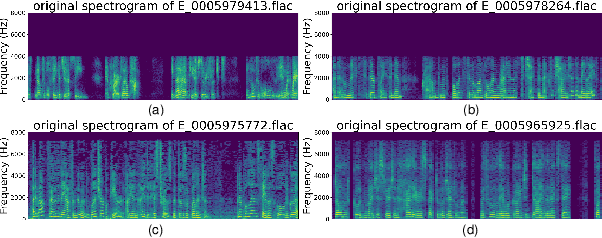
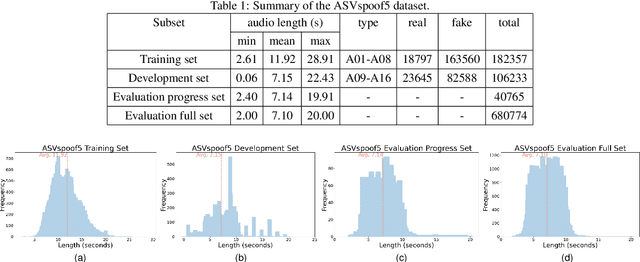
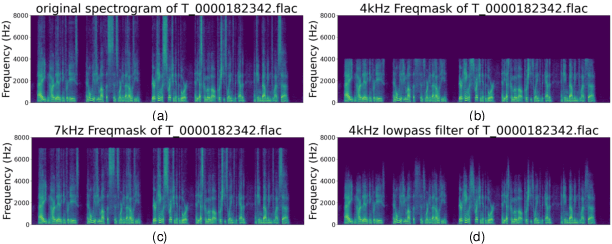
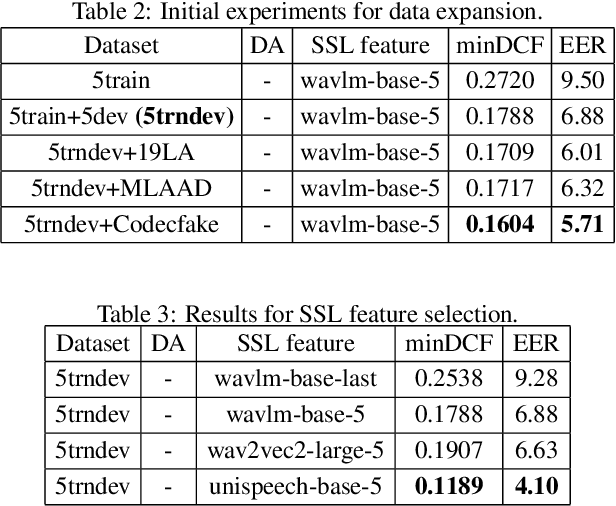
ASVspoof5, the fifth edition of the ASVspoof series, is one of the largest global audio security challenges. It aims to advance the development of countermeasure (CM) to discriminate bonafide and spoofed speech utterances. In this paper, we focus on addressing the problem of open-domain audio deepfake detection, which corresponds directly to the ASVspoof5 Track1 open condition. At first, we comprehensively investigate various CM on ASVspoof5, including data expansion, data augmentation, and self-supervised learning (SSL) features. Due to the high-frequency gaps characteristic of the ASVspoof5 dataset, we introduce Frequency Mask, a data augmentation method that masks specific frequency bands to improve CM robustness. Combining various scale of temporal information with multiple SSL features, our experiments achieved a minDCF of 0.0158 and an EER of 0.55% on the ASVspoof 5 Track 1 evaluation progress set.