 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArray2BR: An End-to-End Noise-immune Binaural Audio Synthesis from Microphone-array Signals
Oct 08, 2024



Telepresence technology aims to provide an immersive virtual presence for remote conference applications, and it is extremely important to synthesize high-quality binaural audio signals for this aim. Because the ambient noise is often inevitable in practical application scenarios, it is highly desired that binaural audio signals without noise can be obtained from microphone-array signals directly. For this purpose, this paper proposes a new end-to-end noise-immune binaural audio synthesis framework from microphone-array signals, abbreviated as Array2BR, and experimental results show that binaural cues can be correctly mapped and noise can be well suppressed simultaneously using the proposed framework. Compared with existing methods, the proposed method achieved better performance in terms of both objective and subjective metric scores.
DBT-Net: Dual-branch federative magnitude and phase estimation with attention-in-attention transformer for monaural speech enhancement
Feb 16, 2022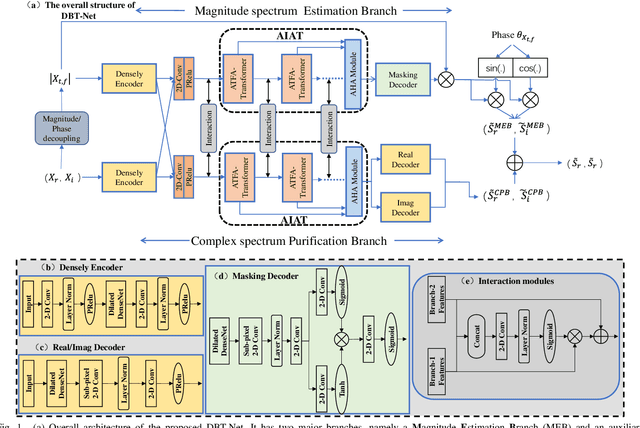
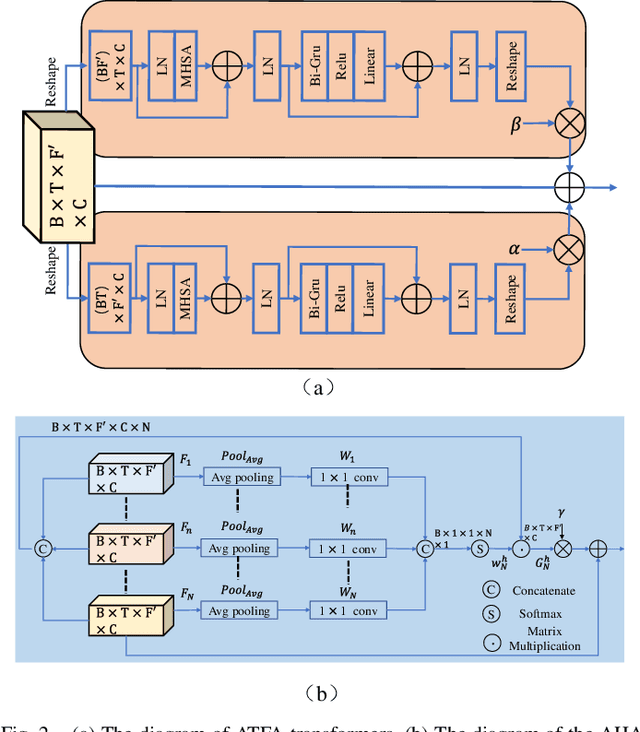
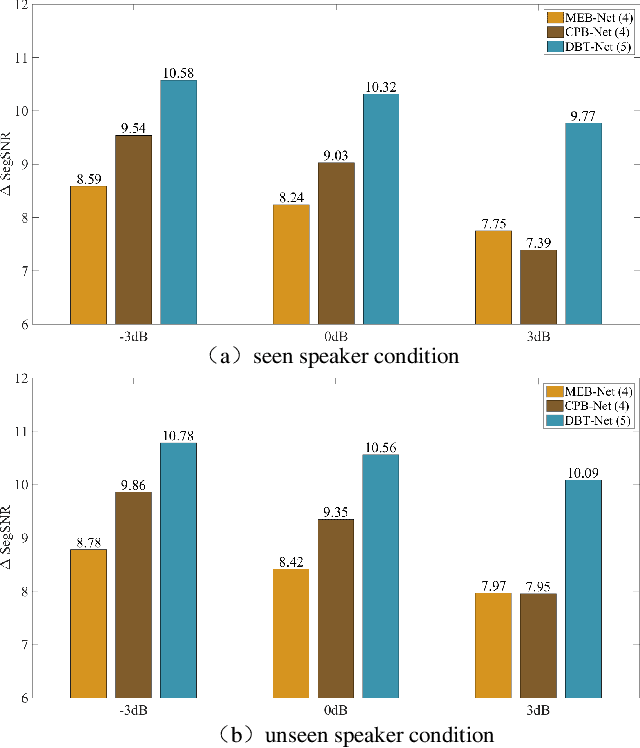
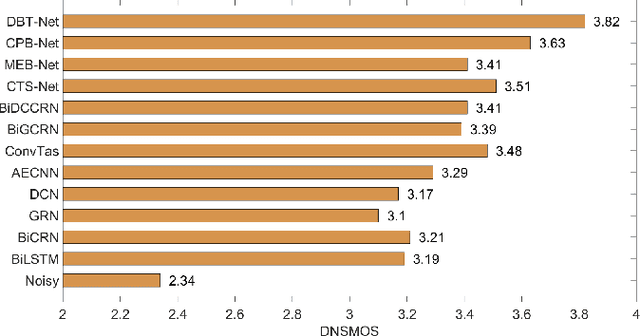
The decoupling-style concept begins to ignite in the speech enhancement area, which decouples the original complex spectrum estimation task into multiple easier sub-tasks (i.e., magnitude and phase), resulting in better performance and easier interpretability. In this paper, we propose a dual-branch federative magnitude and phase estimation framework, dubbed DBT-Net, for monaural speech enhancement, which aims at recovering the coarse- and fine-grained regions of the overall spectrum in parallel. From the complementary perspective, the magnitude estimation branch is designed to filter out dominant noise components in the magnitude domain, while the complex spectrum purification branch is elaborately designed to inpaint the missing spectral details and implicitly estimate the phase information in the complex domain. To facilitate the information flow between each branch, interaction modules are introduced to leverage features learned from one branch, so as to suppress the undesired parts and recover the missing components of the other branch. Instead of adopting the conventional RNNs and temporal convolutional networks for sequence modeling, we propose a novel attention-in-attention transformer-based network within each branch for better feature learning. More specially, it is composed of several adaptive spectro-temporal attention transformer-based modules and an adaptive hierarchical attention module, aiming to capture long-term time-frequency dependencies and further aggregate intermediate hierarchical contextual information. Comprehensive evaluations on the WSJ0-SI84 + DNS-Challenge and VoiceBank + DEMAND dataset demonstrate that the proposed approach consistently outperforms previous advanced systems and yields state-of-the-art performance in terms of speech quality and intelligibility.
Low-latency Monaural Speech Enhancement with Deep Filter-bank Equalizer
Feb 14, 2022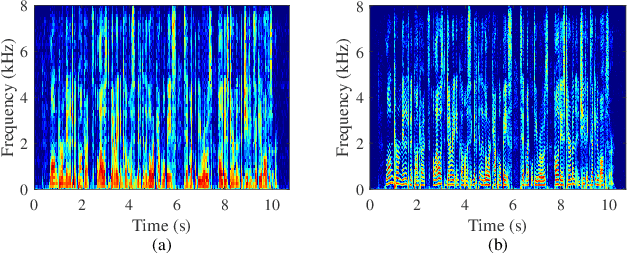

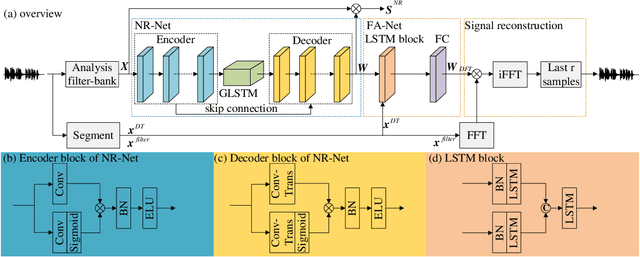
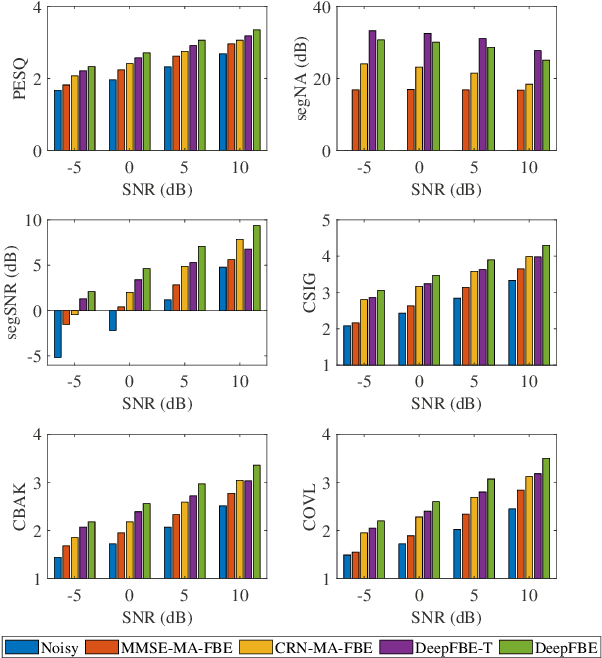
It is highly desirable that speech enhancement algorithms can achieve good performance while keeping low latency for many applications, such as digital hearing aids, acoustically transparent hearing devices, and public address systems. To improve the performance of traditional low-latency speech enhancement algorithms, a deep filter-bank equalizer (FBE) framework was proposed, which integrated a deep learning-based subband noise reduction network with a deep learning-based shortened digital filter mapping network. In the first network, a deep learning model was trained with a controllable small frame shift to satisfy the low-latency demand, i.e., $\le$ 4 ms, so as to obtain (complex) subband gains, which could be regarded as an adaptive digital filter in each frame. In the second network, to reduce the latency, this adaptive digital filter was implicitly shortened by a deep learning-based framework, and was then applied to noisy speech to reconstruct the enhanced speech without the overlap-add method. Experimental results on the WSJ0-SI84 corpus indicated that the proposed deep FBE with only 4-ms latency achieved much better performance than traditional low-latency speech enhancement algorithms in terms of the indices such as PESQ, STOI, and the amount of noise reduction.