 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBT-Net: Dual-branch federative magnitude and phase estimation with attention-in-attention transformer for monaural speech enhancement
Paper and Code
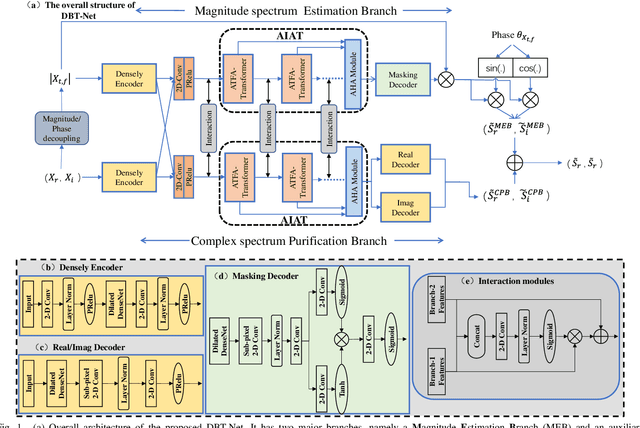
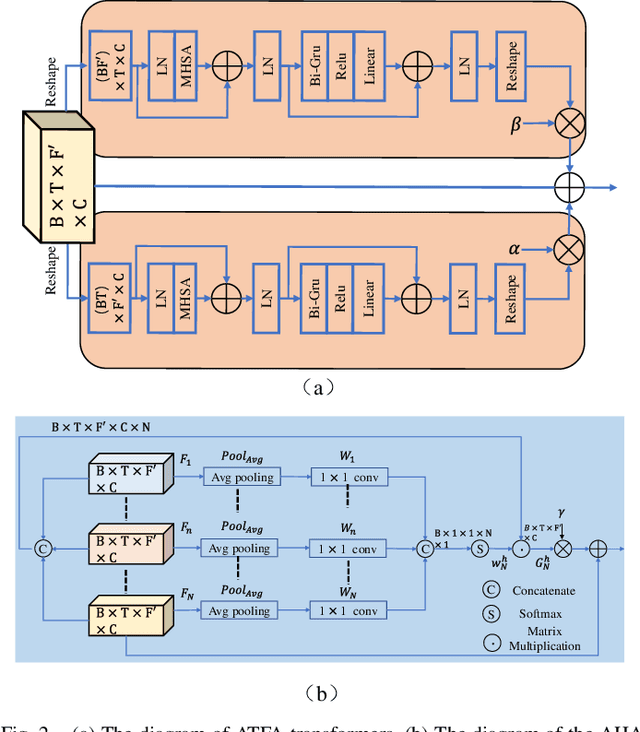
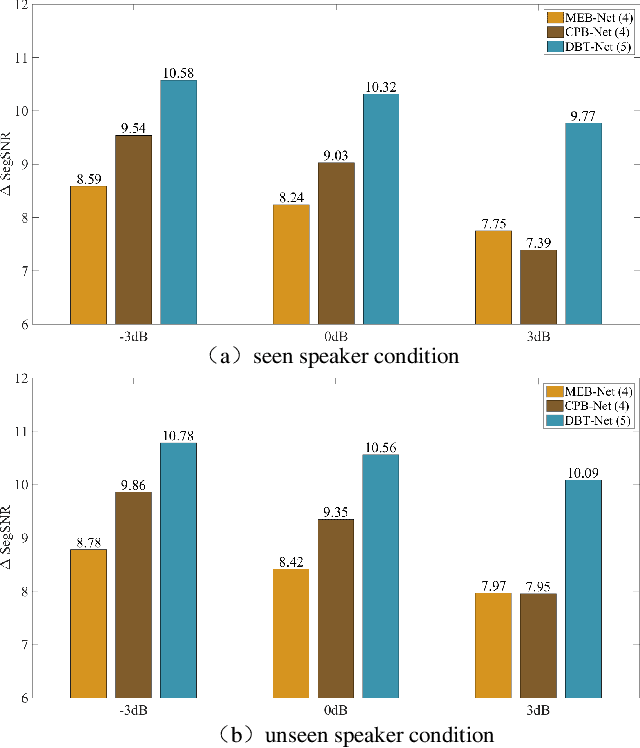
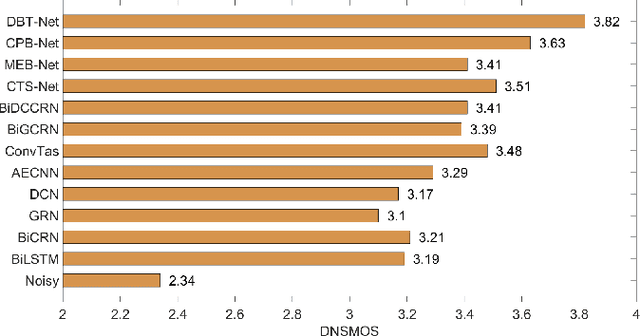
The decoupling-style concept begins to ignite in the speech enhancement area, which decouples the original complex spectrum estimation task into multiple easier sub-tasks (i.e., magnitude and phase), resulting in better performance and easier interpretability. In this paper, we propose a dual-branch federative magnitude and phase estimation framework, dubbed DBT-Net, for monaural speech enhancement, which aims at recovering the coarse- and fine-grained regions of the overall spectrum in parallel. From the complementary perspective, the magnitude estimation branch is designed to filter out dominant noise components in the magnitude domain, while the complex spectrum purification branch is elaborately designed to inpaint the missing spectral details and implicitly estimate the phase information in the complex domain. To facilitate the information flow between each branch, interaction modules are introduced to leverage features learned from one branch, so as to suppress the undesired parts and recover the missing components of the other branch. Instead of adopting the conventional RNNs and temporal convolutional networks for sequence modeling, we propose a novel attention-in-attention transformer-based network within each branch for better feature learning. More specially, it is composed of several adaptive spectro-temporal attention transformer-based modules and an adaptive hierarchical attention module, aiming to capture long-term time-frequency dependencies and further aggregate intermediate hierarchical contextual information. Comprehensive evaluations on the WSJ0-SI84 + DNS-Challenge and VoiceBank + DEMAND dataset demonstrate that the proposed approach consistently outperforms previous advanced systems and yields state-of-the-art performance in terms of speech quality and intelligibility.