 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-branch Attention-In-Attention Transformer for single-channel speech enhancement
Nov 05, 2021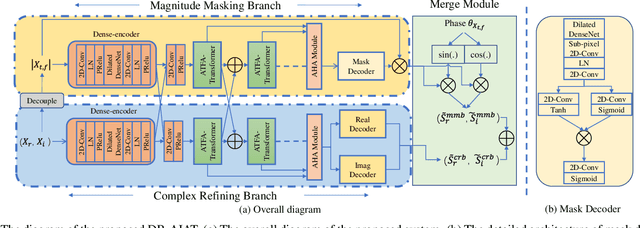
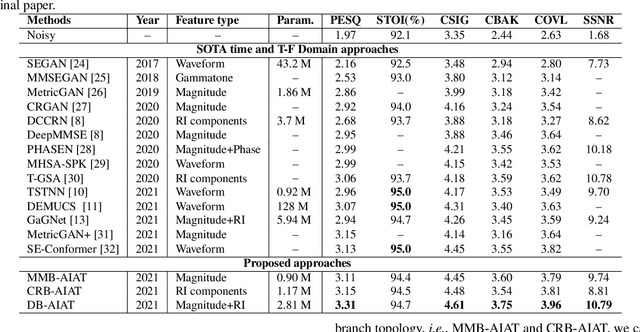
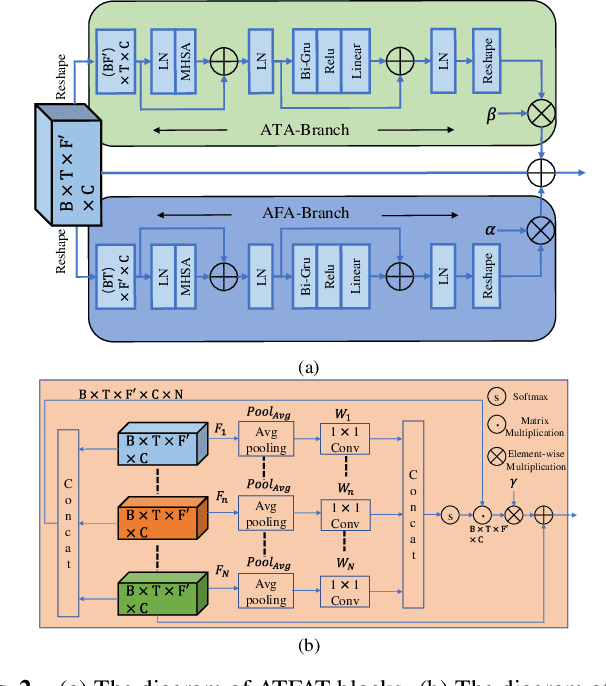
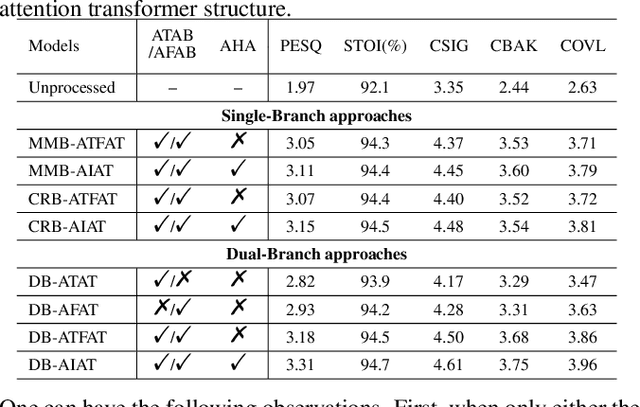
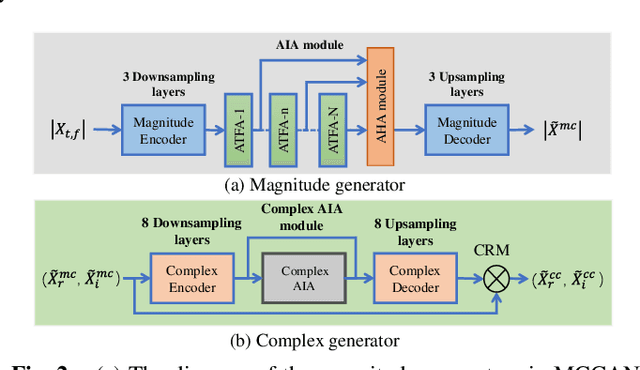
Curriculum learning begins to thrive in the speech enhancement area, which decouples the original spectrum estimation task into multiple easier sub-tasks to achieve better performance. Motivated by that, we propose a dual-branch attention-in-attention transformer dubbed DB-AIAT to handle both coarse- and fine-grained regions of the spectrum in parallel. From a complementary perspective, a magnitude masking branch is proposed to coarsely estimate the overall magnitude spectrum, and simultaneously a complex refining branch is elaborately designed to compensate for the missing spectral details and implicitly derive phase information. Within each branch, we propose a novel attention-in-attention transformer-based module to replace the conventional RNNs and temporal convolutional networks for temporal sequence modeling. Specifically, the proposed attention-in-attention transformer consists of adaptive temporal-frequency attention transformer blocks and an adaptive hierarchical attention module, aiming to capture long-term temporal-frequency dependencies and further aggregate global hierarchical contextual information. Experimental results on Voice Bank + DEMAND demonstrate that DB-AIAT yields state-of-the-art performance (e.g., 3.31 PESQ, 95.6% STOI and 10.79dB SSNR) over previous advanced systems with a relatively small model size (2.81M).
Joint magnitude estimation and phase recovery using Cycle-in-Cycle GAN for non-parallel speech enhancement
Oct 13, 2021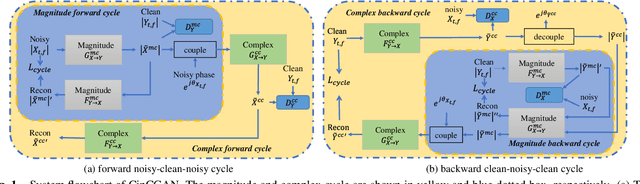


For the lack of adequate paired noisy-clean speech corpus in many real scenarios, non-parallel training is a promising task for DNN-based speech enhancement methods. However, because of the severe mismatch between input and target speech, many previous studies only focus on the magnitude spectrum estimation and remain the phase unaltered, resulting in the degraded speech quality under low signal-to-noise ratio conditions. To tackle this problem, we decouple the difficult target w.r.t. original spectrum optimization into spectral magnitude and phase, and a novel Cycle-in-Cycle generative adversarial network (dubbed CinCGAN) is proposed to jointly estimate the spectral magnitude and phase information stage by stage under unpaired data. In the first stage, we pretrain a magnitude CycleGAN to coarsely estimate the spectral magnitude of clean speech. In the second stage, we incorporate the pretrained CycleGAN in a complex-valued CycleGAN as a cycle-in-cycle structure to simultaneously recover phase information and refine the overall spectrum. Experimental results demonstrate that the proposed approach significantly outperforms previous baselines under non-parallel training. The evaluation on training the models with standard paired data also shows that CinCGAN achieves remarkable performance especially in reducing background noise and speech distortion.
Iterative Utterance Segmentation for Neural Semantic Parsing
Dec 13, 2020
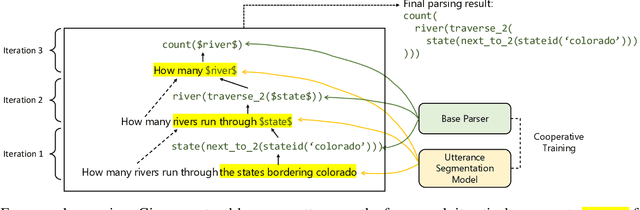

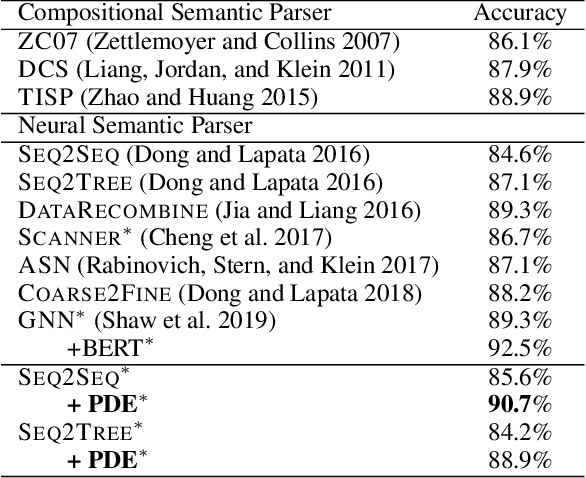
Neural semantic parsers usually fail to parse long and complex utterances into correct meaning representations, due to the lack of exploiting the principle of compositionality. To address this issue, we present a novel framework for boosting neural semantic parsers via iterative utterance segmentation. Given an input utterance, our framework iterates between two neural modules: a segmenter for segmenting a span from the utterance, and a parser for mapping the span into a partial meaning representation. Then, these intermediate parsing results are composed into the final meaning representation. One key advantage is that this framework does not require any handcraft templates or additional labeled data for utterance segmentation: we achieve this through proposing a novel training method, in which the parser provides pseudo supervision for the segmenter. Experiments on Geo, ComplexWebQuestions, and Formulas show that our framework can consistently improve performances of neural semantic parsers in different domains. On data splits that require compositional generalization, our framework brings significant accuracy gains: Geo 63.1 to 81.2, Formulas 59.7 to 72.7, ComplexWebQuestions 27.1 to 56.3.
Revisiting Iterative Back-Translation from the Perspective of Compositional Generalization
Dec 08, 2020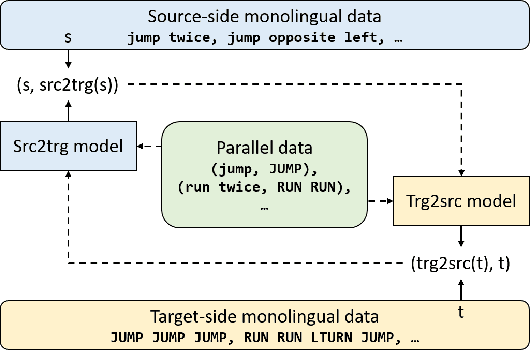


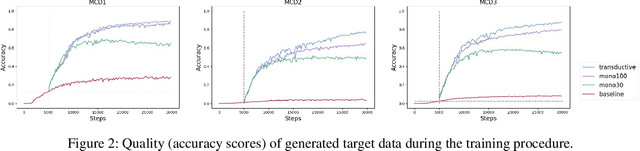
Human intelligence exhibits compositional generalization (i.e., the capacity to understand and produce unseen combinations of seen components), but current neural seq2seq models lack such ability. In this paper, we revisit iterative back-translation, a simple yet effective semi-supervised method, to investigate whether and how it can improve compositional generalization. In this work: (1) We first empirically show that iterative back-translation substantially improves the performance on compositional generalization benchmarks (CFQ and SCAN). (2) To understand why iterative back-translation is useful, we carefully examine the performance gains and find that iterative back-translation can increasingly correct errors in pseudo-parallel data. (3) To further encourage this mechanism, we propose curriculum iterative back-translation, which better improves the quality of pseudo-parallel data, thus further improving the performance.
Incorporate Semantic Structures into Machine Translation Evaluation via UCCA
Oct 22, 2020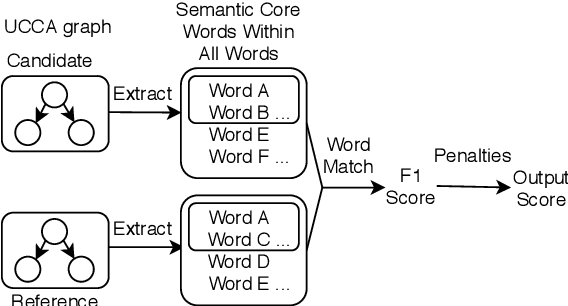

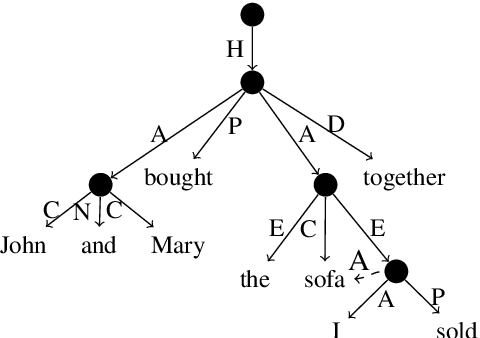

Copying mechanism has been commonly used in neural paraphrasing networks and other text generation tasks, in which some important words in the input sequence are preserved in the output sequence. Similarly, in machine translation, we notice that there are certain words or phrases appearing in all good translations of one source text, and these words tend to convey important semantic information. Therefore, in this work, we define words carrying important semantic meanings in sentences as semantic core words. Moreover, we propose an MT evaluation approach named Semantically Weighted Sentence Similarity (SWSS). It leverages the power of UCCA to identify semantic core words, and then calculates sentence similarity scores on the overlap of semantic core words. Experimental results show that SWSS can consistently improve the performance of popular MT evaluation metrics which are based on lexical similarity.
Hierarchical Poset Decoding for Compositional Generalization in Language
Oct 15, 2020



We formalize human language understanding as a structured prediction task where the output is a partially ordered set (poset). Current encoder-decoder architectures do not take the poset structure of semantics into account properly, thus suffering from poor compositional generalization ability. In this paper, we propose a novel hierarchical poset decoding paradigm for compositional generalization in language. Intuitively: (1) the proposed paradigm enforces partial permutation invariance in semantics, thus avoiding overfitting to bias ordering information; (2) the hierarchical mechanism allows to capture high-level structures of posets. We evaluate our proposed decoder on Compositional Freebase Questions (CFQ), a large and realistic natural language question answering dataset that is specifically designed to measure compositional generalization. Results show that it outperforms current decoders.
Fact-aware Sentence Split and Rephrase with Permutation Invariant Training
Feb 03, 2020



Sentence Split and Rephrase aims to break down a complex sentence into several simple sentences with its meaning preserved. Previous studies tend to address the issue by seq2seq learning from parallel sentence pairs, which takes a complex sentence as input and sequentially generates a series of simple sentences. However, the conventional seq2seq learning has two limitations for this task: (1) it does not take into account the facts stated in the long sentence; As a result, the generated simple sentences may miss or inaccurately state the facts in the original sentence. (2) The order variance of the simple sentences to be generated may confuse the seq2seq model during training because the simple sentences derived from the long source sentence could be in any order. To overcome the challenges, we first propose the Fact-aware Sentence Encoding, which enables the model to learn facts from the long sentence and thus improves the precision of sentence split; then we introduce Permutation Invariant Training to alleviate the effects of order variance in seq2seq learning for this task. Experiments on the WebSplit-v1.0 benchmark dataset show that our approaches can largely improve the performance over the previous seq2seq learning approaches. Moreover, an extrinsic evaluation on oie-benchmark verifies the effectiveness of our approaches by an observation that splitting long sentences with our state-of-the-art model as preprocessing is helpful for improving OpenIE performance.