 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Learning-based Vasculature Extraction for Single-Scan Optical Coherence Tomography Angiography
May 03, 2023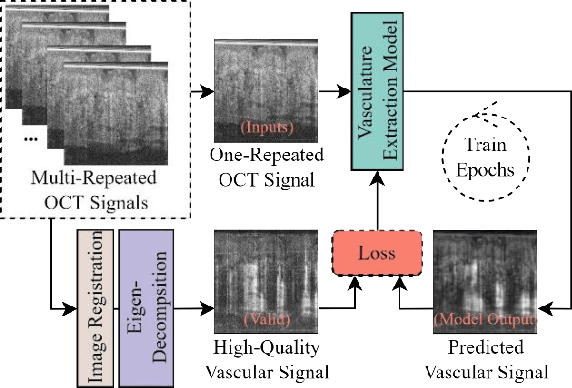
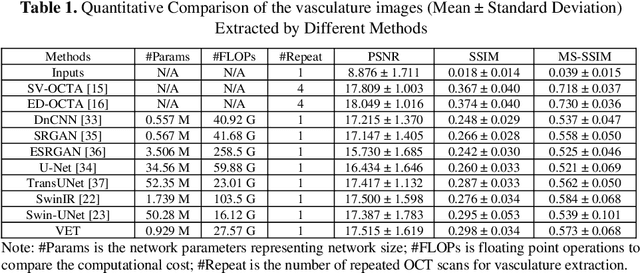

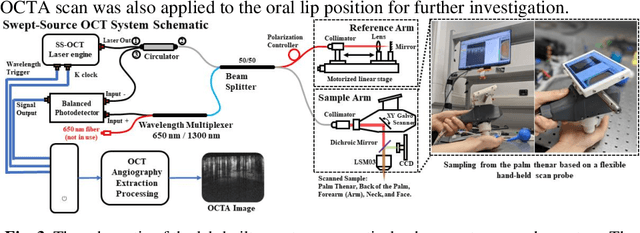
Optical coherence tomography angiography (OCTA) is a non-invasive imaging modality that extends the functionality of OCT by extracting moving red blood cell signals from surrounding static biological tissues. OCTA has emerged as a valuable tool for analyzing skin microvasculature, enabling more accurate diagnosis and treatment monitoring. Most existing OCTA extraction algorithms, such as speckle variance (SV)- and eigen-decomposition (ED)-OCTA, implement a larger number of repeated (NR) OCT scans at the same position to produce high-quality angiography images. However, a higher NR requires a longer data acquisition time, leading to more unpredictable motion artifacts. In this study, we propose a vasculature extraction pipeline that uses only one-repeated OCT scan to generate OCTA images. The pipeline is based on the proposed Vasculature Extraction Transformer (VET), which leverages convolutional projection to better learn the spatial relationships between image patches. In comparison to OCTA images obtained via the SV-OCTA (PSNR: 17.809) and ED-OCTA (PSNR: 18.049) using four-repeated OCT scans, OCTA images extracted by VET exhibit moderate quality (PSNR: 17.515) and higher image contrast while reducing the required data acquisition time from ~8 s to ~2 s. Based on visual observations, the proposed VET outperforms SV and ED algorithms when using neck and face OCTA data in areas that are challenging to scan. This study represents that the VET has the capacity to extract vascularture images from a fast one-repeated OCT scan, facilitating accurate diagnosis for patients.