 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisAidMath: Benchmarking Visual-Aided Mathematical Reasoning
Oct 30, 2024



Although previous research on large language models (LLMs) and large multi-modal models (LMMs) has systematically explored mathematical problem-solving (MPS) within visual contexts, the analysis of how these models process visual information during problem-solving remains insufficient. To address this gap, we present VisAidMath, a benchmark for evaluating the MPS process related to visual information. We follow a rigorous data curation pipeline involving both automated processes and manual annotations to ensure data quality and reliability. Consequently, this benchmark includes 1,200 challenging problems from various mathematical branches, vision-aid formulations, and difficulty levels, collected from diverse sources such as textbooks, examination papers, and Olympiad problems. Based on the proposed benchmark, we conduct comprehensive evaluations on ten mainstream LLMs and LMMs, highlighting deficiencies in the visual-aided reasoning process. For example, GPT-4V only achieves 45.33% accuracy in the visual-aided reasoning task, even with a drop of 2 points when provided with golden visual aids. In-depth analysis reveals that the main cause of deficiencies lies in hallucination regarding the implicit visual reasoning process, shedding light on future research directions in the visual-aided MPS process.
Breaking MLPerf Training: A Case Study on Optimizing BERT
Feb 04, 2024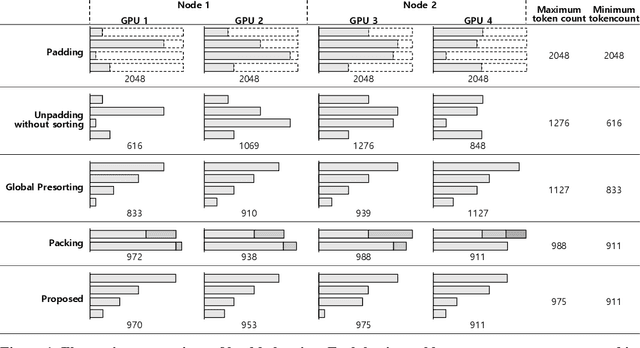
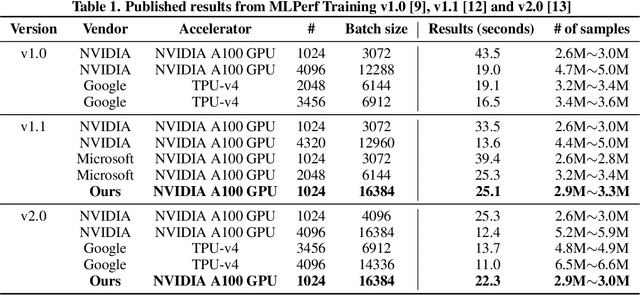
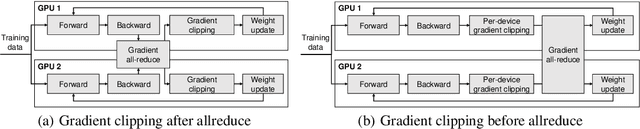
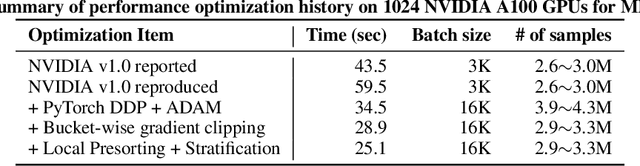
Speeding up the large-scale distributed training is challenging in that it requires improving various components of training including load balancing, communication, optimizers, etc. We present novel approaches for fast large-scale training of BERT model which individually ameliorates each component thereby leading to a new level of BERT training performance. Load balancing is imperative in distributed BERT training since its training datasets are characterized by samples with various lengths. Communication cost, which is proportional to the scale of distributed training, needs to be hidden by useful computation. In addition, the optimizers, e.g., ADAM, LAMB, etc., need to be carefully re-evaluated in the context of large-scale distributed training. We propose two new ideas, (1) local presorting based on dataset stratification for load balancing and (2) bucket-wise gradient clipping before allreduce which allows us to benefit from the overlap of gradient computation and synchronization as well as the fast training of gradient clipping before allreduce. We also re-evaluate existing optimizers via hyperparameter optimization and utilize ADAM, which also contributes to fast training via larger batches than existing methods. Our proposed methods, all combined, give the fastest MLPerf BERT training of 25.1 (22.3) seconds on 1,024 NVIDIA A100 GPUs, which is 1.33x (1.13x) and 1.57x faster than the other top two (one) submissions to MLPerf v1.1 (v2.0). Our implementation and evaluation results are available at MLPerf v1.1~v2.1.