 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Anti-noise Deep Learning Network for Robotic Grasp Detection Based on RGB Images
Oct 30, 2023While traditional methods relies on depth sensors, the current trend leans towards utilizing cost-effective RGB images, despite their absence of depth cues. This paper introduces an interesting approach to detect grasping pose from a single RGB image. To this end, we propose a modular learning network augmented with grasp detection and semantic segmentation, tailored for robots equipped with parallel-plate grippers. Our network not only identifies graspable objects but also fuses prior grasp analyses with semantic segmentation, thereby boosting grasp detection precision. Significantly, our design exhibits resilience, adeptly handling blurred and noisy visuals. Key contributions encompass a trainable network for grasp detection from RGB images, a modular design facilitating feasible grasp implementation, and an architecture robust against common image distortions. We demonstrate the feasibility and accuracy of our proposed approach through practical experiments and evaluations.
TempoSum: Evaluating the Temporal Generalization of Abstractive Summarization
May 03, 2023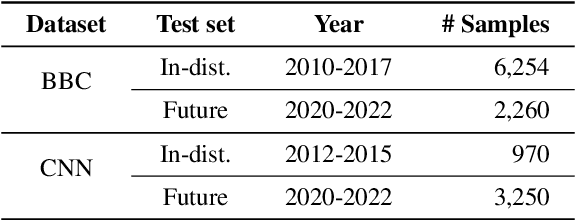
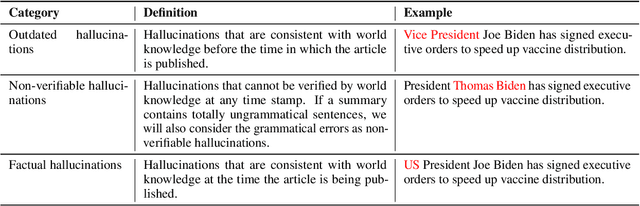
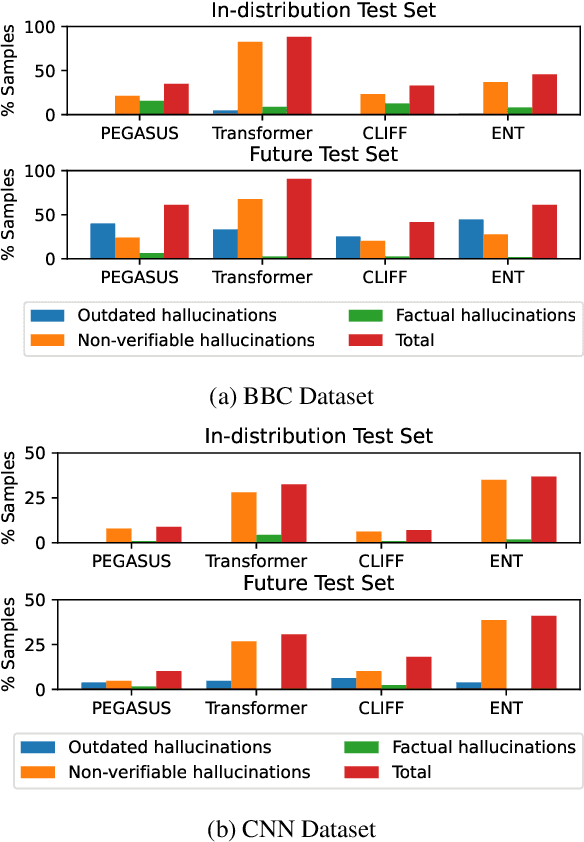
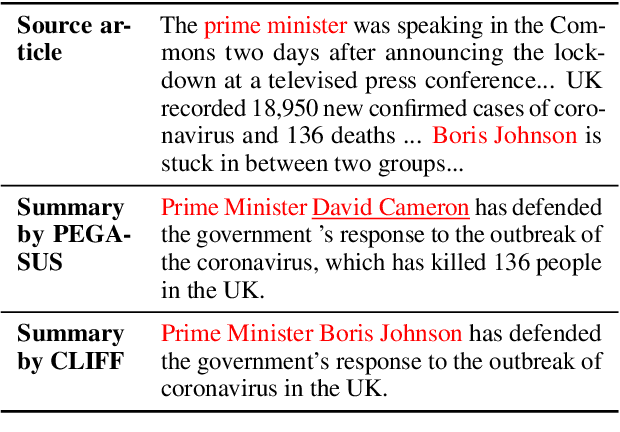
Recent pre-trained language models (PLMs) achieve promising results in existing abstractive summarization datasets. However, existing summarization benchmarks overlap in time with the standard pre-training corpora and finetuning datasets. Hence, the strong performance of PLMs may rely on the parametric knowledge that is memorized during pre-training and fine-tuning. Moreover, the knowledge memorized by PLMs may quickly become outdated, which affects the generalization performance of PLMs on future data. In this work, we propose TempoSum, a novel benchmark that contains data samples from 2010 to 2022, to understand the temporal generalization ability of abstractive summarization models. Through extensive human evaluation, we show that parametric knowledge stored in summarization models significantly affects the faithfulness of the generated summaries on future data. Moreover, existing faithfulness enhancement methods cannot reliably improve the faithfulness of summarization models on future data. Finally, we discuss several recommendations to the research community on how to evaluate and improve the temporal generalization capability of text summarization models.
ConsistTL: Modeling Consistency in Transfer Learning for Low-Resource Neural Machine Translation
Dec 08, 2022



Transfer learning is a simple and powerful method that can be used to boost model performance of low-resource neural machine translation (NMT). Existing transfer learning methods for NMT are static, which simply transfer knowledge from a parent model to a child model once via parameter initialization. In this paper, we propose a novel transfer learning method for NMT, namely ConsistTL, which can continuously transfer knowledge from the parent model during the training of the child model. Specifically, for each training instance of the child model, ConsistTL constructs the semantically-equivalent instance for the parent model and encourages prediction consistency between the parent and child for this instance, which is equivalent to the child model learning each instance under the guidance of the parent model. Experimental results on five low-resource NMT tasks demonstrate that ConsistTL results in significant improvements over strong transfer learning baselines, with a gain up to 1.7 BLEU over the existing back-translation model on the widely-used WMT17 Turkish-English benchmark. Further analysis reveals that ConsistTL can improve the inference calibration of the child model. Code and scripts are freely available at https://github.com/NLP2CT/ConsistTL.