 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotional Text-To-Speech Based on Mutual-Information-Guided Emotion-Timbre Disentanglement
Oct 02, 2025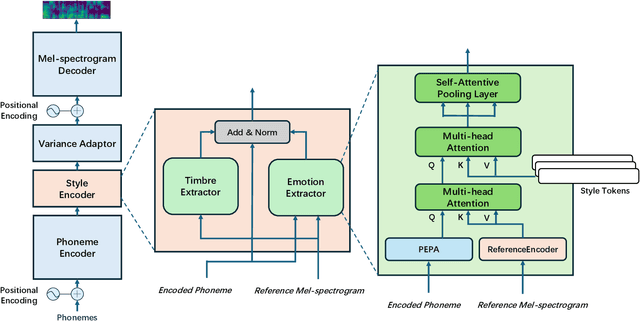
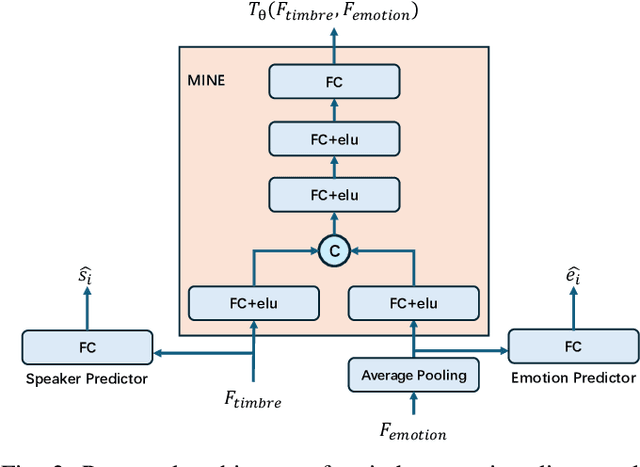
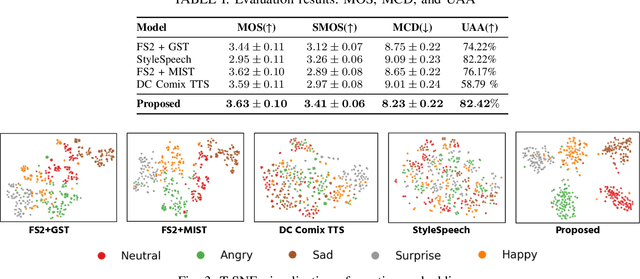
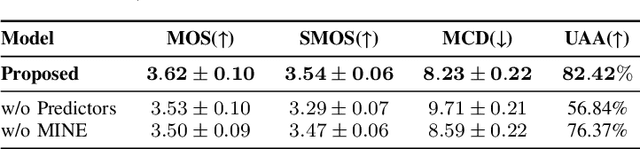
Current emotional Text-To-Speech (TTS) and style transfer methods rely on reference encoders to control global style or emotion vectors, but do not capture nuanced acoustic details of the reference speech. To this end, we propose a novel emotional TTS method that enables fine-grained phoneme-level emotion embedding prediction while disentangling intrinsic attributes of the reference speech. The proposed method employs a style disentanglement method to guide two feature extractors, reducing mutual information between timbre and emotion features, and effectively separating distinct style components from the reference speech. Experimental results demonstrate that our method outperforms baseline TTS systems in generating natural and emotionally rich speech. This work highlights the potential of disentangled and fine-grained representations in advancing the quality and flexibility of emotional TTS systems.
Learning from "Silly" Questions Improves Large Language Models, But Only Slightly
Nov 21, 2024Constructing high-quality Supervised Fine-Tuning (SFT) datasets is critical for the training of large language models (LLMs). Recent studies have shown that using data from a specific source, Ruozhiba, a Chinese website where users ask "silly" questions to better understand certain topics, can lead to better fine-tuning performance. This paper aims to explore some hidden factors: the potential interpretations of its success and a large-scale evaluation of the performance. First, we leverage GPT-4 to analyze the successful cases of Ruozhiba questions from the perspective of education, psychology, and cognitive science, deriving a set of explanatory rules. Then, we construct fine-tuning datasets by applying these rules to the MMLU training set. Surprisingly, our results indicate that rules can significantly improve model performance in certain tasks, while potentially diminishing performance on others. For example, SFT data generated following the "Counterintuitive Thinking" rule can achieve approximately a 5% improvement on the "Global Facts" task, whereas the "Blurring the Conceptual Boundaries" rule leads to a performance drop of 6.14% on the "Econometrics" task. In addition, for specific tasks, different rules tend to have a consistent impact on model performance. This suggests that the differences between the extracted rules are not as significant, and the effectiveness of the rules is relatively consistent across tasks. Our research highlights the importance of considering task diversity and rule applicability when constructing SFT datasets to achieve more comprehensive performance improvements.
Self-Supervised Syllable Discovery Based on Speaker-Disentangled HuBERT
Sep 16, 2024



Self-supervised speech representation learning has become essential for extracting meaningful features from untranscribed audio. Recent advances highlight the potential of deriving discrete symbols from the features correlated with linguistic units, which enables text-less training across diverse tasks. In particular, sentence-level Self-Distillation of the pretrained HuBERT (SD-HuBERT) induces syllabic structures within latent speech frame representations extracted from an intermediate Transformer layer. In SD-HuBERT, sentence-level representation is accumulated from speech frame features through self-attention layers using a special CLS token. However, we observe that the information aggregated in the CLS token correlates more with speaker identity than with linguistic content. To address this, we propose a speech-only self-supervised fine-tuning approach that separates syllabic units from speaker information. Our method introduces speaker perturbation as data augmentation and adopts a frame-level training objective to prevent the CLS token from aggregating paralinguistic information. Experimental results show that our approach surpasses the current state-of-the-art method in most syllable segmentation and syllabic unit quality metrics on Librispeech, underscoring its effectiveness in promoting syllabic organization within speech-only models.
Deep Generic Representations for Domain-Generalized Anomalous Sound Detection
Sep 08, 2024Developing a reliable anomalous sound detection (ASD) system requires robustness to noise, adaptation to domain shifts, and effective performance with limited training data. Current leading methods rely on extensive labeled data for each target machine type to train feature extractors using Outlier-Exposure (OE) techniques, yet their performance on the target domain remains sub-optimal. In this paper, we present \textit{GenRep}, which utilizes generic feature representations from a robust, large-scale pre-trained feature extractor combined with kNN for domain-generalized ASD, without the need for fine-tuning. \textit{GenRep} incorporates MemMixup, a simple approach for augmenting the target memory bank using nearest source samples, paired with a domain normalization technique to address the imbalance between source and target domains. \textit{GenRep} outperforms the best OE-based approach without a need for labeled data with an Official Score of 73.79\% on the DCASE2023T2 Eval set and demonstrates robustness under limited data scenarios. The code is available open-source.
Streaming Target-Speaker ASR with Neural Transducer
Sep 19, 2022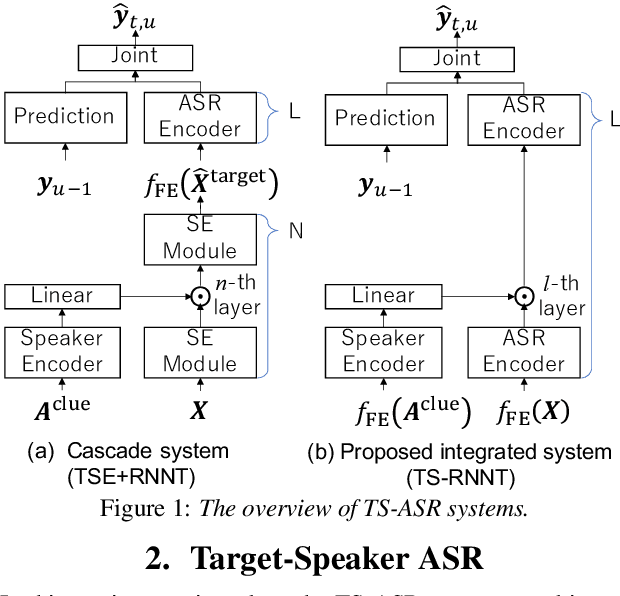

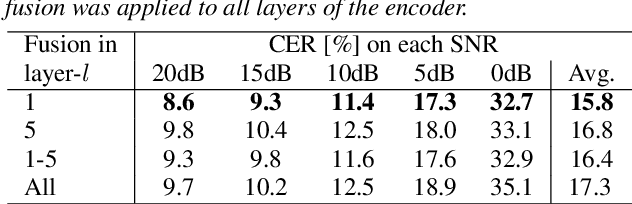
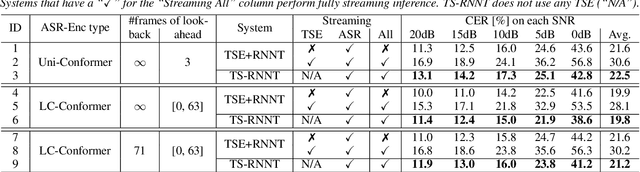
Although recent advances in deep learning technology have boosted automatic speech recognition (ASR) performance in the single-talker case, it remains difficult to recognize multi-talker speech in which many voices overlap. One conventional approach to tackle this problem is to use a cascade of a speech separation or target speech extraction front-end with an ASR back-end. However, the extra computation costs of the front-end module are a critical barrier to quick response, especially for streaming ASR. In this paper, we propose a target-speaker ASR (TS-ASR) system that implicitly integrates the target speech extraction functionality within a streaming end-to-end (E2E) ASR system, i.e. recurrent neural network-transducer (RNNT). Our system uses a similar idea as adopted for target speech extraction, but implements it directly at the level of the encoder of RNNT. This allows TS-ASR to be realized without placing extra computation costs on the front-end. Note that this study presents two major differences between prior studies on E2E TS-ASR; we investigate streaming models and base our study on Conformer models, whereas prior studies used RNN-based systems and considered only offline processing. We confirm in experiments that our TS-ASR achieves comparable recognition performance with conventional cascade systems in the offline setting, while reducing computation costs and realizing streaming TS-ASR.
Exploiting Unlabeled Data for Target-Oriented Opinion Words Extraction
Aug 17, 2022
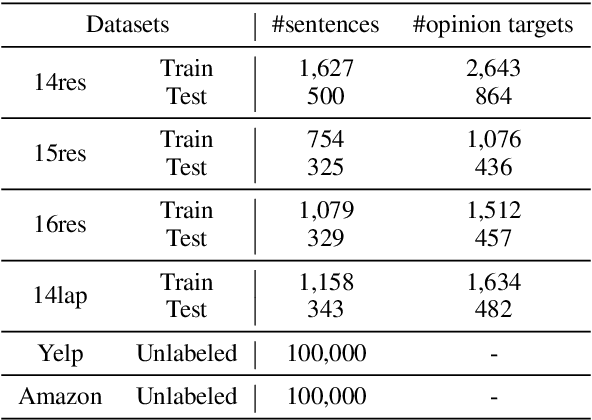


Target-oriented Opinion Words Extraction (TOWE) is a fine-grained sentiment analysis task that aims to extract the corresponding opinion words of a given opinion target from the sentence. Recently, deep learning approaches have made remarkable progress on this task. Nevertheless, the TOWE task still suffers from the scarcity of training data due to the expensive data annotation process. Limited labeled data increase the risk of distribution shift between test data and training data. In this paper, we propose exploiting massive unlabeled data to reduce the risk by increasing the exposure of the model to varying distribution shifts. Specifically, we propose a novel Multi-Grained Consistency Regularization (MGCR) method to make use of unlabeled data and design two filters specifically for TOWE to filter noisy data at different granularity. Extensive experimental results on four TOWE benchmark datasets indicate the superiority of MGCR compared with current state-of-the-art methods. The in-depth analysis also demonstrates the effectiveness of the different-granularity filters. Our codes are available at https://github.com/TOWESSL/TOWESSL.
USB: A Unified Semi-supervised Learning Benchmark
Aug 12, 2022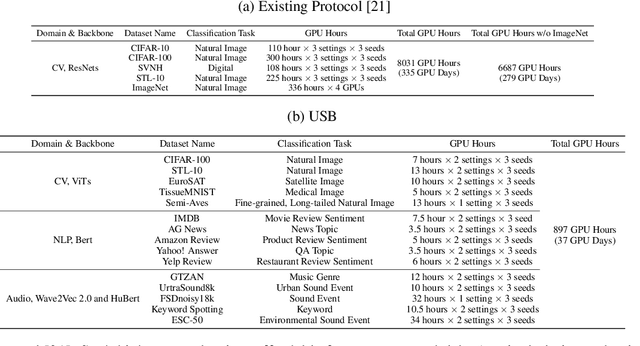
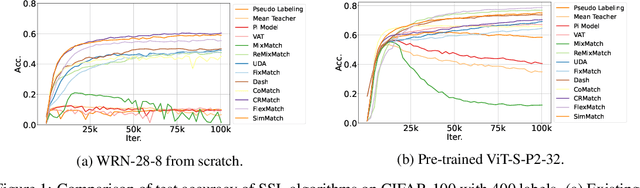
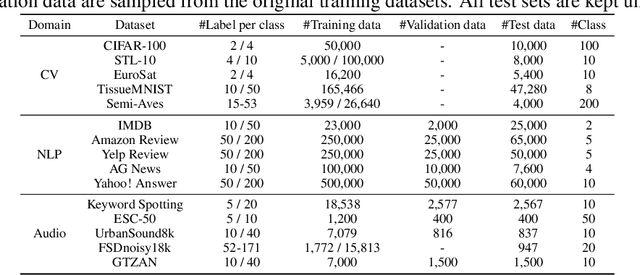
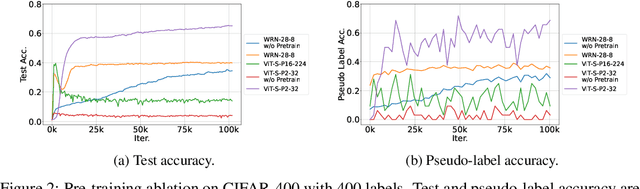
Semi-supervised learning (SSL) improves model generalization by leveraging massive unlabeled data to augment limited labeled samples. However, currently, popular SSL evaluation protocols are often constrained to computer vision (CV) tasks. In addition, previous work typically trains deep neural networks from scratch, which is time-consuming and environmentally unfriendly. To address the above issues, we construct a Unified SSL Benchmark (USB) by selecting 15 diverse, challenging, and comprehensive tasks from CV, natural language processing (NLP), and audio processing (Audio), on which we systematically evaluate dominant SSL methods, and also open-source a modular and extensible codebase for fair evaluation on these SSL methods. We further provide pre-trained versions of the state-of-the-art neural models for CV tasks to make the cost affordable for further tuning. USB enables the evaluation of a single SSL algorithm on more tasks from multiple domains but with less cost. Specifically, on a single NVIDIA V100, only 37 GPU days are required to evaluate FixMatch on 15 tasks in USB while 335 GPU days (279 GPU days on 4 CV datasets except for ImageNet) are needed on 5 CV tasks with the typical protocol.
Censer: Curriculum Semi-supervised Learning for Speech Recognition Based on Self-supervised Pre-training
Jun 27, 2022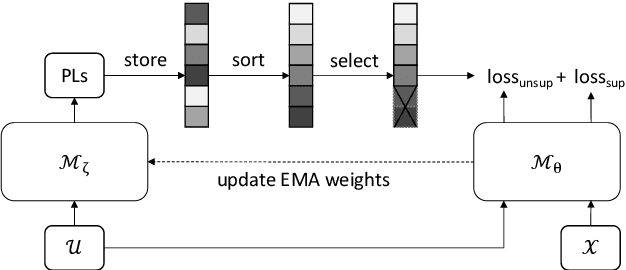

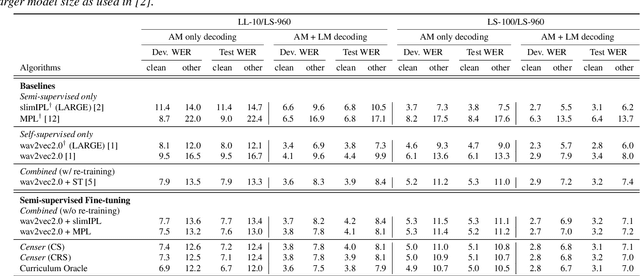
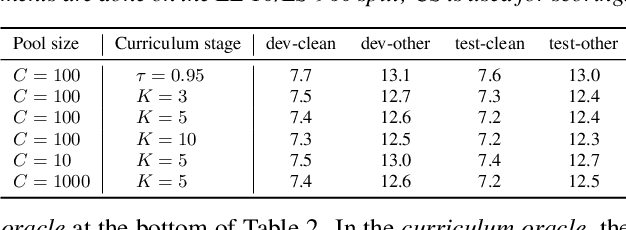
Recent studies have shown that the benefits provided by self-supervised pre-training and self-training (pseudo-labeling) are complementary. Semi-supervised fine-tuning strategies under the pre-training framework, however, remain insufficiently studied. Besides, modern semi-supervised speech recognition algorithms either treat unlabeled data indiscriminately or filter out noisy samples with a confidence threshold. The dissimilarities among different unlabeled data are often ignored. In this paper, we propose Censer, a semi-supervised speech recognition algorithm based on self-supervised pre-training to maximize the utilization of unlabeled data. The pre-training stage of Censer adopts wav2vec2.0 and the fine-tuning stage employs an improved semi-supervised learning algorithm from slimIPL, which leverages unlabeled data progressively according to their pseudo labels' qualities. We also incorporate a temporal pseudo label pool and an exponential moving average to control the pseudo labels' update frequency and to avoid model divergence. Experimental results on Libri-Light and LibriSpeech datasets manifest our proposed method achieves better performance compared to existing approaches while being more unified.
FreeMatch: Self-adaptive Thresholding for Semi-supervised Learning
May 15, 2022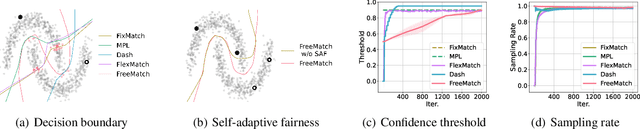
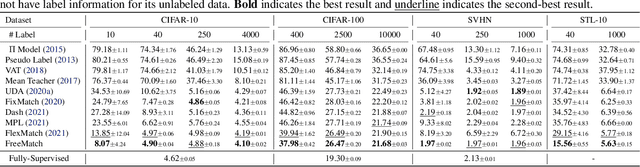
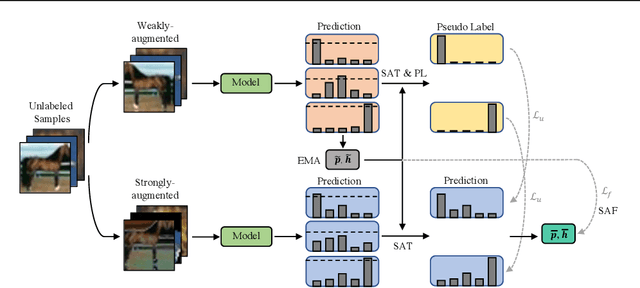
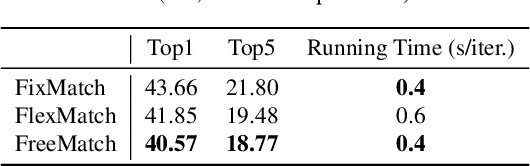
Pseudo labeling and consistency regularization approaches with confidence-based thresholding have made great progress in semi-supervised learning (SSL). In this paper, we theoretically and empirically analyze the relationship between the unlabeled data distribution and the desirable confidence threshold. Our analysis shows that previous methods might fail to define favorable threshold since they either require a pre-defined / fixed threshold or an ad-hoc threshold adjusting scheme that does not reflect the learning effect well, resulting in inferior performance and slow convergence, especially for complicated unlabeled data distributions. We hence propose \emph{FreeMatch} to define and adjust the confidence threshold in a self-adaptive manner according to the model's learning status. To handle complicated unlabeled data distributions more effectively, we further propose a self-adaptive class fairness regularization method that encourages the model to produce diverse predictions during training. Extensive experimental results indicate the superiority of FreeMatch especially when the labeled data are extremely rare. FreeMatch achieves \textbf{5.78}\%, \textbf{13.59}\%, and \textbf{1.28}\% error rate reduction over the latest state-of-the-art method FlexMatch on CIFAR-10 with 1 label per class, STL-10 with 4 labels per class, and ImageNet with 100k labels respectively.
Margin Calibration for Long-Tailed Visual Recognition
Dec 14, 2021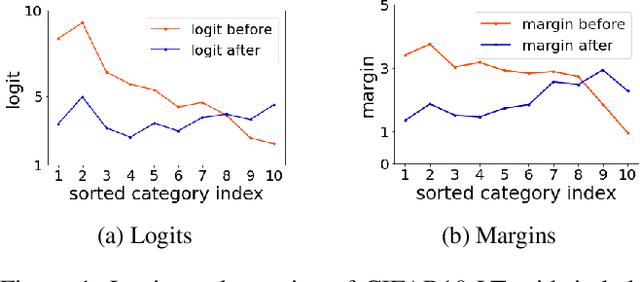

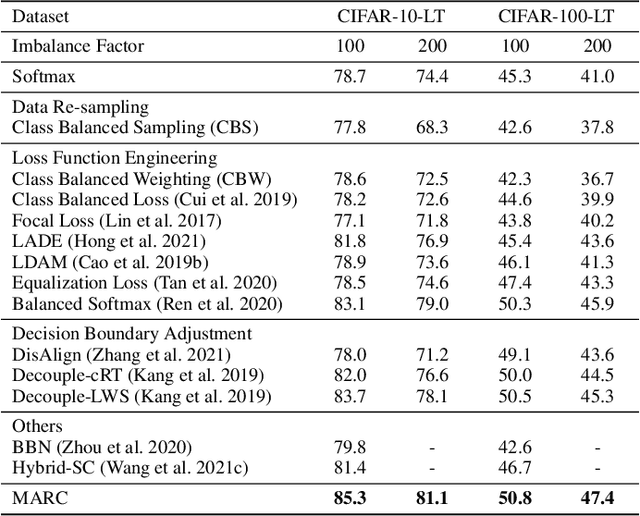
The long-tailed class distribution in visual recognition tasks poses great challenges for neural networks on how to handle the biased predictions between head and tail classes, i.e., the model tends to classify tail classes as head classes. While existing research focused on data resampling and loss function engineering, in this paper, we take a different perspective: the classification margins. We study the relationship between the margins and logits (classification scores) and empirically observe the biased margins and the biased logits are positively correlated. We propose MARC, a simple yet effective MARgin Calibration function to dynamically calibrate the biased margins for unbiased logits. We validate MARC through extensive experiments on common long-tailed benchmarks including CIFAR-LT, ImageNet-LT, Places-LT, and iNaturalist-LT. Experimental results demonstrate that our MARC achieves favorable results on these benchmarks. In addition, MARC is extremely easy to implement with just three lines of code. We hope this simple method will motivate people to rethink the biased margins and biased logits in long-tailed visual recognition.