 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeMatch: Self-adaptive Thresholding for Semi-supervised Learning
Paper and Code
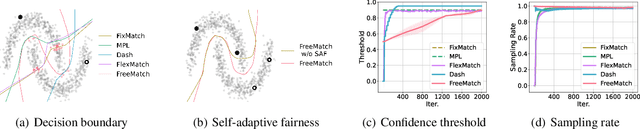
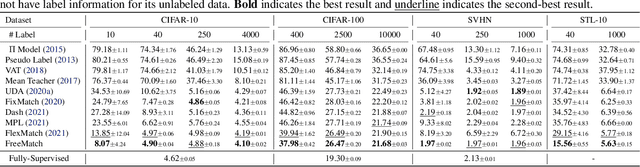
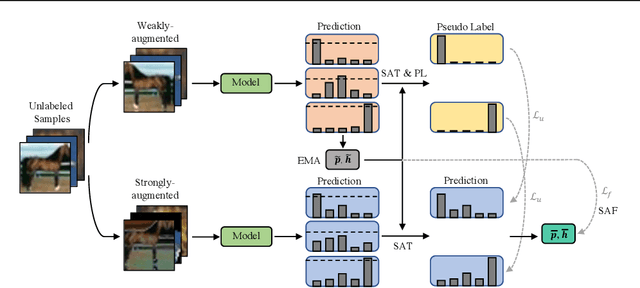
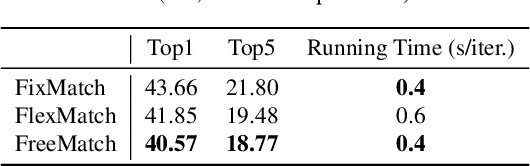
Pseudo labeling and consistency regularization approaches with confidence-based thresholding have made great progress in semi-supervised learning (SSL). In this paper, we theoretically and empirically analyze the relationship between the unlabeled data distribution and the desirable confidence threshold. Our analysis shows that previous methods might fail to define favorable threshold since they either require a pre-defined / fixed threshold or an ad-hoc threshold adjusting scheme that does not reflect the learning effect well, resulting in inferior performance and slow convergence, especially for complicated unlabeled data distributions. We hence propose \emph{FreeMatch} to define and adjust the confidence threshold in a self-adaptive manner according to the model's learning status. To handle complicated unlabeled data distributions more effectively, we further propose a self-adaptive class fairness regularization method that encourages the model to produce diverse predictions during training. Extensive experimental results indicate the superiority of FreeMatch especially when the labeled data are extremely rare. FreeMatch achieves \textbf{5.78}\%, \textbf{13.59}\%, and \textbf{1.28}\% error rate reduction over the latest state-of-the-art method FlexMatch on CIFAR-10 with 1 label per class, STL-10 with 4 labels per class, and ImageNet with 100k labels respectively.