 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCenser: Curriculum Semi-supervised Learning for Speech Recognition Based on Self-supervised Pre-training
Paper and Code
Jun 27, 2022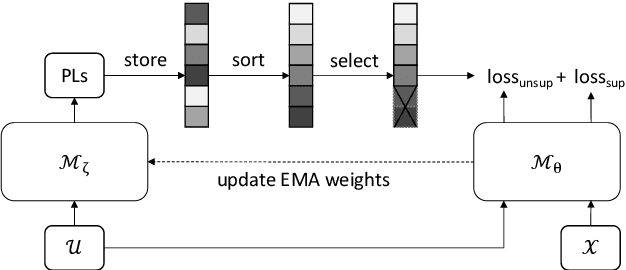

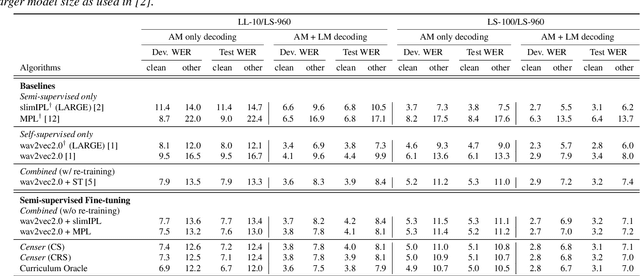
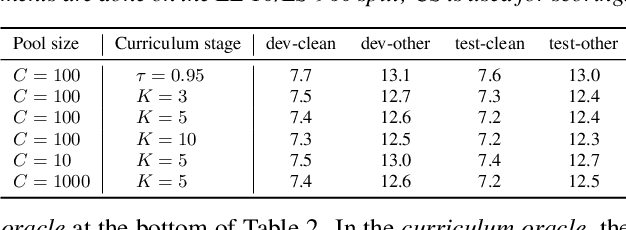
Recent studies have shown that the benefits provided by self-supervised pre-training and self-training (pseudo-labeling) are complementary. Semi-supervised fine-tuning strategies under the pre-training framework, however, remain insufficiently studied. Besides, modern semi-supervised speech recognition algorithms either treat unlabeled data indiscriminately or filter out noisy samples with a confidence threshold. The dissimilarities among different unlabeled data are often ignored. In this paper, we propose Censer, a semi-supervised speech recognition algorithm based on self-supervised pre-training to maximize the utilization of unlabeled data. The pre-training stage of Censer adopts wav2vec2.0 and the fine-tuning stage employs an improved semi-supervised learning algorithm from slimIPL, which leverages unlabeled data progressively according to their pseudo labels' qualities. We also incorporate a temporal pseudo label pool and an exponential moving average to control the pseudo labels' update frequency and to avoid model divergence. Experimental results on Libri-Light and LibriSpeech datasets manifest our proposed method achieves better performance compared to existing approaches while being more unified.