 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDMLP: Image Classification from Scratch on Small Datasets with MLP
May 28, 2022
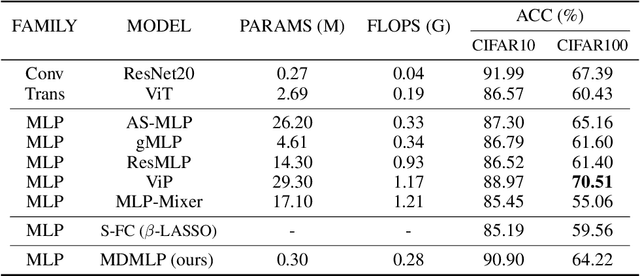
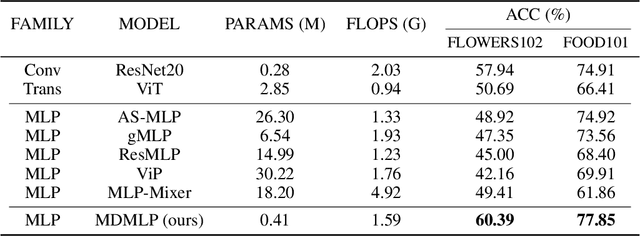

The attention mechanism has become a go-to technique for natural language processing and computer vision tasks. Recently, the MLP-Mixer and other MLP-based architectures, based simply on multi-layer perceptrons (MLPs), are also powerful compared to CNNs and attention techniques and raises a new research direction. However, the high capability of the MLP-based networks severely relies on large volume of training data, and lacks of explanation ability compared to the Vision Transformer (ViT) or ConvNets. When trained on small datasets, they usually achieved inferior results than ConvNets. To resolve it, we present (i) multi-dimensional MLP (MDMLP), a conceptually simple and lightweight MLP-based architecture yet achieves SOTA when training from scratch on small-size datasets; (ii) multi-dimension MLP Attention Tool (MDAttnTool), a novel and efficient attention mechanism based on MLPs. Even without strong data augmentation, MDMLP achieves 90.90% accuracy on CIFAR10 with only 0.3M parameters, while the well-known MLP-Mixer achieves 85.45% with 17.1M parameters. In addition, the lightweight MDAttnTool highlights objects in images, indicating its explanation power. Our code is available at https://github.com/Amoza-Theodore/MDMLP.
Unimodal Face Classification with Multimodal Training
Dec 08, 2021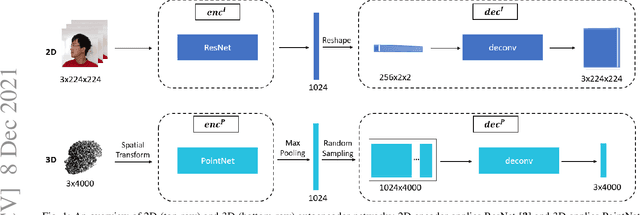
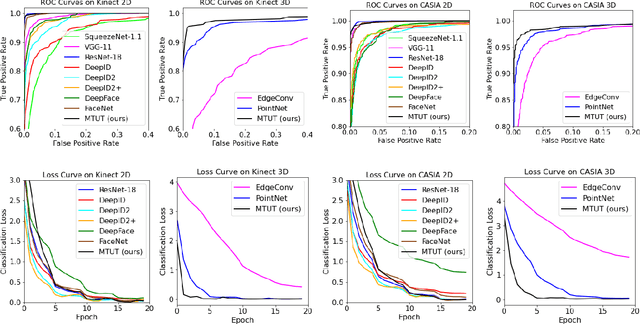
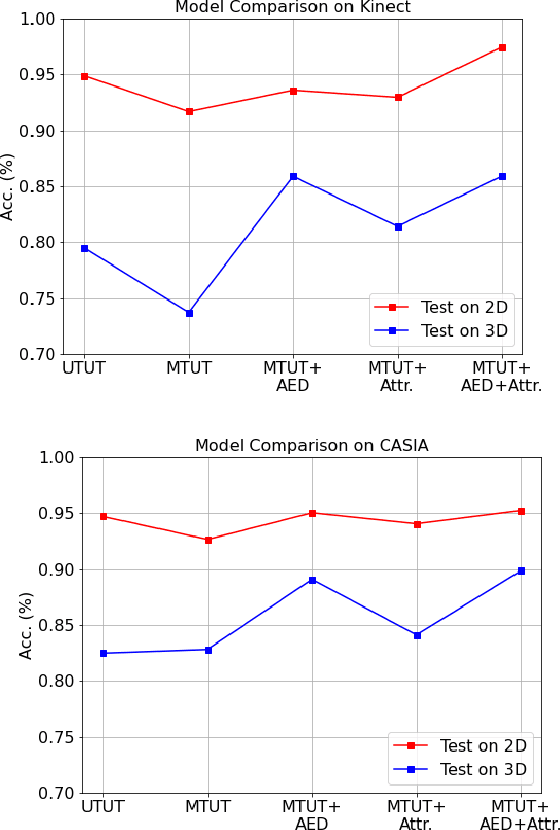
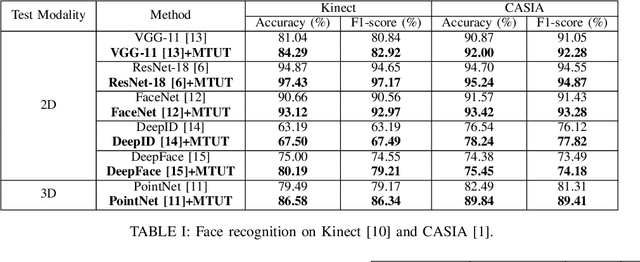
Face recognition is a crucial task in various multimedia applications such as security check, credential access and motion sensing games. However, the task is challenging when an input face is noisy (e.g. poor-condition RGB image) or lacks certain information (e.g. 3D face without color). In this work, we propose a Multimodal Training Unimodal Test (MTUT) framework for robust face classification, which exploits the cross-modality relationship during training and applies it as a complementary of the imperfect single modality input during testing. Technically, during training, the framework (1) builds both intra-modality and cross-modality autoencoders with the aid of facial attributes to learn latent embeddings as multimodal descriptors, (2) proposes a novel multimodal embedding divergence loss to align the heterogeneous features from different modalities, which also adaptively avoids the useless modality (if any) from confusing the model. This way, the learned autoencoders can generate robust embeddings in single-modality face classification on test stage. We evaluate our framework in two face classification datasets and two kinds of testing input: (1) poor-condition image and (2) point cloud or 3D face mesh, when both 2D and 3D modalities are available for training. We experimentally show that our MTUT framework consistently outperforms ten baselines on 2D and 3D settings of both datasets.
UIBert: Learning Generic Multimodal Representations for UI Understanding
Aug 10, 2021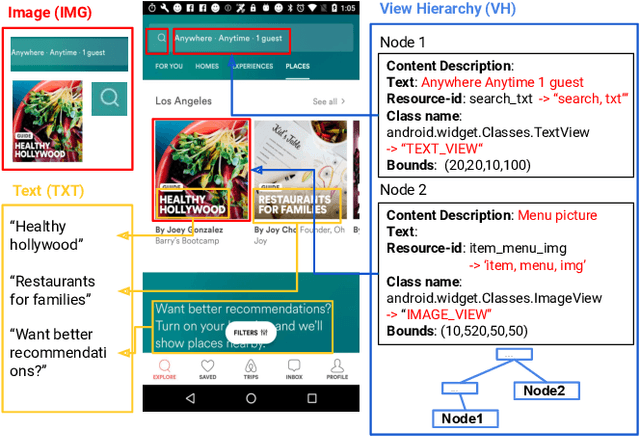
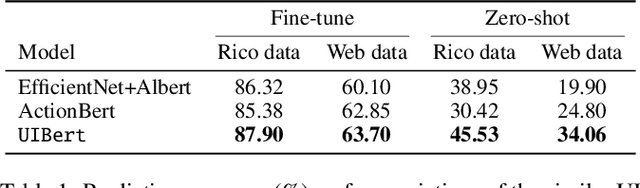
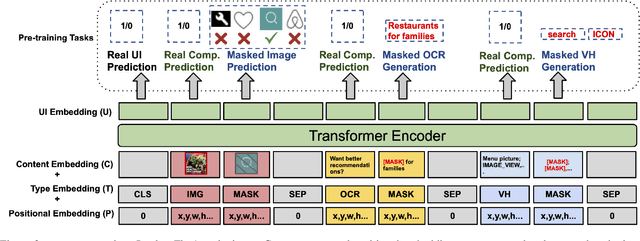
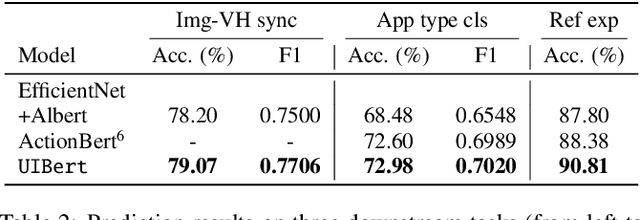
To improve the accessibility of smart devices and to simplify their usage, building models which understand user interfaces (UIs) and assist users to complete their tasks is critical. However, unique challenges are proposed by UI-specific characteristics, such as how to effectively leverage multimodal UI features that involve image, text, and structural metadata and how to achieve good performance when high-quality labeled data is unavailable. To address such challenges we introduce UIBert, a transformer-based joint image-text model trained through novel pre-training tasks on large-scale unlabeled UI data to learn generic feature representations for a UI and its components. Our key intuition is that the heterogeneous features in a UI are self-aligned, i.e., the image and text features of UI components, are predictive of each other. We propose five pretraining tasks utilizing this self-alignment among different features of a UI component and across various components in the same UI. We evaluate our method on nine real-world downstream UI tasks where UIBert outperforms strong multimodal baselines by up to 9.26% accuracy.
M2P2: Multimodal Persuasion Prediction using Adaptive Fusion
Jun 03, 2020

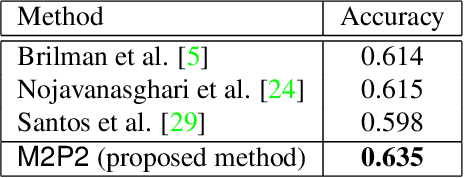

Identifying persuasive speakers in an adversarial environment is a critical task. In a national election, politicians would like to have persuasive speakers campaign on their behalf. When a company faces adverse publicity, they would like to engage persuasive advocates for their position in the presence of adversaries who are critical of them. Debates represent a common platform for these forms of adversarial persuasion. This paper solves two problems: the Debate Outcome Prediction (DOP) problem predicts who wins a debate while the Intensity of Persuasion Prediction (IPP) problem predicts the change in the number of votes before and after a speaker speaks. Though DOP has been previously studied, we are the first to study IPP. Past studies on DOP fail to leverage two important aspects of multimodal data: 1) multiple modalities are often semantically aligned, and 2) different modalities may provide diverse information for prediction. Our M2P2 (Multimodal Persuasion Prediction) framework is the first to use multimodal (acoustic, visual, language) data to solve the IPP problem. To leverage the alignment of different modalities while maintaining the diversity of the cues they provide, M2P2 devises a novel adaptive fusion learning framework which fuses embeddings obtained from two modules -- an alignment module that extracts shared information between modalities and a heterogeneity module that learns the weights of different modalities with guidance from three separately trained unimodal reference models. We test M2P2 on the popular IQ2US dataset designed for DOP. We also introduce a new dataset called QPS (from Qipashuo, a popular Chinese debate TV show ) for IPP. M2P2 significantly outperforms 3 recent baselines on both datasets. Our code and QPS dataset can be found at http://snap.stanford.edu/m2p2/.
C2P2: A Collective Cryptocurrency Up/Down Price Prediction Engine
Jun 03, 2019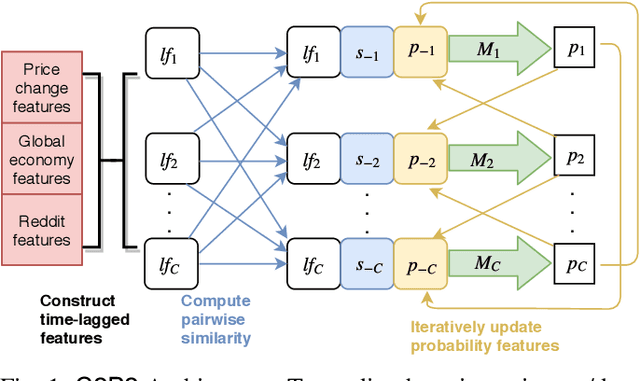
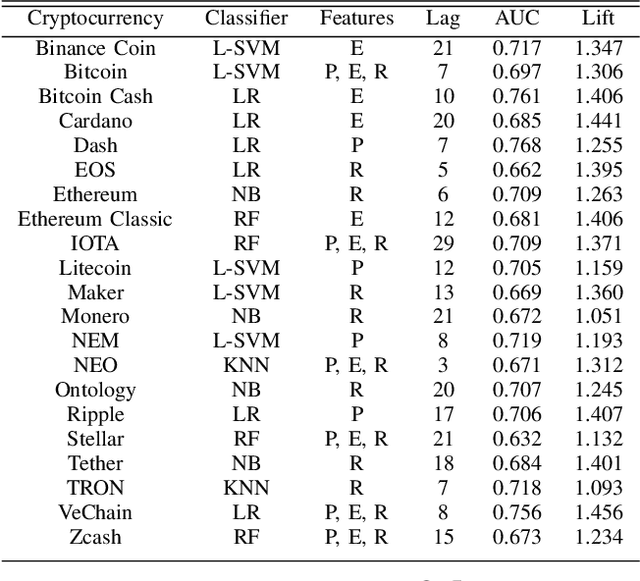
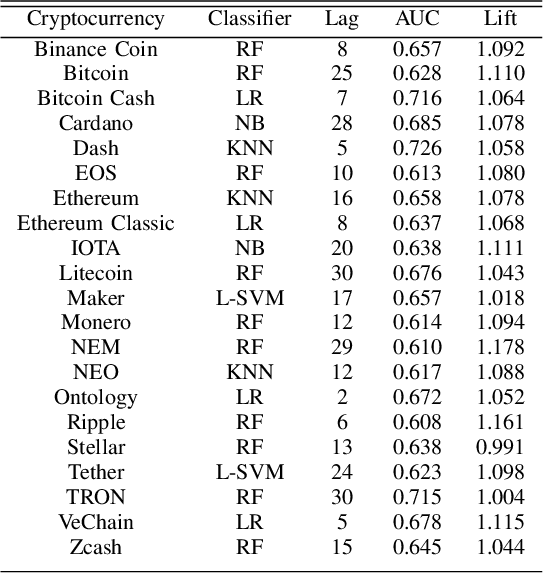
We study the problem of predicting whether the price of the 21 most popular cryptocurrencies (according to coinmarketcap.com) will go up or down on day d, using data up to day d-1. Our C2P2 algorithm is the first algorithm to consider the fact that the price of a cryptocurrency c might depend not only on historical prices, sentiments, global stock indices, but also on the prices and predicted prices of other cryptocurrencies. C2P2 therefore does not predict cryptocurrency prices one coin at a time --- rather it uses similarity metrics in conjunction with collective classification to compare multiple cryptocurrency features to jointly predict the cryptocurrency prices for all 21 coins considered. We show that our C2P2 algorithm beats out a recent competing 2017 paper by margins varying from 5.1-83% and another Bitcoin-specific prediction paper from 2018 by 16%. In both cases, C2P2 is the winner on all cryptocurrencies considered. Moreover, we experimentally show that the use of similarity metrics within our C2P2 algorithm leads to a direct improvement for 20 out of 21 cryptocurrencies ranging from 0.4% to 17.8%. Without the similarity component, C2P2 still beats competitors on 20 out of 21 cryptocurrencies considered. We show that all these results are statistically significant via a Student's t-test with p<1e-5. Check our demo at https://www.cs.dartmouth.edu/dsail/demos/c2p2
Automatic Long-Term Deception Detection in Group Interaction Videos
May 15, 2019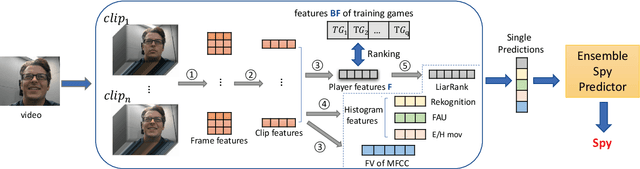
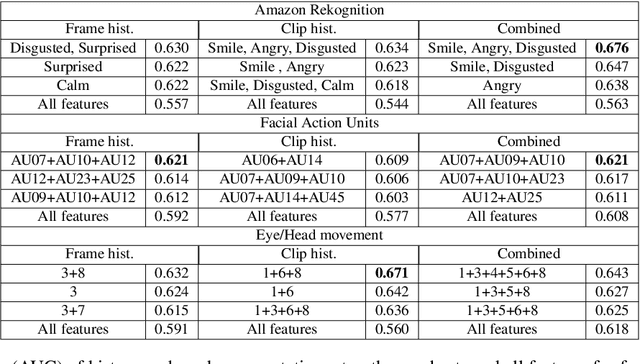
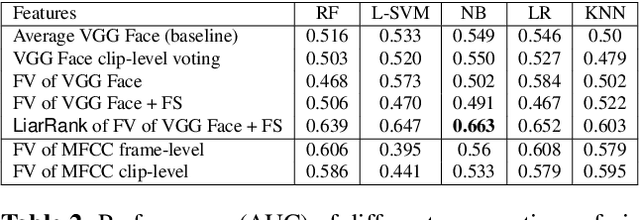
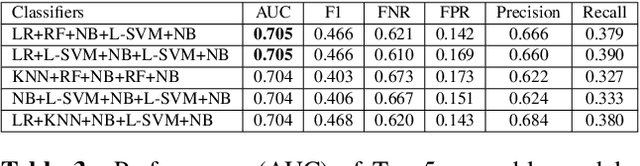
Most work on automated deception detection (ADD) in video has two restrictions: (i) it focuses on a video of one person, and (ii) it focuses on a single act of deception in a one or two minute video. In this paper, we propose a new ADD framework which captures long term deception in a group setting. We study deception in the well-known Resistance game (like Mafia and Werewolf) which consists of 5-8 players of whom 2-3 are spies. Spies are deceptive throughout the game (typically 30-65 minutes) to keep their identity hidden. We develop an ensemble predictive model to identify spies in Resistance videos. We show that features from low-level and high-level video analysis are insufficient, but when combined with a new class of features that we call LiarRank, produce the best results. We achieve AUCs of over 0.70 in a fully automated setting. Our demo can be found at http://home.cs.dartmouth.edu/~mbolonkin/scan/demo/