 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDMLP: Image Classification from Scratch on Small Datasets with MLP
Paper and Code

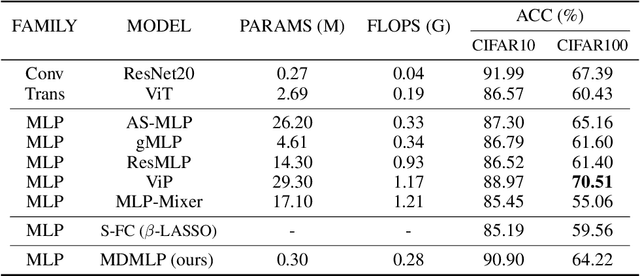
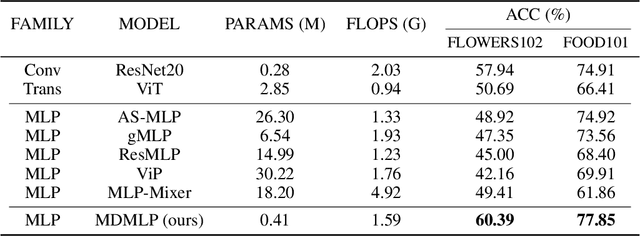

The attention mechanism has become a go-to technique for natural language processing and computer vision tasks. Recently, the MLP-Mixer and other MLP-based architectures, based simply on multi-layer perceptrons (MLPs), are also powerful compared to CNNs and attention techniques and raises a new research direction. However, the high capability of the MLP-based networks severely relies on large volume of training data, and lacks of explanation ability compared to the Vision Transformer (ViT) or ConvNets. When trained on small datasets, they usually achieved inferior results than ConvNets. To resolve it, we present (i) multi-dimensional MLP (MDMLP), a conceptually simple and lightweight MLP-based architecture yet achieves SOTA when training from scratch on small-size datasets; (ii) multi-dimension MLP Attention Tool (MDAttnTool), a novel and efficient attention mechanism based on MLPs. Even without strong data augmentation, MDMLP achieves 90.90% accuracy on CIFAR10 with only 0.3M parameters, while the well-known MLP-Mixer achieves 85.45% with 17.1M parameters. In addition, the lightweight MDAttnTool highlights objects in images, indicating its explanation power. Our code is available at https://github.com/Amoza-Theodore/MDMLP.