 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinated Reply Attacks in Influence Operations: Characterization and Detection
Oct 25, 2024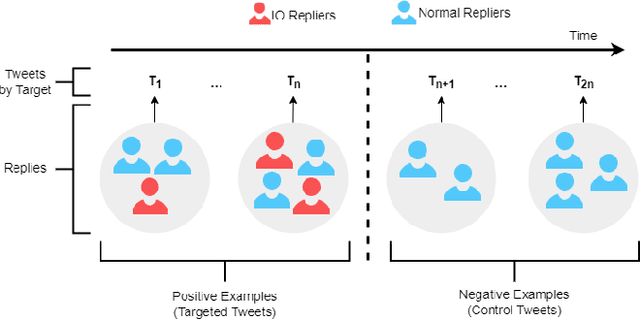

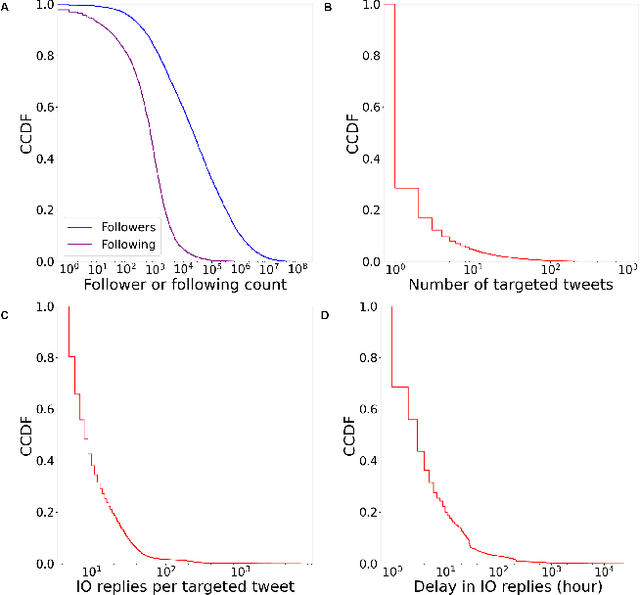
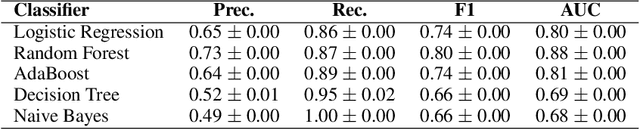
Coordinated reply attacks are a tactic observed in online influence operations and other coordinated campaigns to support or harass targeted individuals, or influence them or their followers. Despite its potential to influence the public, past studies have yet to analyze or provide a methodology to detect this tactic. In this study, we characterize coordinated reply attacks in the context of influence operations on Twitter. Our analysis reveals that the primary targets of these attacks are influential people such as journalists, news media, state officials, and politicians. We propose two supervised machine-learning models, one to classify tweets to determine whether they are targeted by a reply attack, and one to classify accounts that reply to a targeted tweet to determine whether they are part of a coordinated attack. The classifiers achieve AUC scores of 0.88 and 0.97, respectively. These results indicate that accounts involved in reply attacks can be detected, and the targeted accounts themselves can serve as sensors for influence operation detection.
Reconciling the Quality vs Popularity Dichotomy in Online Cultural Markets
Apr 28, 2022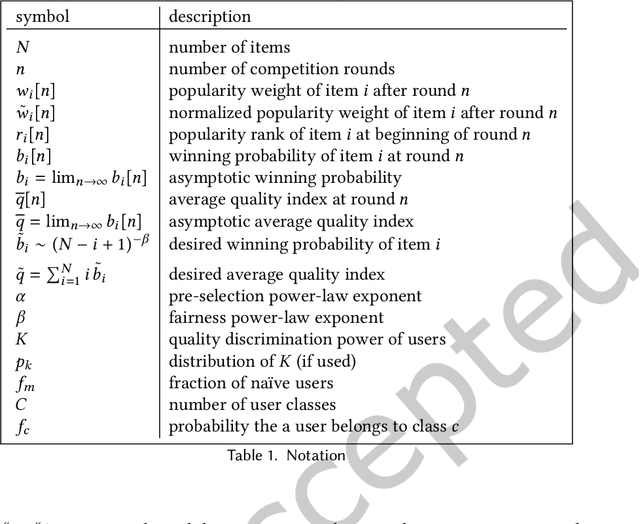
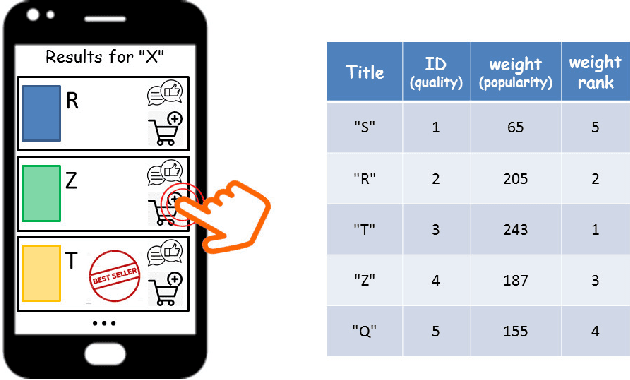
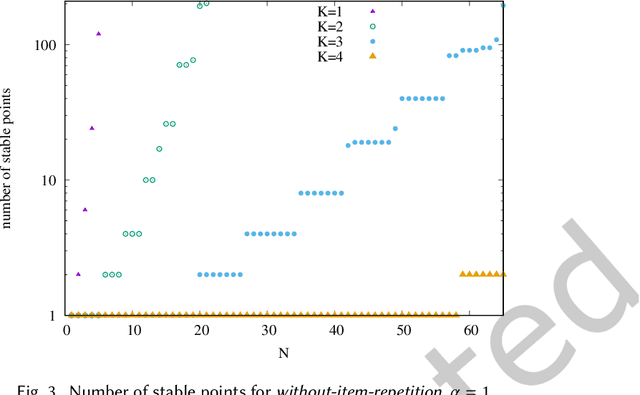
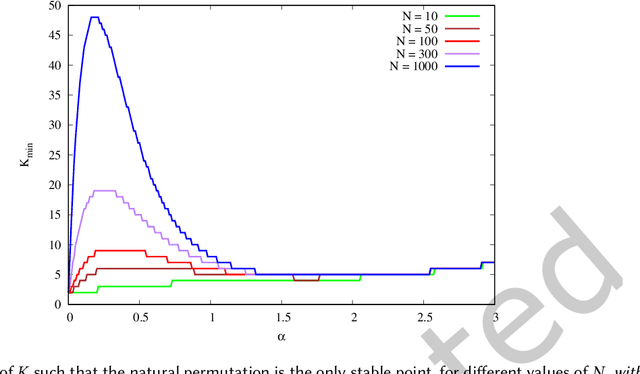
We propose a simple model of an idealized online cultural market in which $N$ items, endowed with a hidden quality metric, are recommended to users by a ranking algorithm possibly biased by the current items' popularity. Our goal is to better understand the underlying mechanisms of the well-known fact that popularity bias can prevent higher-quality items from becoming more popular than lower-quality items, producing an undesirable misalignment between quality and popularity rankings. We do so under the assumption that users, having limited time/attention, are able to discriminate the best-quality only within a random subset of the items. We discover the existence of a harmful regime in which improper use of popularity can seriously compromise the emergence of quality, and a benign regime in which wise use of popularity, coupled with a small discrimination effort on behalf of users, guarantees the perfect alignment of quality and popularity ranking. Our findings clarify the effects of algorithmic popularity bias on quality outcomes, and may inform the design of more principled mechanisms for techno-social cultural markets.
Detection of Novel Social Bots by Ensembles of Specialized Classifiers
Jun 11, 2020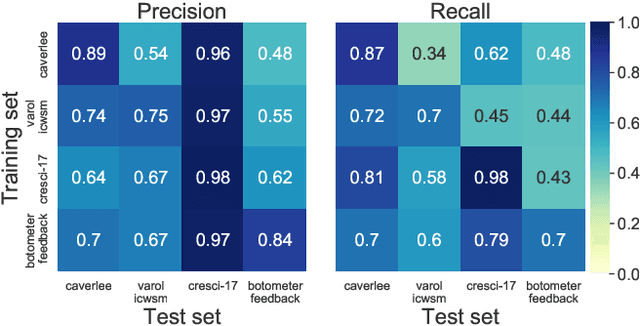
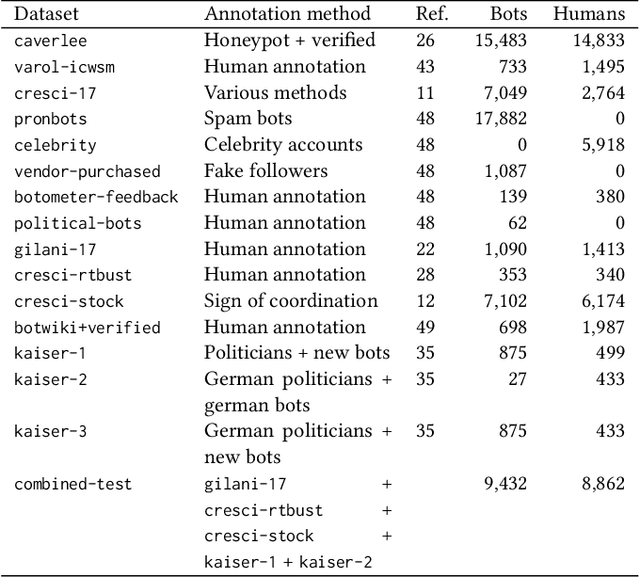

Malicious actors create inauthentic social media accounts controlled in part by algorithms, known as social bots, to disseminate misinformation and agitate online discussion. While researchers have developed sophisticated methods to detect abuse, novel bots with diverse behaviors evade detection. We show that different types of bots are characterized by different behavioral features. As a result, commonly used supervised learning techniques suffer severe performance deterioration when attempting to detect behaviors not observed in the training data. Moreover, tuning these models to recognize novel bots requires retraining with a significant amount of new annotations, which are expensive to obtain. To address these issues, we propose a new supervised learning method that trains classifiers specialized for each class of bots and combines their decisions through the maximum rule. The ensemble of specialized classifiers (ESC) can better generalize, leading to an average improvement of 56% in F1 score for unseen accounts across datasets. Furthermore, novel bot behaviors are learned with fewer labeled examples during retraining. We are deploying ESC in the newest version of Botometer, a popular tool to detect social bots in the wild.
Recency predicts bursts in the evolution of author citations
Nov 27, 2019
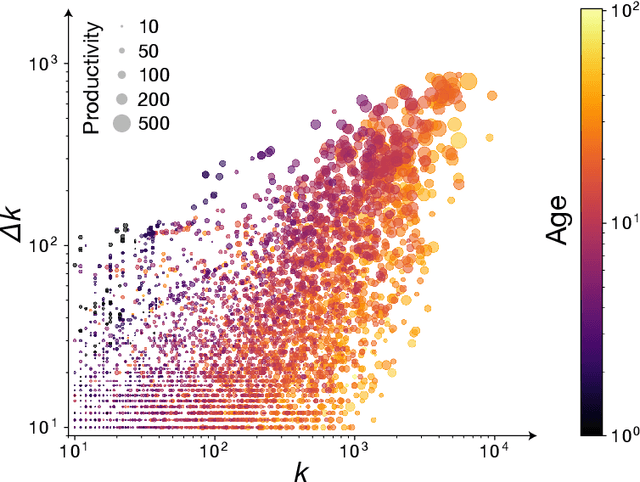
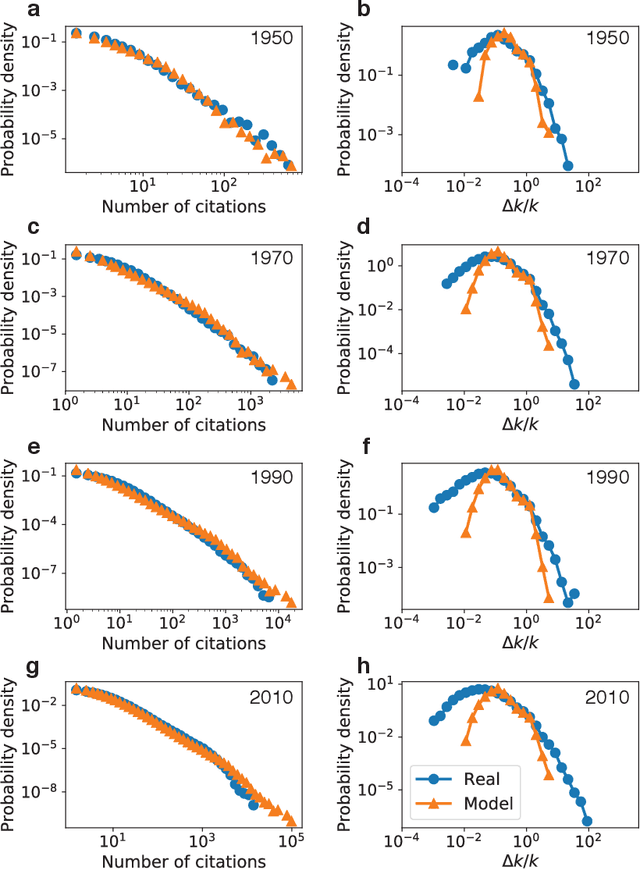
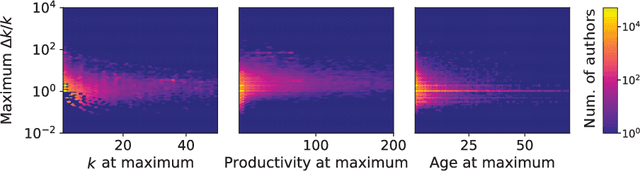
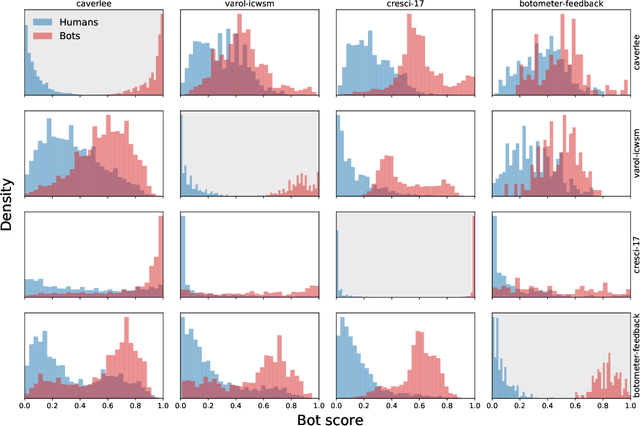
The citations process for scientific papers has been studied extensively. But while the citations accrued by authors are the sum of the citations of their papers, translating the dynamics of citation accumulation from the paper to the author level is not trivial. Here we conduct a systematic study of the evolution of author citations, and in particular their bursty dynamics. We find empirical evidence of a correlation between the number of citations most recently accrued by an author and the number of citations they receive in the future. Using a simple model where the probability for an author to receive new citations depends only on the number of citations collected in the previous 12-24 months, we are able to reproduce both the citation and burst size distributions of authors across multiple decades.
Finding Streams in Knowledge Graphs to Support Fact Checking
Aug 24, 2017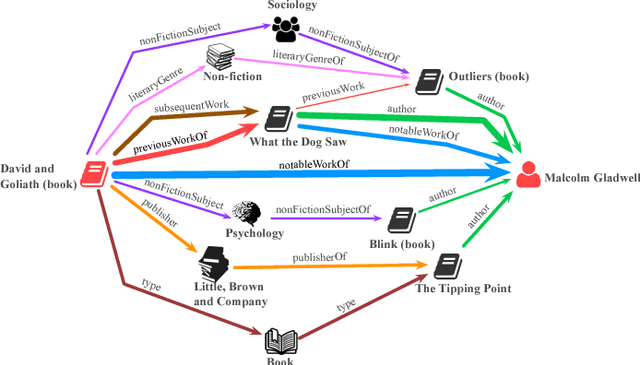

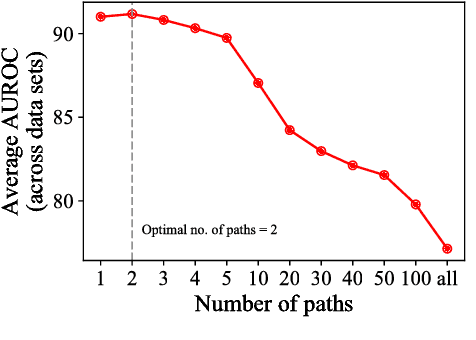
The volume and velocity of information that gets generated online limits current journalistic practices to fact-check claims at the same rate. Computational approaches for fact checking may be the key to help mitigate the risks of massive misinformation spread. Such approaches can be designed to not only be scalable and effective at assessing veracity of dubious claims, but also to boost a human fact checker's productivity by surfacing relevant facts and patterns to aid their analysis. To this end, we present a novel, unsupervised network-flow based approach to determine the truthfulness of a statement of fact expressed in the form of a (subject, predicate, object) triple. We view a knowledge graph of background information about real-world entities as a flow network, and knowledge as a fluid, abstract commodity. We show that computational fact checking of such a triple then amounts to finding a "knowledge stream" that emanates from the subject node and flows toward the object node through paths connecting them. Evaluation on a range of real-world and hand-crafted datasets of facts related to entertainment, business, sports, geography and more reveals that this network-flow model can be very effective in discerning true statements from false ones, outperforming existing algorithms on many test cases. Moreover, the model is expressive in its ability to automatically discover several useful path patterns and surface relevant facts that may help a human fact checker corroborate or refute a claim.
Predicting online extremism, content adopters, and interaction reciprocity
May 02, 2016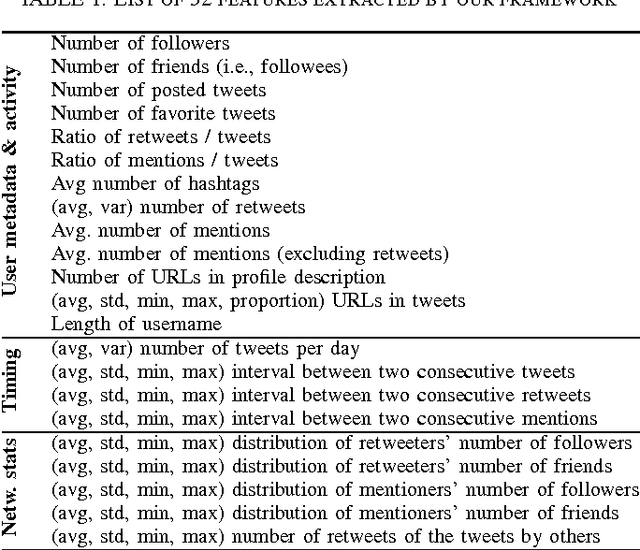
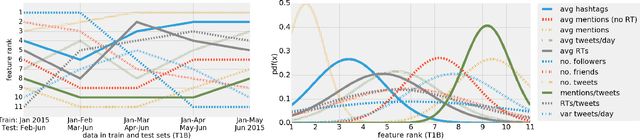
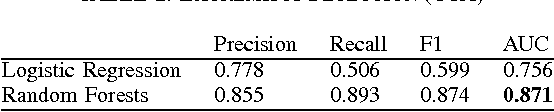
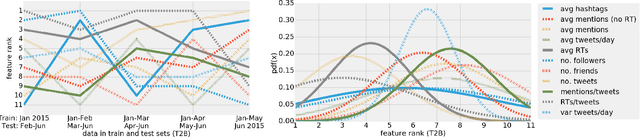
We present a machine learning framework that leverages a mixture of metadata, network, and temporal features to detect extremist users, and predict content adopters and interaction reciprocity in social media. We exploit a unique dataset containing millions of tweets generated by more than 25 thousand users who have been manually identified, reported, and suspended by Twitter due to their involvement with extremist campaigns. We also leverage millions of tweets generated by a random sample of 25 thousand regular users who were exposed to, or consumed, extremist content. We carry out three forecasting tasks, (i) to detect extremist users, (ii) to estimate whether regular users will adopt extremist content, and finally (iii) to predict whether users will reciprocate contacts initiated by extremists. All forecasting tasks are set up in two scenarios: a post hoc (time independent) prediction task on aggregated data, and a simulated real-time prediction task. The performance of our framework is extremely promising, yielding in the different forecasting scenarios up to 93% AUC for extremist user detection, up to 80% AUC for content adoption prediction, and finally up to 72% AUC for interaction reciprocity forecasting. We conclude by providing a thorough feature analysis that helps determine which are the emerging signals that provide predictive power in different scenarios.
* 9 pages, 3 figures, 8 tables
The DARPA Twitter Bot Challenge
Apr 21, 2016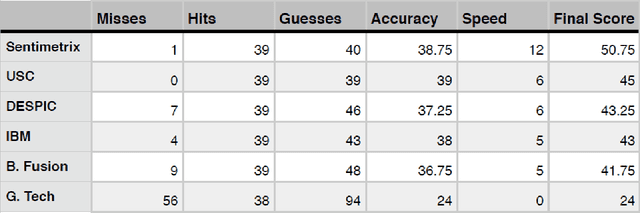
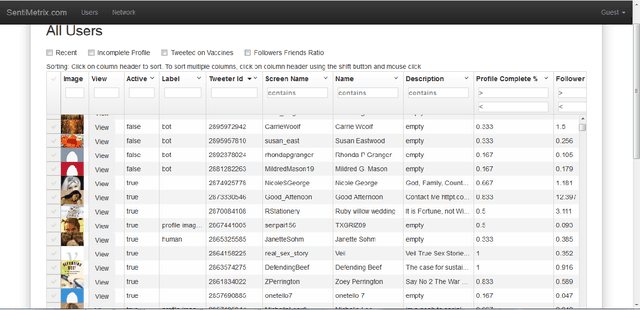
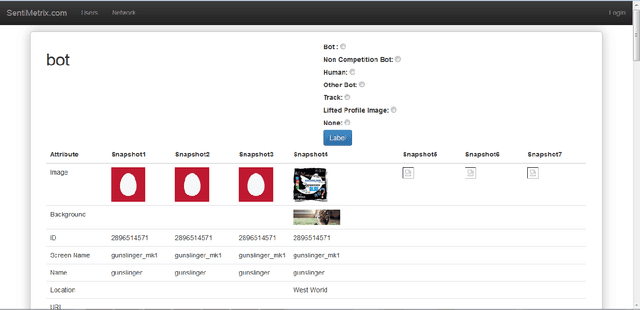
A number of organizations ranging from terrorist groups such as ISIS to politicians and nation states reportedly conduct explicit campaigns to influence opinion on social media, posing a risk to democratic processes. There is thus a growing need to identify and eliminate "influence bots" - realistic, automated identities that illicitly shape discussion on sites like Twitter and Facebook - before they get too influential. Spurred by such events, DARPA held a 4-week competition in February/March 2015 in which multiple teams supported by the DARPA Social Media in Strategic Communications program competed to identify a set of previously identified "influence bots" serving as ground truth on a specific topic within Twitter. Past work regarding influence bots often has difficulty supporting claims about accuracy, since there is limited ground truth (though some exceptions do exist [3,7]). However, with the exception of [3], no past work has looked specifically at identifying influence bots on a specific topic. This paper describes the DARPA Challenge and describes the methods used by the three top-ranked teams.
* IEEE Computer Magazine, in press
On predictability of rare events leveraging social media: a machine learning perspective
Feb 20, 2015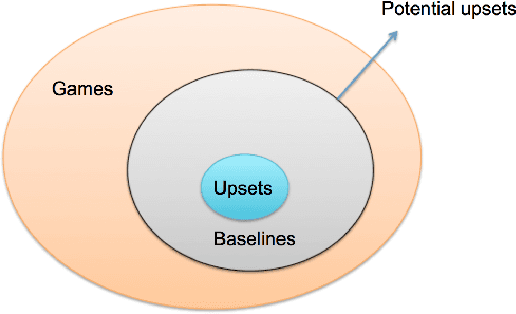
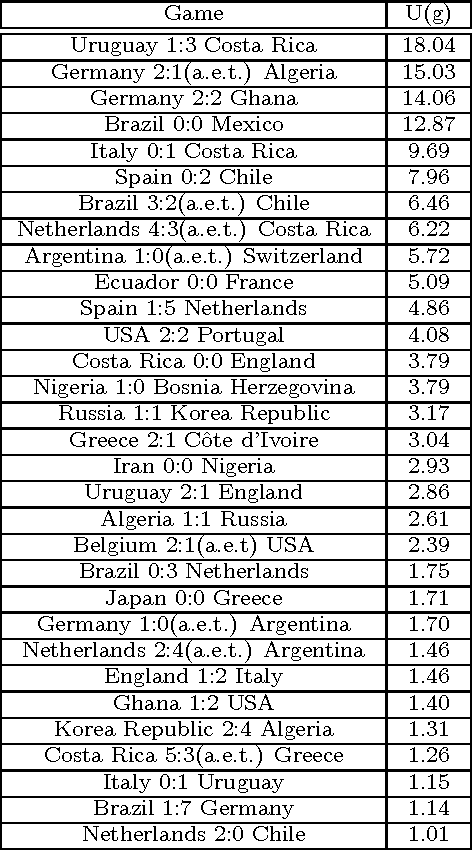
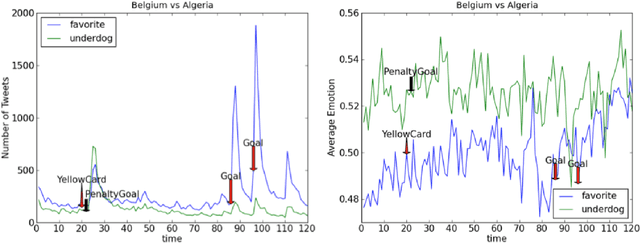
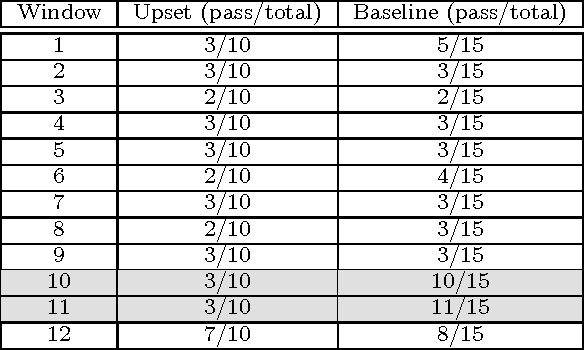
Information extracted from social media streams has been leveraged to forecast the outcome of a large number of real-world events, from political elections to stock market fluctuations. An increasing amount of studies demonstrates how the analysis of social media conversations provides cheap access to the wisdom of the crowd. However, extents and contexts in which such forecasting power can be effectively leveraged are still unverified at least in a systematic way. It is also unclear how social-media-based predictions compare to those based on alternative information sources. To address these issues, here we develop a machine learning framework that leverages social media streams to automatically identify and predict the outcomes of soccer matches. We focus in particular on matches in which at least one of the possible outcomes is deemed as highly unlikely by professional bookmakers. We argue that sport events offer a systematic approach for testing the predictive power of social media, and allow to compare such power against the rigorous baselines set by external sources. Despite such strict baselines, our framework yields above 8% marginal profit when used to inform simple betting strategies. The system is based on real-time sentiment analysis and exploits data collected immediately before the games, allowing for informed bets. We discuss the rationale behind our approach, describe the learning framework, its prediction performance and the return it provides as compared to a set of betting strategies. To test our framework we use both historical Twitter data from the 2014 FIFA World Cup games, and real-time Twitter data collected by monitoring the conversations about all soccer matches of four major European tournaments (FA Premier League, Serie A, La Liga, and Bundesliga), and the 2014 UEFA Champions League, during the period between Oct. 25th 2014 and Nov. 26th 2014.
* 10 pages, 10 tables, 8 figures
Clustering memes in social media streams
Nov 03, 2014
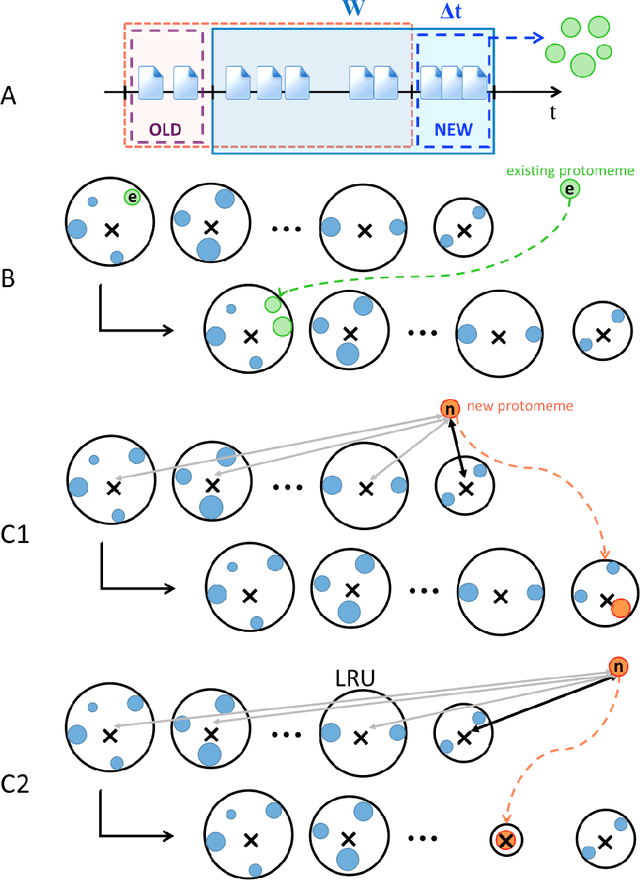
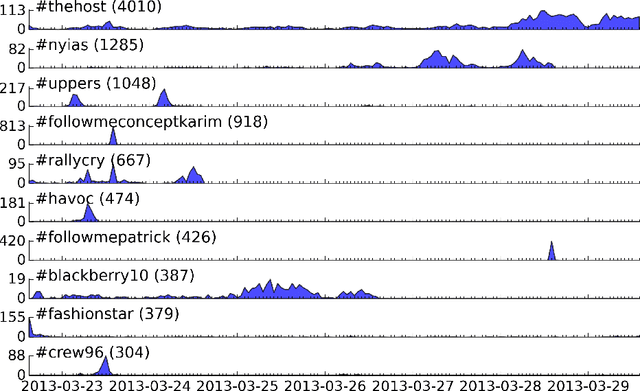
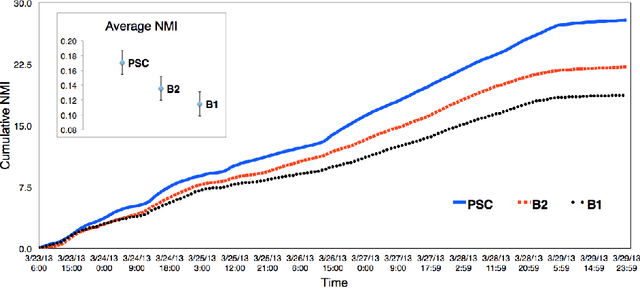
The problem of clustering content in social media has pervasive applications, including the identification of discussion topics, event detection, and content recommendation. Here we describe a streaming framework for online detection and clustering of memes in social media, specifically Twitter. A pre-clustering procedure, namely protomeme detection, first isolates atomic tokens of information carried by the tweets. Protomemes are thereafter aggregated, based on multiple similarity measures, to obtain memes as cohesive groups of tweets reflecting actual concepts or topics of discussion. The clustering algorithm takes into account various dimensions of the data and metadata, including natural language, the social network, and the patterns of information diffusion. As a result, our system can build clusters of semantically, structurally, and topically related tweets. The clustering process is based on a variant of Online K-means that incorporates a memory mechanism, used to "forget" old memes and replace them over time with the new ones. The evaluation of our framework is carried out by using a dataset of Twitter trending topics. Over a one-week period, we systematically determined whether our algorithm was able to recover the trending hashtags. We show that the proposed method outperforms baseline algorithms that only use content features, as well as a state-of-the-art event detection method that assumes full knowledge of the underlying follower network. We finally show that our online learning framework is flexible, due to its independence of the adopted clustering algorithm, and best suited to work in a streaming scenario.
* 25 pages, 8 figures, accepted on Social Network Analysis and Mining (SNAM). The final publication is available at Springer via http://dx.doi.org/10.1007/s13278-014-0237-x
Beyond Zipf's law: Modeling the structure of human language
Feb 03, 2009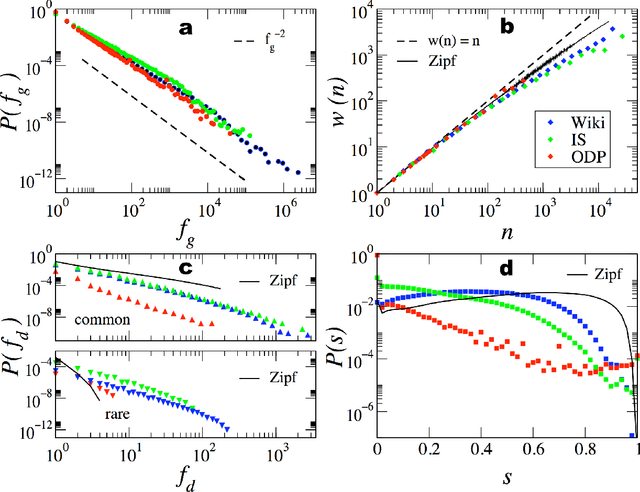
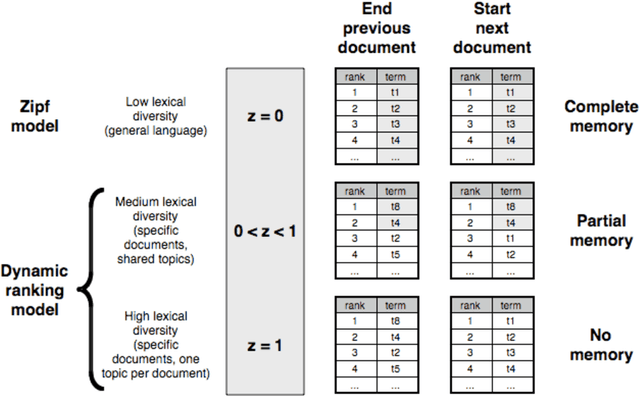
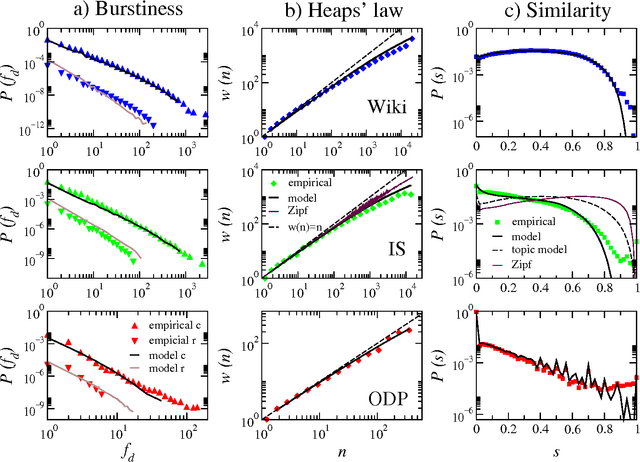
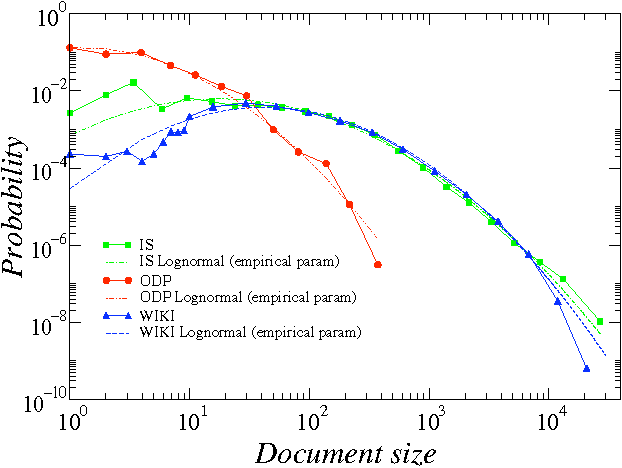
Human language, the most powerful communication system in history, is closely associated with cognition. Written text is one of the fundamental manifestations of language, and the study of its universal regularities can give clues about how our brains process information and how we, as a society, organize and share it. Still, only classical patterns such as Zipf's law have been explored in depth. In contrast, other basic properties like the existence of bursts of rare words in specific documents, the topical organization of collections, or the sublinear growth of vocabulary size with the length of a document, have only been studied one by one and mainly applying heuristic methodologies rather than basic principles and general mechanisms. As a consequence, there is a lack of understanding of linguistic processes as complex emergent phenomena. Beyond Zipf's law for word frequencies, here we focus on Heaps' law, burstiness, and the topicality of document collections, which encode correlations within and across documents absent in random null models. We introduce and validate a generative model that explains the simultaneous emergence of all these patterns from simple rules. As a result, we find a connection between the bursty nature of rare words and the topical organization of texts and identify dynamic word ranking and memory across documents as key mechanisms explaining the non trivial organization of written text. Our research can have broad implications and practical applications in computer science, cognitive science, and linguistics.