 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward a Physics of Deep Learning and Brains
Sep 26, 2025
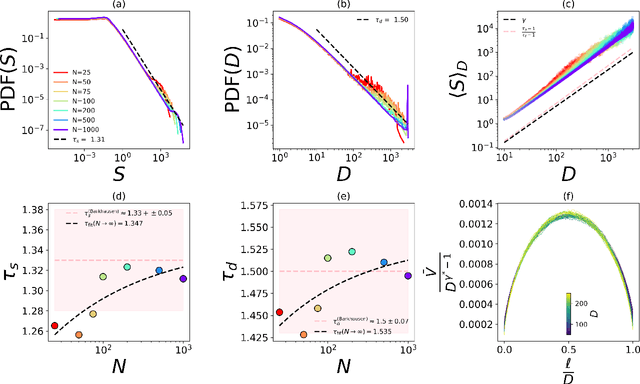


Deep neural networks and brains both learn and share superficial similarities: processing nodes are likened to neurons and adjustable weights are likened to modifiable synapses. But can a unified theoretical framework be found to underlie them both? Here we show that the equations used to describe neuronal avalanches in living brains can also be applied to cascades of activity in deep neural networks. These equations are derived from non-equilibrium statistical physics and show that deep neural networks learn best when poised between absorbing and active phases. Because these networks are strongly driven by inputs, however, they do not operate at a true critical point but within a quasi-critical regime -- one that still approximately satisfies crackling noise scaling relations. By training networks with different initializations, we show that maximal susceptibility is a more reliable predictor of learning than proximity to the critical point itself. This provides a blueprint for engineering improved network performance. Finally, using finite-size scaling we identify distinct universality classes, including Barkhausen noise and directed percolation. This theoretical framework demonstrates that universal features are shared by both biological and artificial neural networks.
Task complexity shapes internal representations and robustness in neural networks
Aug 07, 2025Neural networks excel across a wide range of tasks, yet remain black boxes. In particular, how their internal representations are shaped by the complexity of the input data and the problems they solve remains obscure. In this work, we introduce a suite of five data-agnostic probes-pruning, binarization, noise injection, sign flipping, and bipartite network randomization-to quantify how task difficulty influences the topology and robustness of representations in multilayer perceptrons (MLPs). MLPs are represented as signed, weighted bipartite graphs from a network science perspective. We contrast easy and hard classification tasks on the MNIST and Fashion-MNIST datasets. We show that binarizing weights in hard-task models collapses accuracy to chance, whereas easy-task models remain robust. We also find that pruning low-magnitude edges in binarized hard-task models reveals a sharp phase-transition in performance. Moreover, moderate noise injection can enhance accuracy, resembling a stochastic-resonance effect linked to optimal sign flips of small-magnitude weights. Finally, preserving only the sign structure-instead of precise weight magnitudes-through bipartite network randomizations suffices to maintain high accuracy. These phenomena define a model- and modality-agnostic measure of task complexity: the performance gap between full-precision and binarized or shuffled neural network performance. Our findings highlight the crucial role of signed bipartite topology in learned representations and suggest practical strategies for model compression and interpretability that align with task complexity.
Parallel Algorithms for Median Consensus Clustering in Complex Networks
Aug 21, 2024We develop an algorithm that finds the consensus of many different clustering solutions of a graph. We formulate the problem as a median set partitioning problem and propose a greedy optimization technique. Unlike other approaches that find median set partitions, our algorithm takes graph structure into account and finds a comparable quality solution much faster than the other approaches. For graphs with known communities, our consensus partition captures the actual community structure more accurately than alternative approaches. To make it applicable to large graphs, we remove sequential dependencies from our algorithm and design a parallel algorithm. Our parallel algorithm achieves 35x speedup when utilizing 64 processing cores for large real-world graphs from single-cell experiments.
20 years of network community detection
Aug 02, 2022A fundamental technical challenge in the analysis of network data is the automated discovery of communities - groups of nodes that are strongly connected or that share similar features or roles. In this commentary we review progress in the field over the last 20 years.
Robustness modularity in complex networks
Oct 05, 2021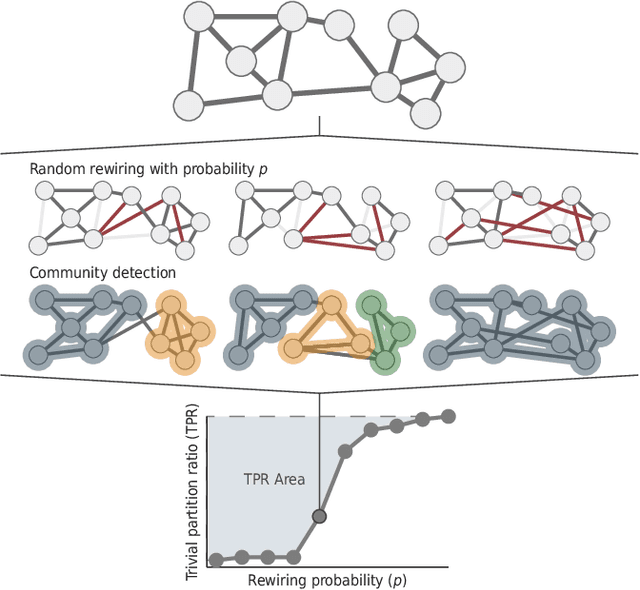
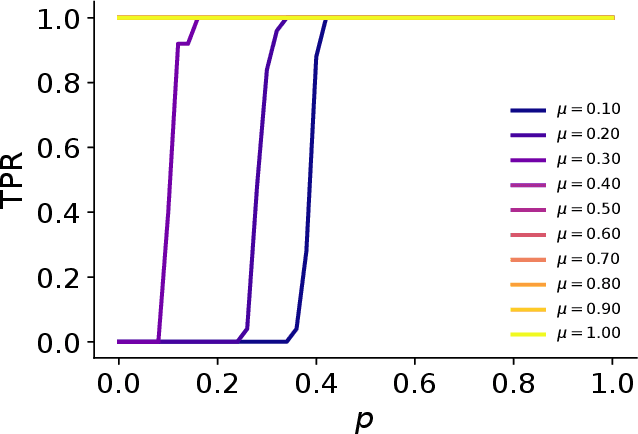
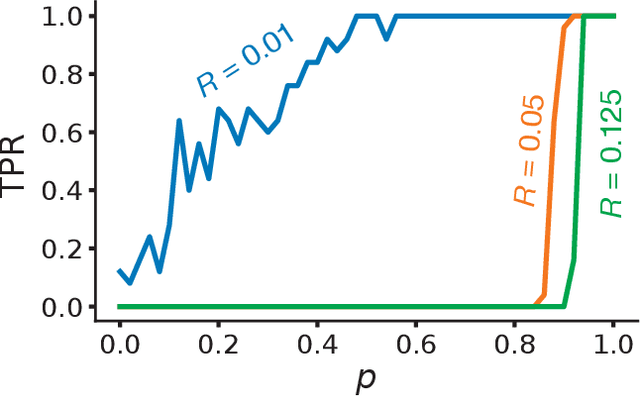
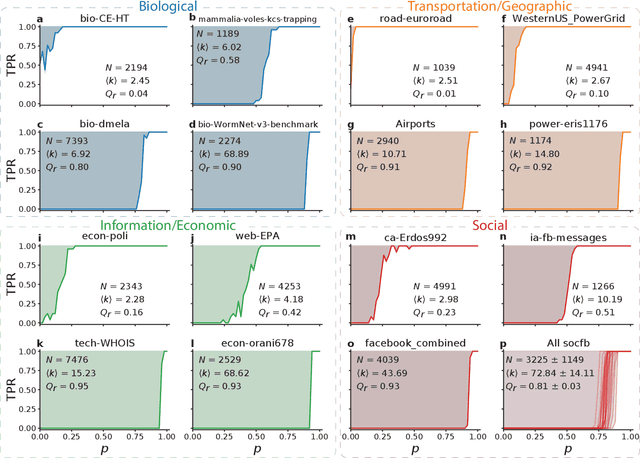
A basic question in network community detection is how modular a given network is. This is usually addressed by evaluating the quality of partitions detected in the network. The Girvan-Newman (GN) modularity function is the standard way to make this assessment, but it has a number of drawbacks. Most importantly, it is not clearly interpretable, given that the measure can take relatively large values on partitions of random networks without communities. Here we propose a new measure based on the concept of robustness: modularity is the probability to find trivial partitions when the structure of the network is randomly perturbed. This concept can be implemented for any clustering algorithm capable of telling when a group structure is absent. Tests on artificial and real graphs reveal that robustness modularity can be used to assess and compare the strength of the community structure of different networks. We also introduce two other quality functions: modularity difference, a suitably normalized version of the GN modularity; information modularity, a measure of distance based on information compression. Both measures are strongly correlated with robustness modularity, and are promising options as well.
Community detection in networks using graph embeddings
Sep 11, 2020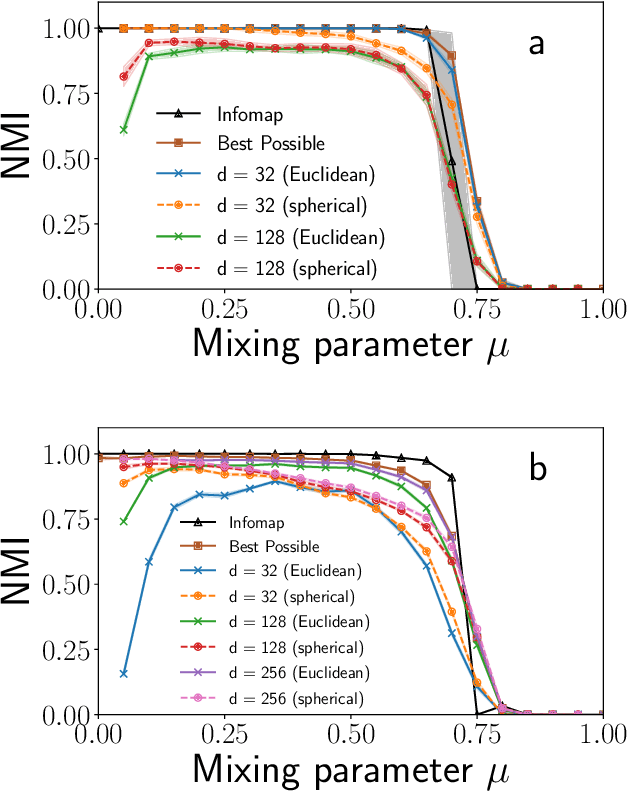
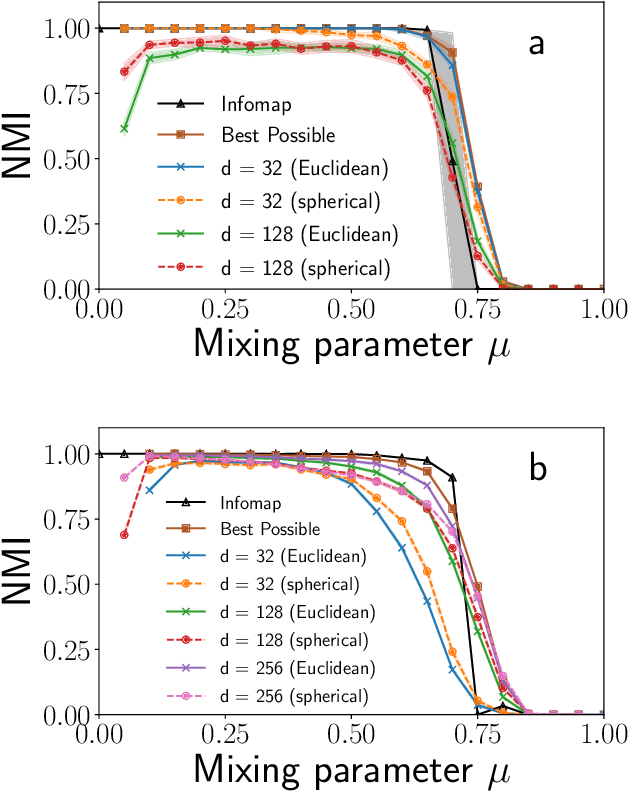
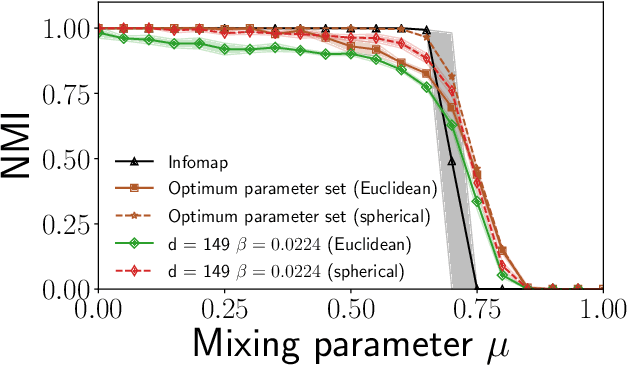
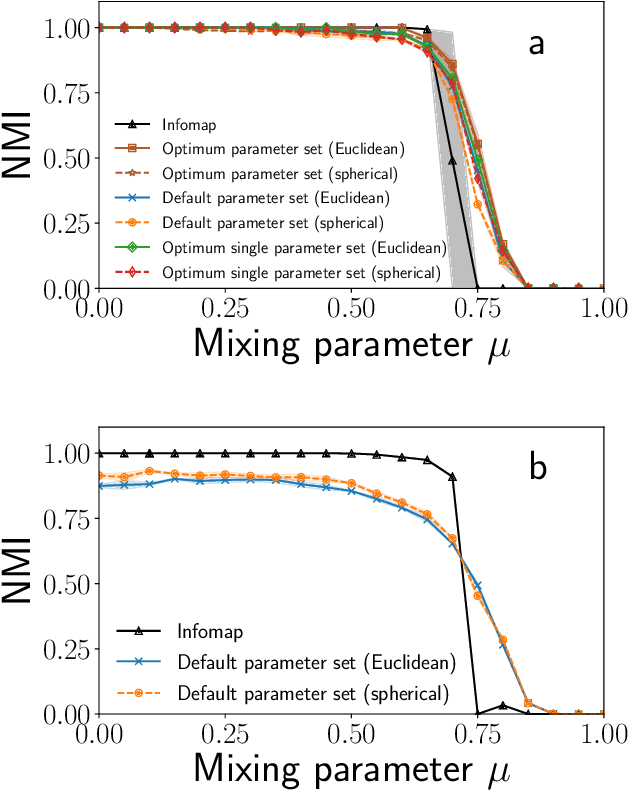
Graph embedding methods are becoming increasingly popular in the machine learning community, where they are widely used for tasks such as node classification and link prediction. Embedding graphs in geometric spaces should aid the identification of network communities as well, because nodes in the same community should be projected close to each other in the geometric space, where they can be detected via standard data clustering algorithms. In this paper, we test the ability of several graph embedding techniques to detect communities on benchmark graphs. We compare their performance against that of traditional community detection algorithms. We find that the performance is comparable, if the parameters of the embedding techniques are suitably chosen. However, the optimal parameter set varies with the specific features of the benchmark graphs, like their size, whereas popular community detection algorithms do not require any parameter. So it is not possible to indicate beforehand good parameter sets for the analysis of real networks. This finding, along with the high computational cost of embedding a network and grouping the points, suggests that, for community detection, current embedding techniques do not represent an improvement over network clustering algorithms.
Recency predicts bursts in the evolution of author citations
Nov 27, 2019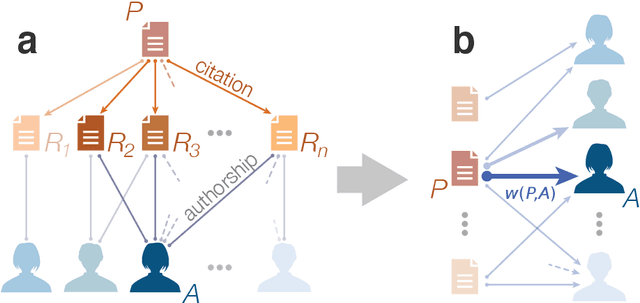
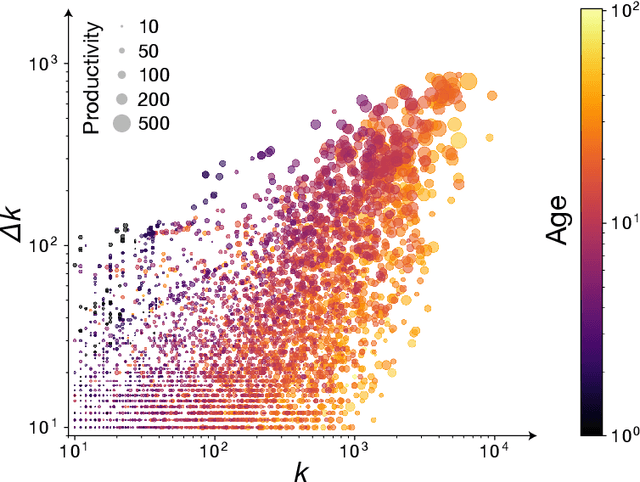
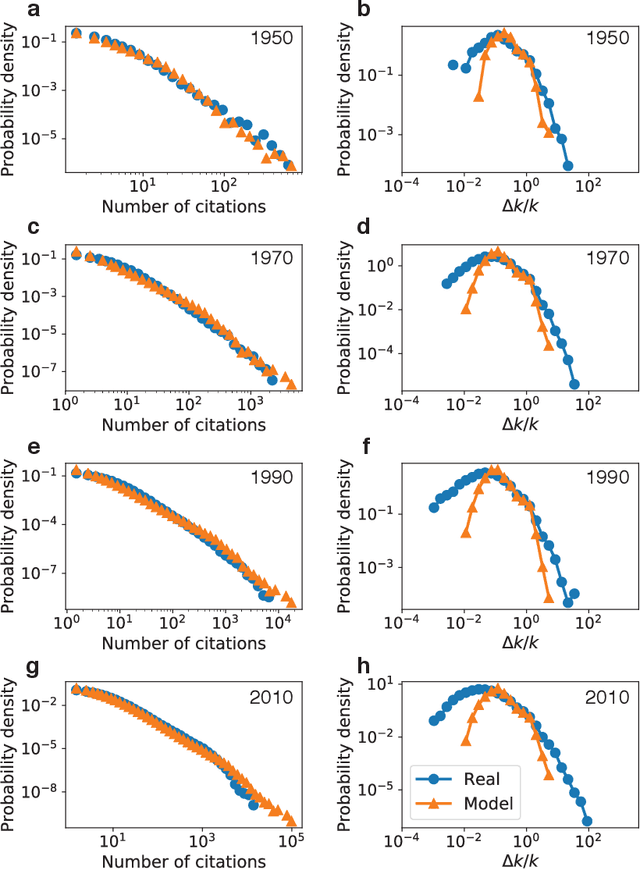
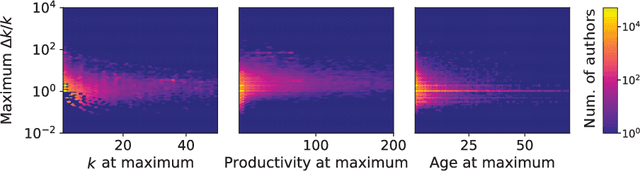
The citations process for scientific papers has been studied extensively. But while the citations accrued by authors are the sum of the citations of their papers, translating the dynamics of citation accumulation from the paper to the author level is not trivial. Here we conduct a systematic study of the evolution of author citations, and in particular their bursty dynamics. We find empirical evidence of a correlation between the number of citations most recently accrued by an author and the number of citations they receive in the future. Using a simple model where the probability for an author to receive new citations depends only on the number of citations collected in the previous 12-24 months, we are able to reproduce both the citation and burst size distributions of authors across multiple decades.
Psychological and Personality Profiles of Political Extremists
Apr 01, 2017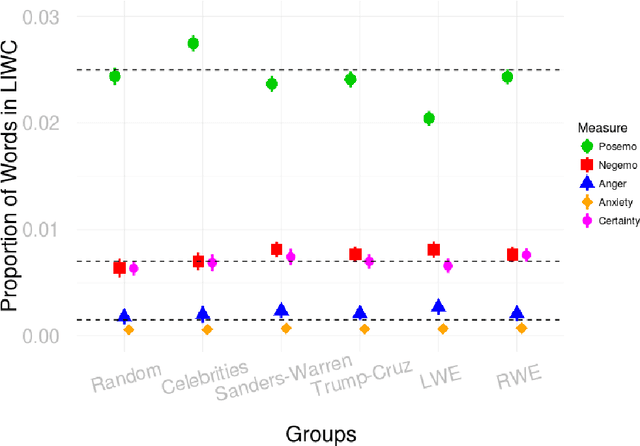
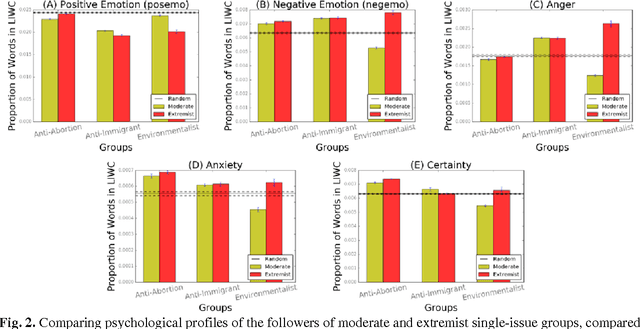
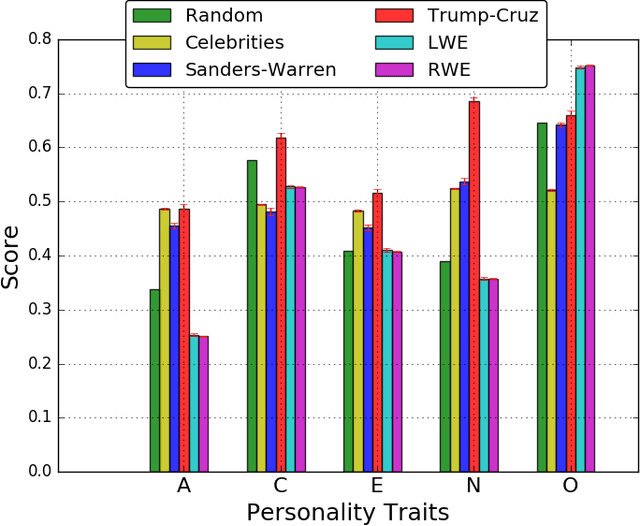
Global recruitment into radical Islamic movements has spurred renewed interest in the appeal of political extremism. Is the appeal a rational response to material conditions or is it the expression of psychological and personality disorders associated with aggressive behavior, intolerance, conspiratorial imagination, and paranoia? Empirical answers using surveys have been limited by lack of access to extremist groups, while field studies have lacked psychological measures and failed to compare extremists with contrast groups. We revisit the debate over the appeal of extremism in the U.S. context by comparing publicly available Twitter messages written by over 355,000 political extremist followers with messages written by non-extremist U.S. users. Analysis of text-based psychological indicators supports the moral foundation theory which identifies emotion as a critical factor in determining political orientation of individuals. Extremist followers also differ from others in four of the Big Five personality traits.
Network structure, metadata and the prediction of missing nodes and annotations
Sep 29, 2016



The empirical validation of community detection methods is often based on available annotations on the nodes that serve as putative indicators of the large-scale network structure. Most often, the suitability of the annotations as topological descriptors itself is not assessed, and without this it is not possible to ultimately distinguish between actual shortcomings of the community detection algorithms on one hand, and the incompleteness, inaccuracy or structured nature of the data annotations themselves on the other. In this work we present a principled method to access both aspects simultaneously. We construct a joint generative model for the data and metadata, and a nonparametric Bayesian framework to infer its parameters from annotated datasets. We assess the quality of the metadata not according to its direct alignment with the network communities, but rather in its capacity to predict the placement of edges in the network. We also show how this feature can be used to predict the connections to missing nodes when only the metadata is available, as well as missing metadata. By investigating a wide range of datasets, we show that while there are seldom exact agreements between metadata tokens and the inferred data groups, the metadata is often informative of the network structure nevertheless, and can improve the prediction of missing nodes. This shows that the method uncovers meaningful patterns in both the data and metadata, without requiring or expecting a perfect agreement between the two.
* 15 pages, 6 figures, 1 table