 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging GANs for citation intent classification and its impact on citation network analysis
May 27, 2025Citations play a fundamental role in the scientific ecosystem, serving as a foundation for tracking the flow of knowledge, acknowledging prior work, and assessing scholarly influence. In scientometrics, they are also central to the construction of quantitative indicators. Not all citations, however, serve the same function: some provide background, others introduce methods, or compare results. Therefore, understanding citation intent allows for a more nuanced interpretation of scientific impact. In this paper, we adopted a GAN-based method to classify citation intents. Our results revealed that the proposed method achieves competitive classification performance, closely matching state-of-the-art results with substantially fewer parameters. This demonstrates the effectiveness and efficiency of leveraging GAN architectures combined with contextual embeddings in intent classification task. We also investigated whether filtering citation intents affects the centrality of papers in citation networks. Analyzing the network constructed from the unArXiv dataset, we found that paper rankings can be significantly influenced by citation intent. All four centrality metrics examined- degree, PageRank, closeness, and betweenness - were sensitive to the filtering of citation types. The betweenness centrality displayed the greatest sensitivity, showing substantial changes in ranking when specific citation intents were removed.
Using Full-Text Content to Characterize and Identify Best Seller Books
Oct 05, 2022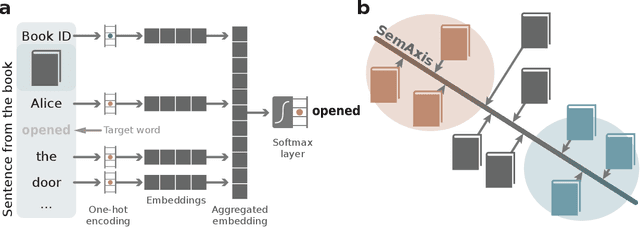
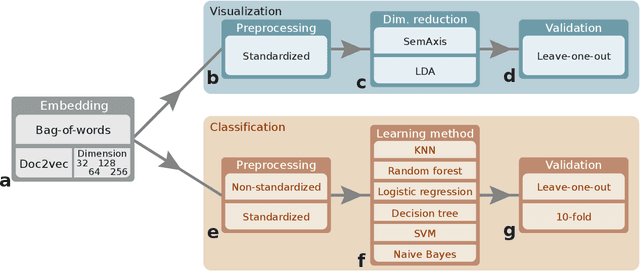


Artistic pieces can be studied from several perspectives, one example being their reception among readers over time. In the present work, we approach this interesting topic from the standpoint of literary works, particularly assessing the task of predicting whether a book will become a best seller. Dissimilarly from previous approaches, we focused on the full content of books and considered visualization and classification tasks. We employed visualization for the preliminary exploration of the data structure and properties, involving SemAxis and linear discriminant analyses. Then, to obtain quantitative and more objective results, we employed various classifiers. Such approaches were used along with a dataset containing (i) books published from 1895 to 1924 and consecrated as best sellers by the \emph{Publishers Weekly Bestseller Lists} and (ii) literary works published in the same period but not being mentioned in that list. Our comparison of methods revealed that the best-achieved result - combining a bag-of-words representation with a logistic regression classifier - led to an average accuracy of 0.75 both for the leave-one-out and 10-fold cross-validations. Such an outcome suggests that it is unfeasible to predict the success of books with high accuracy using only the full content of the texts. Nevertheless, our findings provide insights into the factors leading to the relative success of a literary work.
Classification of network topology and dynamics via sequence characterization
Jun 30, 2022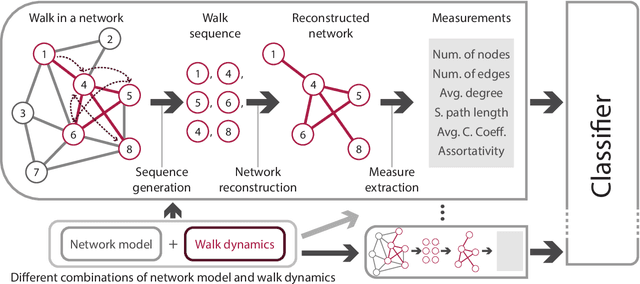
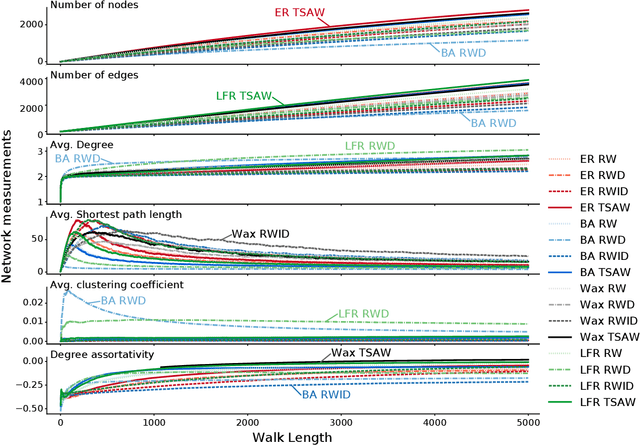
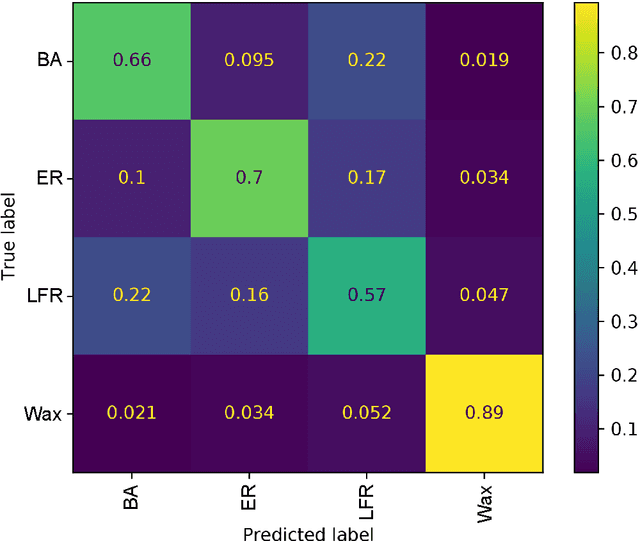
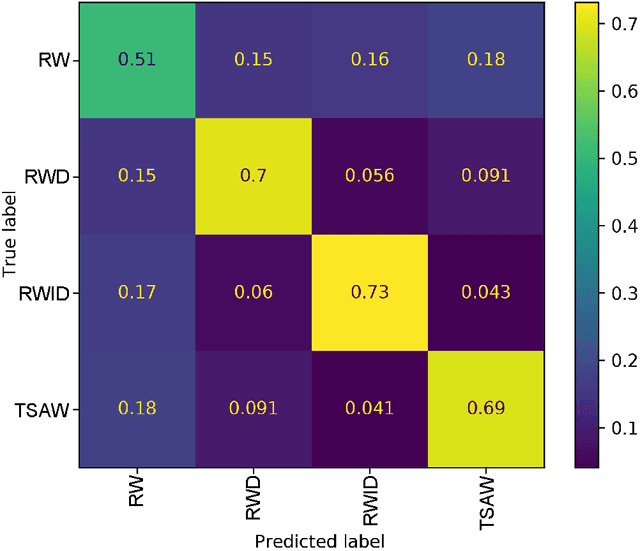
Sequences arise in many real-world scenarios; thus, identifying the mechanisms behind symbol generation is essential to understanding many complex systems. This paper analyzes sequences generated by agents walking on a networked topology. Given that in many real scenarios, the underlying processes generating the sequence is hidden, we investigate whether the reconstruction of the network via the co-occurrence method is useful to recover both the network topology and agent dynamics generating sequences. We found that the characterization of reconstructed networks provides valuable information regarding the process and topology used to create the sequences. In a machine learning approach considering 16 combinations of network topology and agent dynamics as classes, we obtained an accuracy of 87% with sequences generated with less than 40% of nodes visited. Larger sequences turned out to generate improved machine learning models. Our findings suggest that the proposed methodology could be extended to classify sequences and understand the mechanisms behind sequence generation.
Accessibility and Trajectory-Based Text Characterization
Jan 17, 2022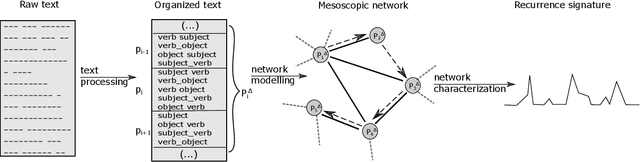
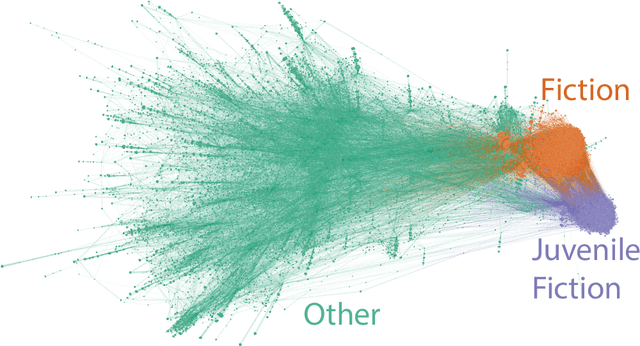
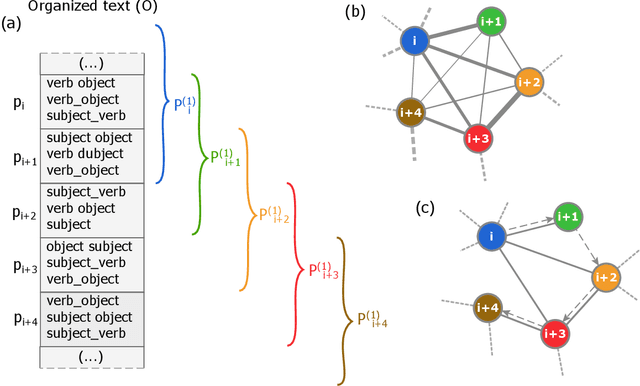
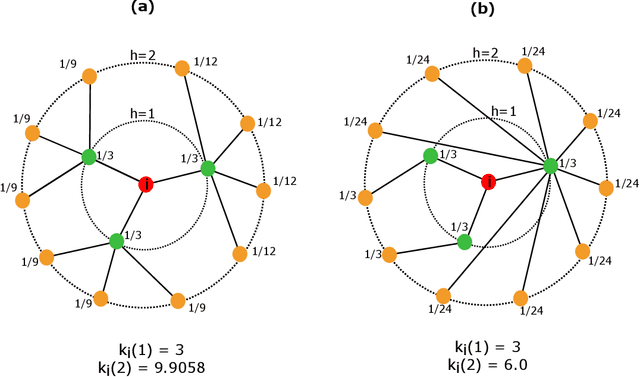
Several complex systems are characterized by presenting intricate characteristics extending along many scales. These characterizations are used in various applications, including text classification, better understanding of diseases, and comparison between cities, among others. In particular, texts are also characterized by a hierarchical structure that can be approached by using multi-scale concepts and methods. The present work aims at developing these possibilities while focusing on mesoscopic representations of networks. More specifically, we adopt an extension to the mesoscopic approach to represent text narratives, in which only the recurrent relationships among tagged parts of speech are considered to establish connections among sequential pieces of text (e.g., paragraphs). The characterization of the texts was then achieved by considering scale-dependent complementary methods: accessibility, symmetry and recurrence signatures. In order to evaluate the potential of these concepts and methods, we approached the problem of distinguishing between literary genres (fiction and non-fiction). A set of 300 books organized into the two genres was considered and were compared by using the aforementioned approaches. All the methods were capable of differentiating to some extent between the two genres. The accessibility and symmetry reflected the narrative asymmetries, while the recurrence signature provide a more direct indication about the non-sequential semantic connections taking place along the narrative.
Robustness modularity in complex networks
Oct 05, 2021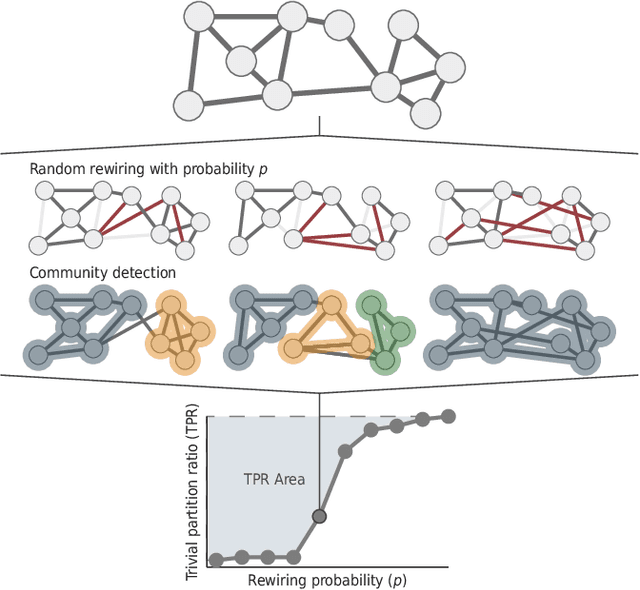
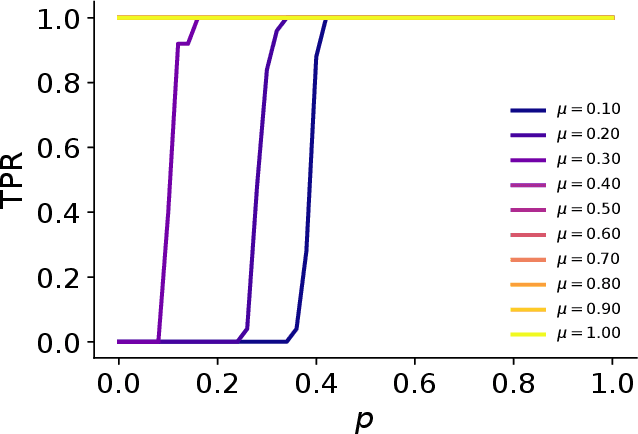
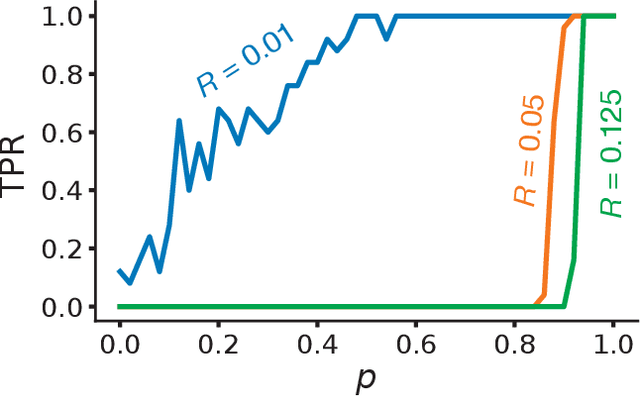
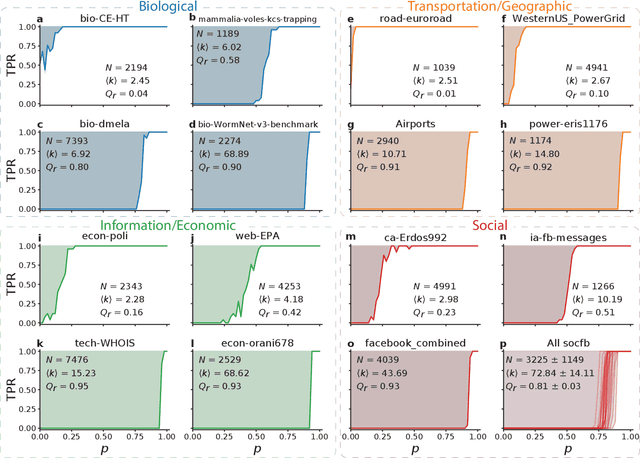
A basic question in network community detection is how modular a given network is. This is usually addressed by evaluating the quality of partitions detected in the network. The Girvan-Newman (GN) modularity function is the standard way to make this assessment, but it has a number of drawbacks. Most importantly, it is not clearly interpretable, given that the measure can take relatively large values on partitions of random networks without communities. Here we propose a new measure based on the concept of robustness: modularity is the probability to find trivial partitions when the structure of the network is randomly perturbed. This concept can be implemented for any clustering algorithm capable of telling when a group structure is absent. Tests on artificial and real graphs reveal that robustness modularity can be used to assess and compare the strength of the community structure of different networks. We also introduce two other quality functions: modularity difference, a suitably normalized version of the GN modularity; information modularity, a measure of distance based on information compression. Both measures are strongly correlated with robustness modularity, and are promising options as well.
A pattern recognition approach for distinguishing between prose and poetry
Jul 18, 2021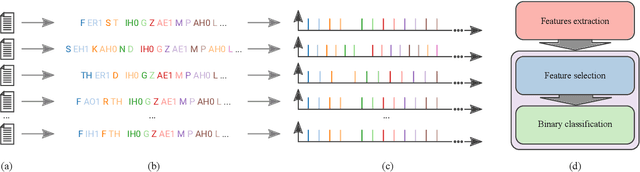
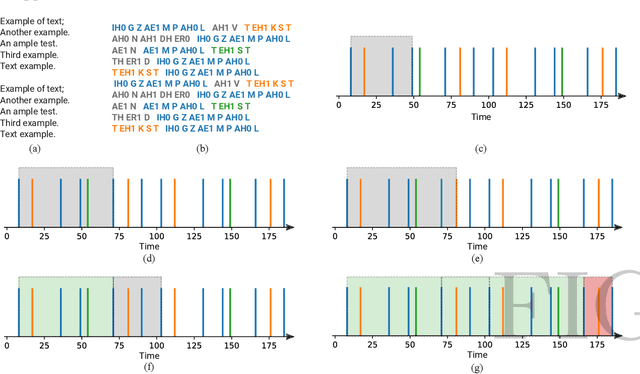


Poetry and prose are written artistic expressions that help us to appreciate the reality we live. Each of these styles has its own set of subjective properties, such as rhyme and rhythm, which are easily caught by a human reader's eye and ear. With the recent advances in artificial intelligence, the gap between humans and machines may have decreased, and today we observe algorithms mastering tasks that were once exclusively performed by humans. In this paper, we propose an automated method to distinguish between poetry and prose based solely on aural and rhythmic properties. In other to compare prose and poetry rhythms, we represent the rhymes and phones as temporal sequences and thus we propose a procedure for extracting rhythmic features from these sequences. The classification of the considered texts using the set of features extracted resulted in a best accuracy of 0.78, obtained with a neural network. Interestingly, by using an approach based on complex networks to visualize the similarities between the different texts considered, we found that the patterns of poetry vary much more than prose. Consequently, a much richer and complex set of rhythmic possibilities tends to be found in that modality.
Representation of texts as complex networks: a mesoscopic approach
Feb 25, 2017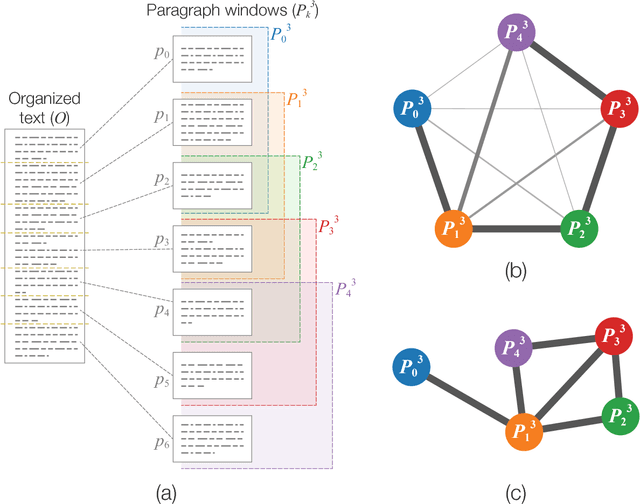
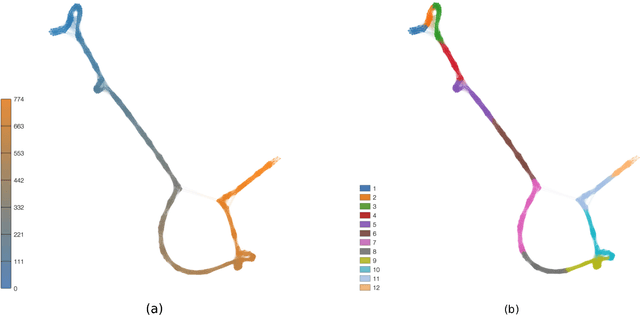
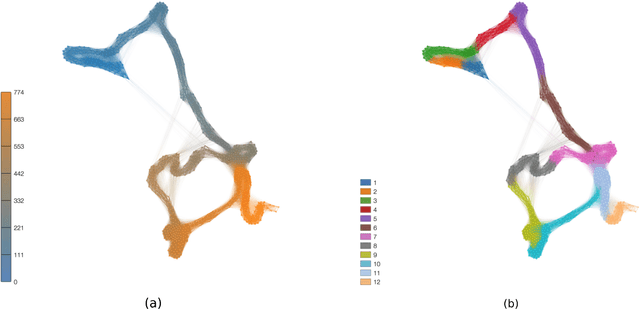
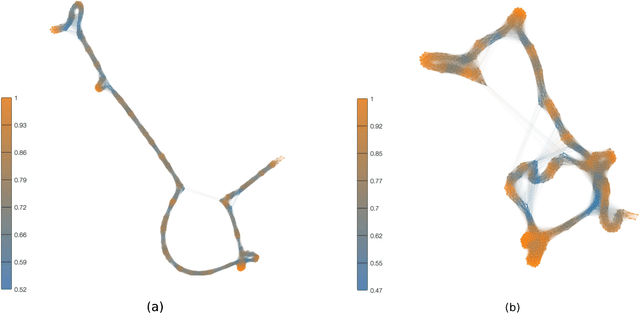
Statistical techniques that analyze texts, referred to as text analytics, have departed from the use of simple word count statistics towards a new paradigm. Text mining now hinges on a more sophisticated set of methods, including the representations in terms of complex networks. While well-established word-adjacency (co-occurrence) methods successfully grasp syntactical features of written texts, they are unable to represent important aspects of textual data, such as its topical structure, i.e. the sequence of subjects developing at a mesoscopic level along the text. Such aspects are often overlooked by current methodologies. In order to grasp the mesoscopic characteristics of semantical content in written texts, we devised a network model which is able to analyze documents in a multi-scale fashion. In the proposed model, a limited amount of adjacent paragraphs are represented as nodes, which are connected whenever they share a minimum semantical content. To illustrate the capabilities of our model, we present, as a case example, a qualitative analysis of "Alice's Adventures in Wonderland". We show that the mesoscopic structure of a document, modeled as a network, reveals many semantic traits of texts. Such an approach paves the way to a myriad of semantic-based applications. In addition, our approach is illustrated in a machine learning context, in which texts are classified among real texts and randomized instances.
Complex systems: features, similarity and connectivity
Jun 17, 2016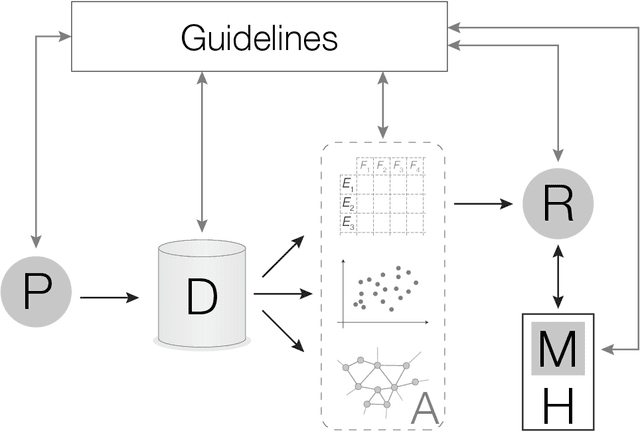
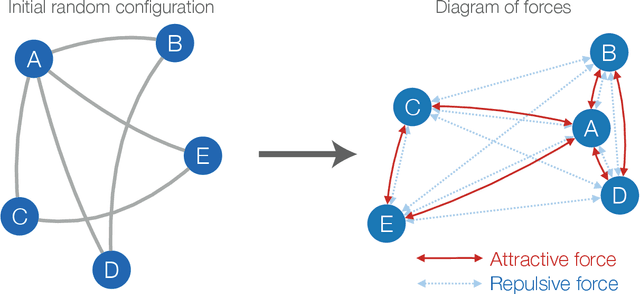
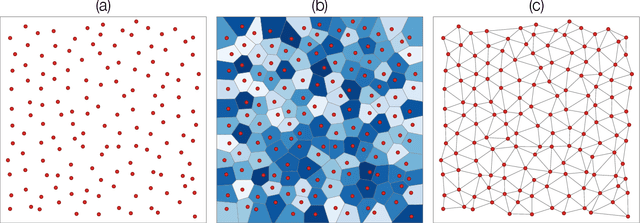
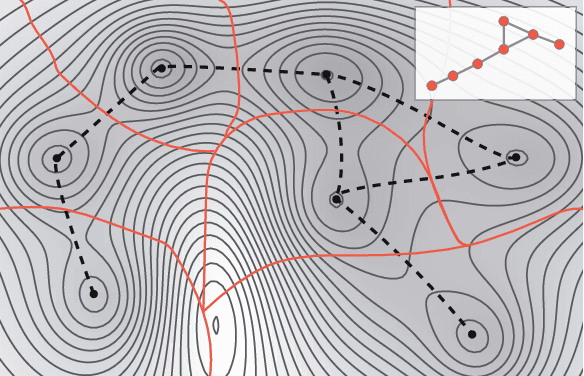
The increasing interest in complex networks research has been a consequence of several intrinsic features of this area, such as the generality of the approach to represent and model virtually any discrete system, and the incorporation of concepts and methods deriving from many areas, from statistical physics to sociology, which are often used in an independent way. Yet, for this same reason, it would be desirable to integrate these various aspects into a more coherent and organic framework, which would imply in several benefits normally allowed by the systematization in science, including the identification of new types of problems and the cross-fertilization between fields. More specifically, the identification of the main areas to which the concepts frequently used in complex networks can be applied paves the way to adopting and applying a larger set of concepts and methods deriving from those respective areas. Among the several areas that have been used in complex networks research, pattern recognition, optimization, linear algebra, and time series analysis seem to play a more basic and recurrent role. In the present manuscript, we propose a systematic way to integrate the concepts from these diverse areas regarding complex networks research. In order to do so, we start by grouping the multidisciplinary concepts into three main groups, namely features, similarity, and network connectivity. Then we show that several of the analysis and modeling approaches to complex networks can be thought as a composition of maps between these three groups, with emphasis on nine main types of mappings, which are presented and illustrated. Such a systematization of principles and approaches also provides an opportunity to review some of the most closely related works in the literature, which is also developed in this article.
Concentric network symmetry grasps authors' styles in word adjacency networks
Jun 18, 2015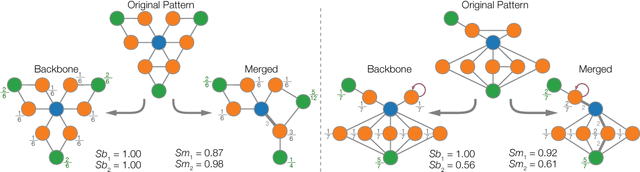
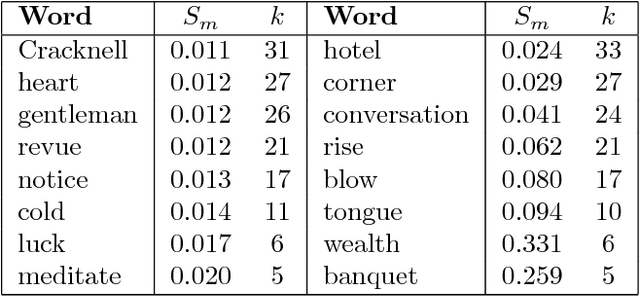
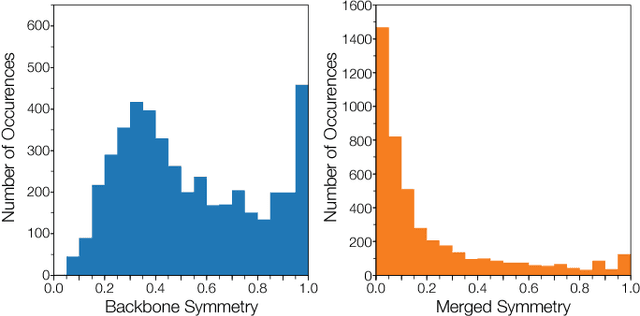

Several characteristics of written texts have been inferred from statistical analysis derived from networked models. Even though many network measurements have been adapted to study textual properties at several levels of complexity, some textual aspects have been disregarded. In this paper, we study the symmetry of word adjacency networks, a well-known representation of text as a graph. A statistical analysis of the symmetry distribution performed in several novels showed that most of the words do not display symmetric patterns of connectivity. More specifically, the merged symmetry displayed a distribution similar to the ubiquitous power-law distribution. Our experiments also revealed that the studied metrics do not correlate with other traditional network measurements, such as the degree or betweenness centrality. The effectiveness of the symmetry measurements was verified in the authorship attribution task. Interestingly, we found that specific authors prefer particular types of symmetric motifs. As a consequence, the authorship of books could be accurately identified in 82.5% of the cases, in a dataset comprising books written by 8 authors. Because the proposed measurements for text analysis are complementary to the traditional approach, they can be used to improve the characterization of text networks, which might be useful for related applications, such as those relying on the identification of topical words and information retrieval.
* Accepted for publication in Europhys. Lett. (EPL). The supplementary information is available from https://dl.dropboxusercontent.com/u/2740286/symmetry.pdf