 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging GANs for citation intent classification and its impact on citation network analysis
May 27, 2025Citations play a fundamental role in the scientific ecosystem, serving as a foundation for tracking the flow of knowledge, acknowledging prior work, and assessing scholarly influence. In scientometrics, they are also central to the construction of quantitative indicators. Not all citations, however, serve the same function: some provide background, others introduce methods, or compare results. Therefore, understanding citation intent allows for a more nuanced interpretation of scientific impact. In this paper, we adopted a GAN-based method to classify citation intents. Our results revealed that the proposed method achieves competitive classification performance, closely matching state-of-the-art results with substantially fewer parameters. This demonstrates the effectiveness and efficiency of leveraging GAN architectures combined with contextual embeddings in intent classification task. We also investigated whether filtering citation intents affects the centrality of papers in citation networks. Analyzing the network constructed from the unArXiv dataset, we found that paper rankings can be significantly influenced by citation intent. All four centrality metrics examined- degree, PageRank, closeness, and betweenness - were sensitive to the filtering of citation types. The betweenness centrality displayed the greatest sensitivity, showing substantial changes in ranking when specific citation intents were removed.
Graph machine learning for flight delay prediction due to holding manouver
Feb 06, 2025



Flight delays due to holding maneuvers are a critical and costly phenomenon in aviation, driven by the need to manage air traffic congestion and ensure safety. Holding maneuvers occur when aircraft are instructed to circle in designated airspace, often due to factors such as airport congestion, adverse weather, or air traffic control restrictions. This study models the prediction of flight delays due to holding maneuvers as a graph problem, leveraging advanced Graph Machine Learning (Graph ML) techniques to capture complex interdependencies in air traffic networks. Holding maneuvers, while crucial for safety, cause increased fuel usage, emissions, and passenger dissatisfaction, making accurate prediction essential for operational efficiency. Traditional machine learning models, typically using tabular data, often overlook spatial-temporal relations within air traffic data. To address this, we model the problem of predicting holding as edge feature prediction in a directed (multi)graph where we apply both CatBoost, enriched with graph features capturing network centrality and connectivity, and Graph Attention Networks (GATs), which excel in relational data contexts. Our results indicate that CatBoost outperforms GAT in this imbalanced dataset, effectively predicting holding events and offering interpretability through graph-based feature importance. Additionally, we discuss the model's potential operational impact through a web-based tool that allows users to simulate real-time delay predictions. This research underscores the viability of graph-based approaches for predictive analysis in aviation, with implications for enhancing fuel efficiency, reducing delays, and improving passenger experience.
Probing the statistical properties of enriched co-occurrence networks
Dec 03, 2024



Recent studies have explored the addition of virtual edges to word co-occurrence networks using word embeddings to enhance graph representations, particularly for short texts. While these enriched networks have demonstrated some success, the impact of incorporating semantic edges into traditional co-occurrence networks remains uncertain. This study investigates two key statistical properties of text-based network models. First, we assess whether network metrics can effectively distinguish between meaningless and meaningful texts. Second, we analyze whether these metrics are more sensitive to syntactic or semantic aspects of the text. Our results show that incorporating virtual edges can have positive and negative effects, depending on the specific network metric. For instance, the informativeness of the average shortest path and closeness centrality improves in short texts, while the clustering coefficient's informativeness decreases as more virtual edges are added. Additionally, we found that including stopwords affects the statistical properties of enriched networks. Our results can serve as a guideline for determining which network metrics are most appropriate for specific applications, depending on the typical text size and the nature of the problem.
Machine learning and economic forecasting: the role of international trade networks
Apr 11, 2024



This study examines the effects of de-globalization trends on international trade networks and their role in improving forecasts for economic growth. Using section-level trade data from nearly 200 countries from 2010 to 2022, we identify significant shifts in the network topology driven by rising trade policy uncertainty. Our analysis highlights key global players through centrality rankings, with the United States, China, and Germany maintaining consistent dominance. Using a horse race of supervised regressors, we find that network topology descriptors evaluated from section-specific trade networks substantially enhance the quality of a country's GDP growth forecast. We also find that non-linear models, such as Random Forest, XGBoost, and LightGBM, outperform traditional linear models used in the economics literature. Using SHAP values to interpret these non-linear model's predictions, we find that about half of most important features originate from the network descriptors, underscoring their vital role in refining forecasts. Moreover, this study emphasizes the significance of recent economic performance, population growth, and the primary sector's influence in shaping economic growth predictions, offering novel insights into the intricacies of economic growth forecasting.
Using Full-Text Content to Characterize and Identify Best Seller Books
Oct 05, 2022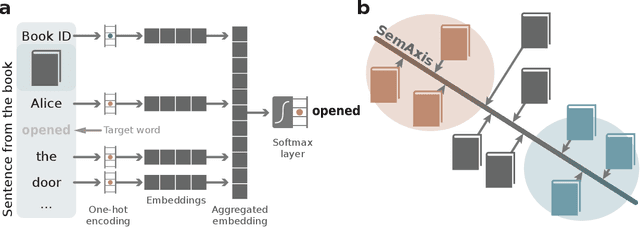
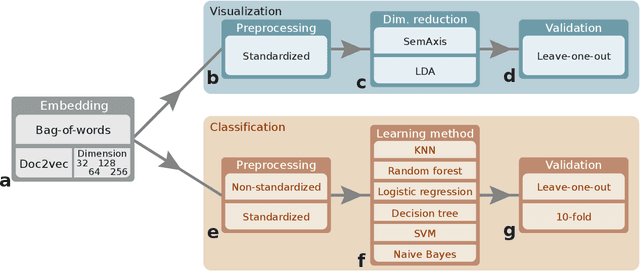


Artistic pieces can be studied from several perspectives, one example being their reception among readers over time. In the present work, we approach this interesting topic from the standpoint of literary works, particularly assessing the task of predicting whether a book will become a best seller. Dissimilarly from previous approaches, we focused on the full content of books and considered visualization and classification tasks. We employed visualization for the preliminary exploration of the data structure and properties, involving SemAxis and linear discriminant analyses. Then, to obtain quantitative and more objective results, we employed various classifiers. Such approaches were used along with a dataset containing (i) books published from 1895 to 1924 and consecrated as best sellers by the \emph{Publishers Weekly Bestseller Lists} and (ii) literary works published in the same period but not being mentioned in that list. Our comparison of methods revealed that the best-achieved result - combining a bag-of-words representation with a logistic regression classifier - led to an average accuracy of 0.75 both for the leave-one-out and 10-fold cross-validations. Such an outcome suggests that it is unfeasible to predict the success of books with high accuracy using only the full content of the texts. Nevertheless, our findings provide insights into the factors leading to the relative success of a literary work.
Classification of network topology and dynamics via sequence characterization
Jun 30, 2022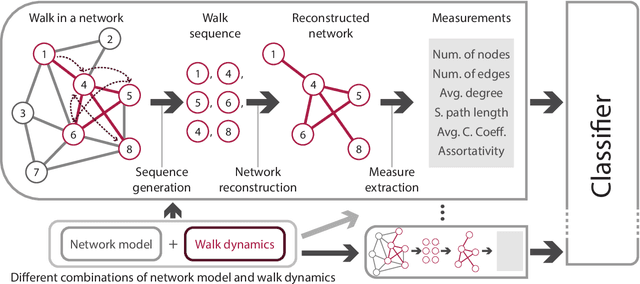
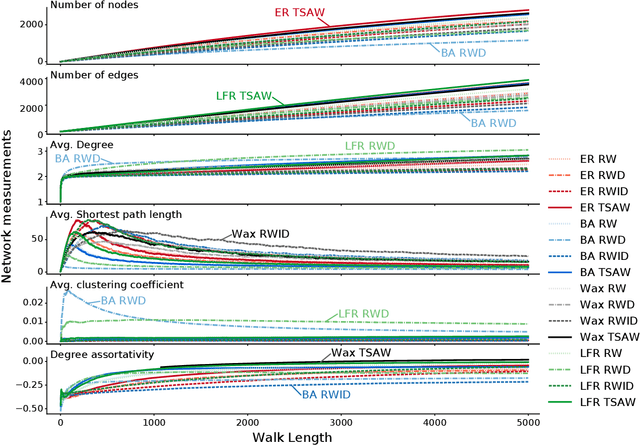
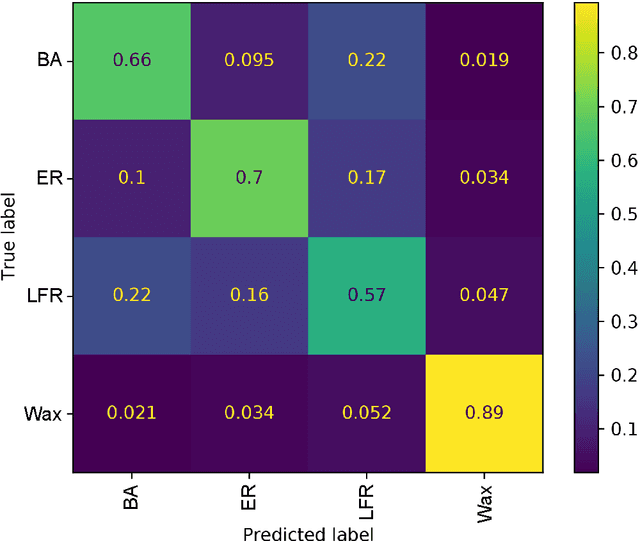
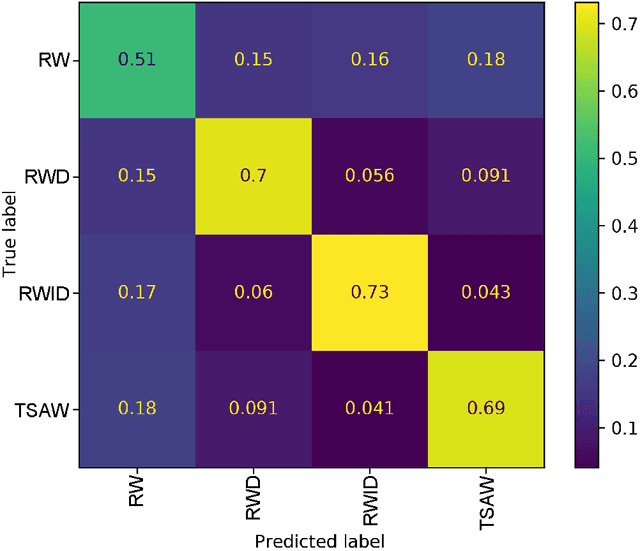
Sequences arise in many real-world scenarios; thus, identifying the mechanisms behind symbol generation is essential to understanding many complex systems. This paper analyzes sequences generated by agents walking on a networked topology. Given that in many real scenarios, the underlying processes generating the sequence is hidden, we investigate whether the reconstruction of the network via the co-occurrence method is useful to recover both the network topology and agent dynamics generating sequences. We found that the characterization of reconstructed networks provides valuable information regarding the process and topology used to create the sequences. In a machine learning approach considering 16 combinations of network topology and agent dynamics as classes, we obtained an accuracy of 87% with sequences generated with less than 40% of nodes visited. Larger sequences turned out to generate improved machine learning models. Our findings suggest that the proposed methodology could be extended to classify sequences and understand the mechanisms behind sequence generation.
Using virtual edges to extract keywords from texts modeled as complex networks
May 04, 2022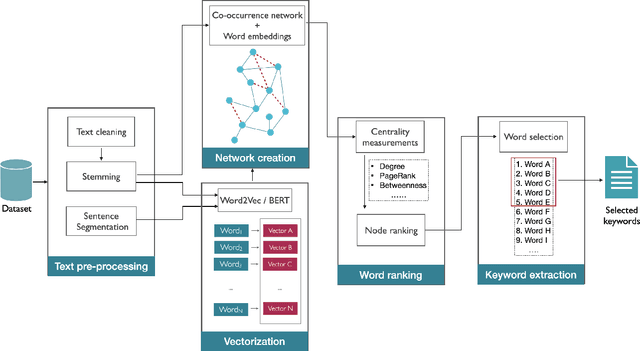

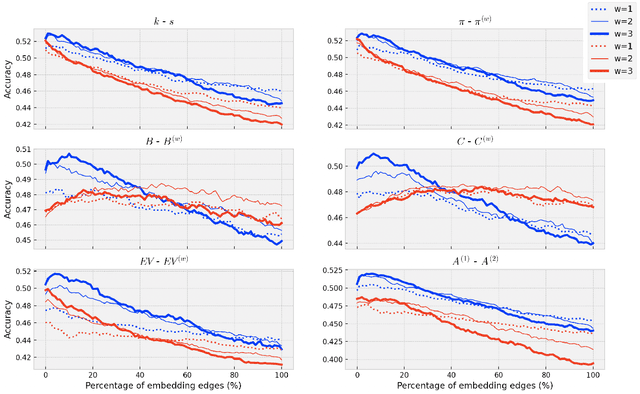
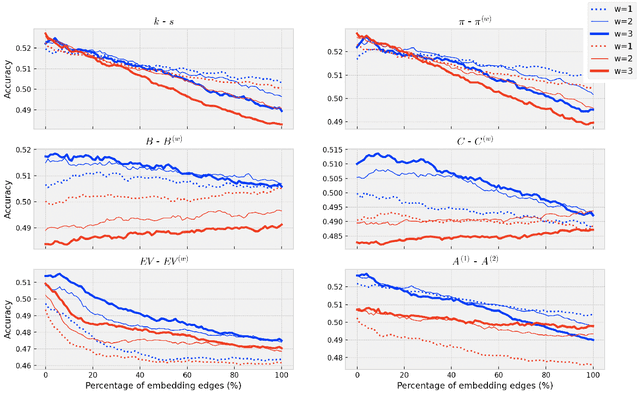
Detecting keywords in texts is important for many text mining applications. Graph-based methods have been commonly used to automatically find the key concepts in texts, however, relevant information provided by embeddings has not been widely used to enrich the graph structure. Here we modeled texts co-occurrence networks, where nodes are words and edges are established either by contextual or semantical similarity. We compared two embedding approaches -- Word2vec and BERT -- to check whether edges created via word embeddings can improve the quality of the keyword extraction method. We found that, in fact, the use of virtual edges can improve the discriminability of co-occurrence networks. The best performance was obtained when we considered low percentages of addition of virtual (embedding) edges. A comparative analysis of structural and dynamical network metrics revealed the degree, PageRank, and accessibility are the metrics displaying the best performance in the model enriched with virtual edges.
Accessibility and Trajectory-Based Text Characterization
Jan 17, 2022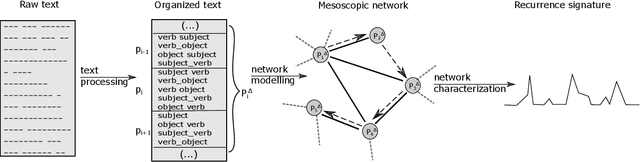
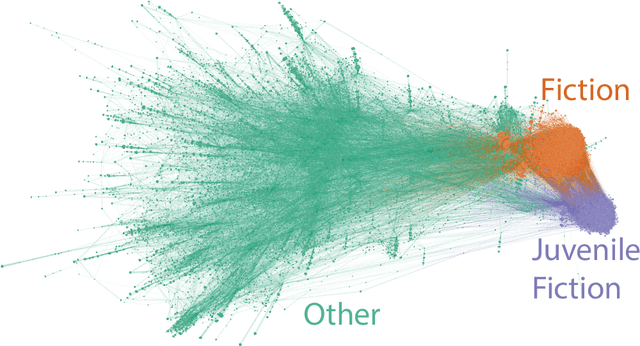
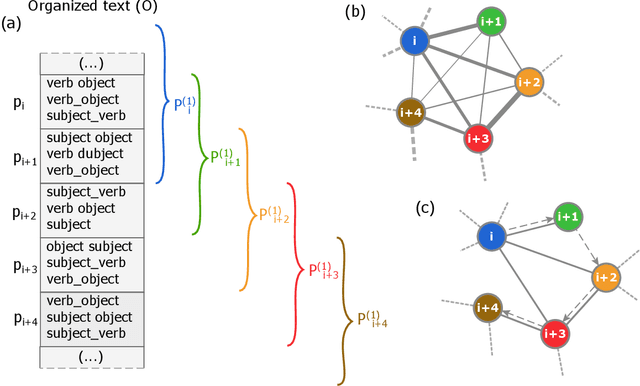
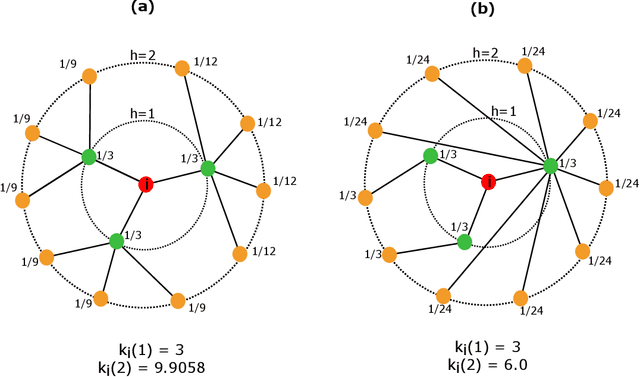
Several complex systems are characterized by presenting intricate characteristics extending along many scales. These characterizations are used in various applications, including text classification, better understanding of diseases, and comparison between cities, among others. In particular, texts are also characterized by a hierarchical structure that can be approached by using multi-scale concepts and methods. The present work aims at developing these possibilities while focusing on mesoscopic representations of networks. More specifically, we adopt an extension to the mesoscopic approach to represent text narratives, in which only the recurrent relationships among tagged parts of speech are considered to establish connections among sequential pieces of text (e.g., paragraphs). The characterization of the texts was then achieved by considering scale-dependent complementary methods: accessibility, symmetry and recurrence signatures. In order to evaluate the potential of these concepts and methods, we approached the problem of distinguishing between literary genres (fiction and non-fiction). A set of 300 books organized into the two genres was considered and were compared by using the aforementioned approaches. All the methods were capable of differentiating to some extent between the two genres. The accessibility and symmetry reflected the narrative asymmetries, while the recurrence signature provide a more direct indication about the non-sequential semantic connections taking place along the narrative.
A pattern recognition approach for distinguishing between prose and poetry
Jul 18, 2021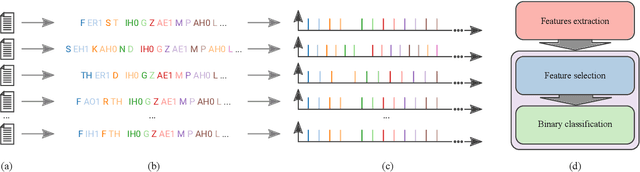
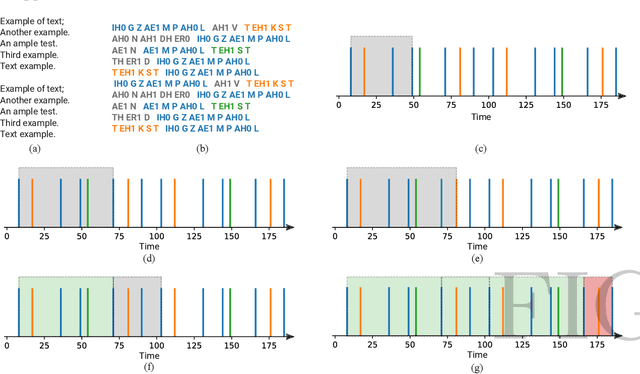


Poetry and prose are written artistic expressions that help us to appreciate the reality we live. Each of these styles has its own set of subjective properties, such as rhyme and rhythm, which are easily caught by a human reader's eye and ear. With the recent advances in artificial intelligence, the gap between humans and machines may have decreased, and today we observe algorithms mastering tasks that were once exclusively performed by humans. In this paper, we propose an automated method to distinguish between poetry and prose based solely on aural and rhythmic properties. In other to compare prose and poetry rhythms, we represent the rhymes and phones as temporal sequences and thus we propose a procedure for extracting rhythmic features from these sequences. The classification of the considered texts using the set of features extracted resulted in a best accuracy of 0.78, obtained with a neural network. Interestingly, by using an approach based on complex networks to visualize the similarities between the different texts considered, we found that the patterns of poetry vary much more than prose. Consequently, a much richer and complex set of rhythmic possibilities tends to be found in that modality.
On predicting research grants productivity
Jun 20, 2021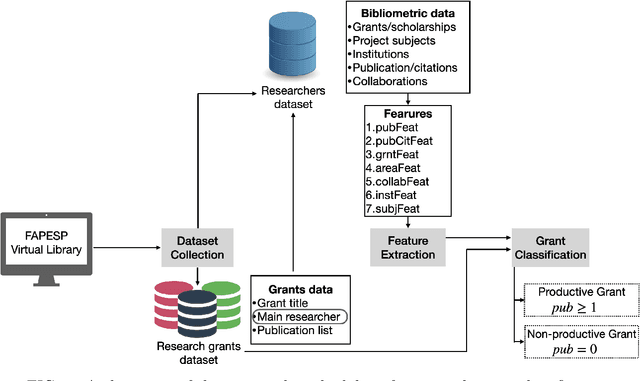
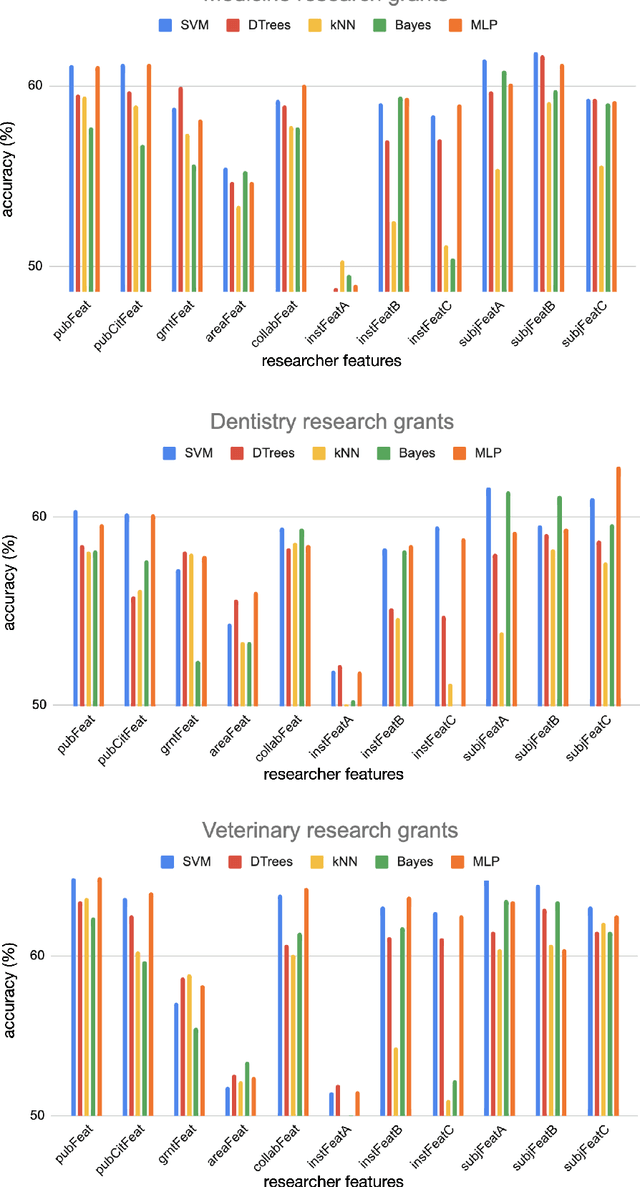


Understanding the reasons associated with successful proposals is of paramount importance to improve evaluation processes. In this context, we analyzed whether bibliometric features are able to predict the success of research grants. We extracted features aiming at characterizing the academic history of Brazilian researchers, including research topics, affiliations, number of publications and visibility. The extracted features were then used to predict grants productivity via machine learning in three major research areas, namely Medicine, Dentistry and Veterinary Medicine. We found that research subject and publication history play a role in predicting productivity. In addition, institution-based features turned out to be relevant when combined with other features. While the best results outperformed text-based attributes, the evaluated features were not highly discriminative. Our findings indicate that predicting grants success, at least with the considered set of bibliometric features, is not a trivial task.