 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing virtual edges to extract keywords from texts modeled as complex networks
May 04, 2022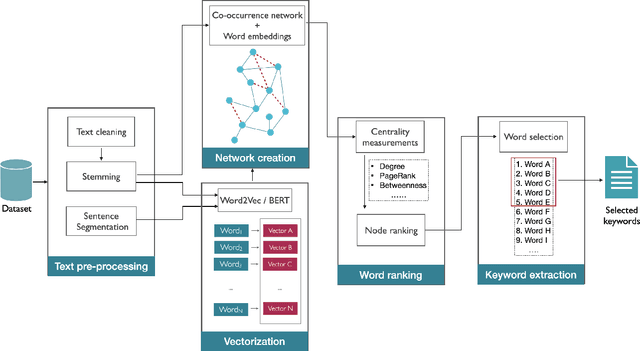

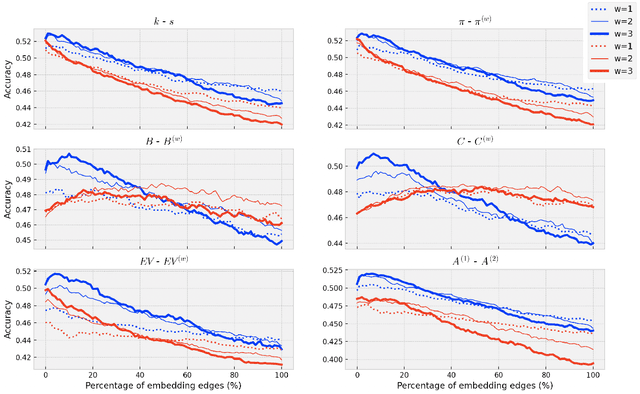
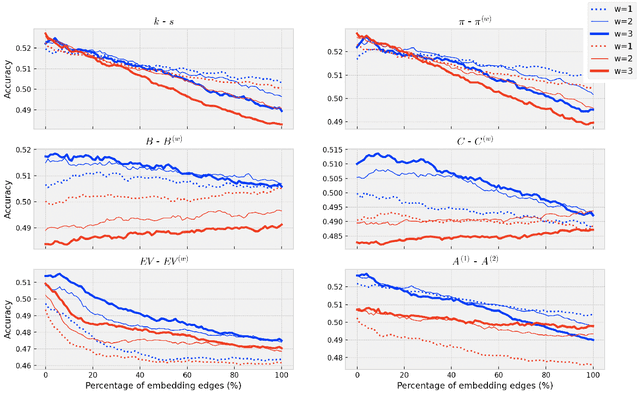
Detecting keywords in texts is important for many text mining applications. Graph-based methods have been commonly used to automatically find the key concepts in texts, however, relevant information provided by embeddings has not been widely used to enrich the graph structure. Here we modeled texts co-occurrence networks, where nodes are words and edges are established either by contextual or semantical similarity. We compared two embedding approaches -- Word2vec and BERT -- to check whether edges created via word embeddings can improve the quality of the keyword extraction method. We found that, in fact, the use of virtual edges can improve the discriminability of co-occurrence networks. The best performance was obtained when we considered low percentages of addition of virtual (embedding) edges. A comparative analysis of structural and dynamical network metrics revealed the degree, PageRank, and accessibility are the metrics displaying the best performance in the model enriched with virtual edges.
On predicting research grants productivity
Jun 20, 2021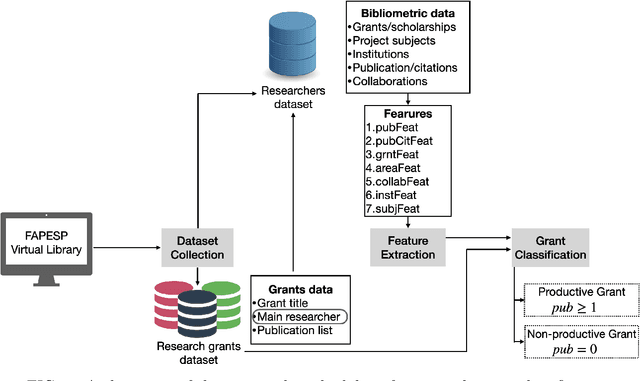
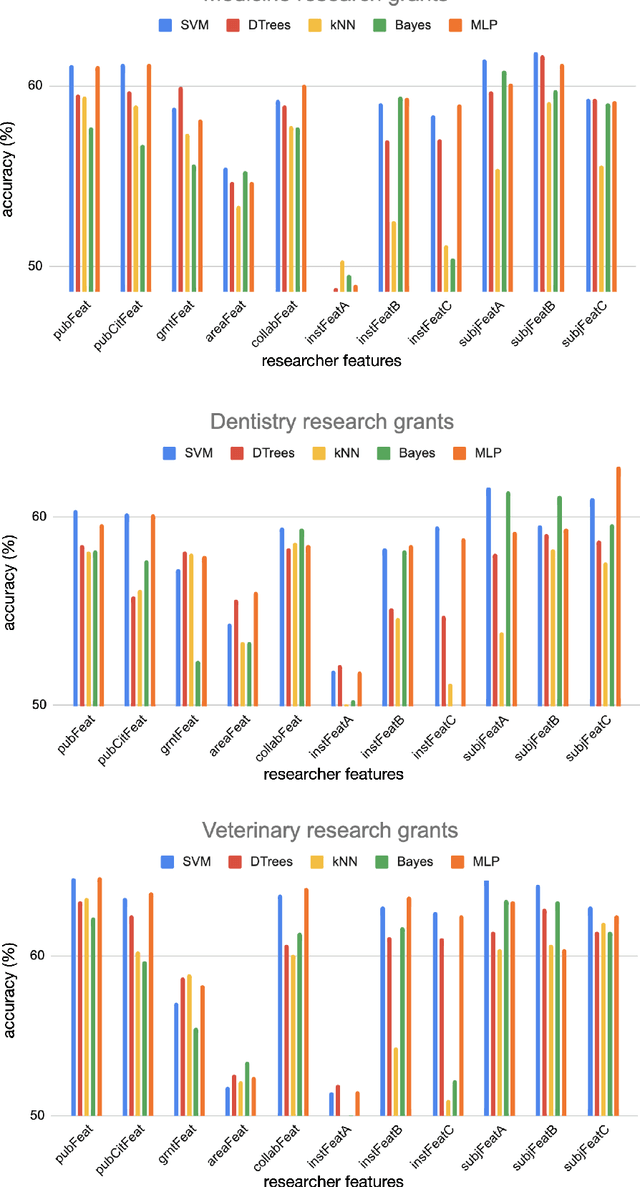


Understanding the reasons associated with successful proposals is of paramount importance to improve evaluation processes. In this context, we analyzed whether bibliometric features are able to predict the success of research grants. We extracted features aiming at characterizing the academic history of Brazilian researchers, including research topics, affiliations, number of publications and visibility. The extracted features were then used to predict grants productivity via machine learning in three major research areas, namely Medicine, Dentistry and Veterinary Medicine. We found that research subject and publication history play a role in predicting productivity. In addition, institution-based features turned out to be relevant when combined with other features. While the best results outperformed text-based attributes, the evaluated features were not highly discriminative. Our findings indicate that predicting grants success, at least with the considered set of bibliometric features, is not a trivial task.
Language Networks: a Practical Approach
Oct 13, 2020


This manuscript provides a short and practical introduction to the topic of language networks. This text aims at assisting researchers with no practical experience in text and/or network analysis. We provide a practical tutorial on how to model and characterize texts using network-based features. In this tutorial, we also include examples of pre-processing and network representations. A brief description of the main tasks allying network science and text analysis is also provided. A further development of this text shall include a practical description of network classification via machine learning methods.
Using word embeddings to improve the discriminability of co-occurrence text networks
Mar 13, 2020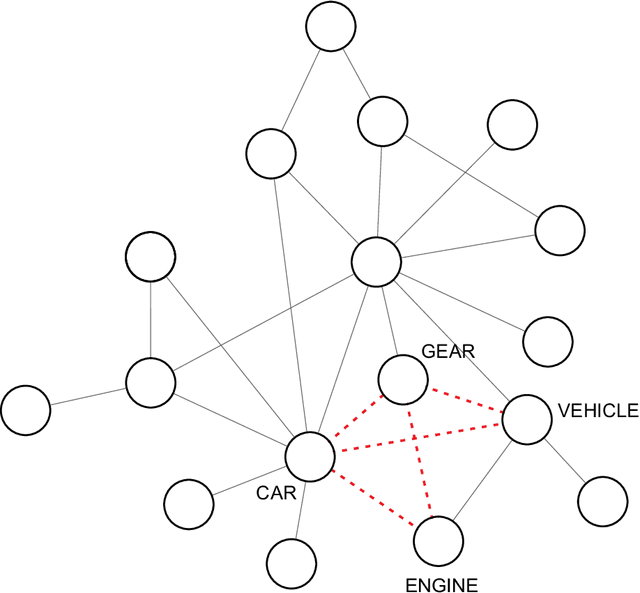
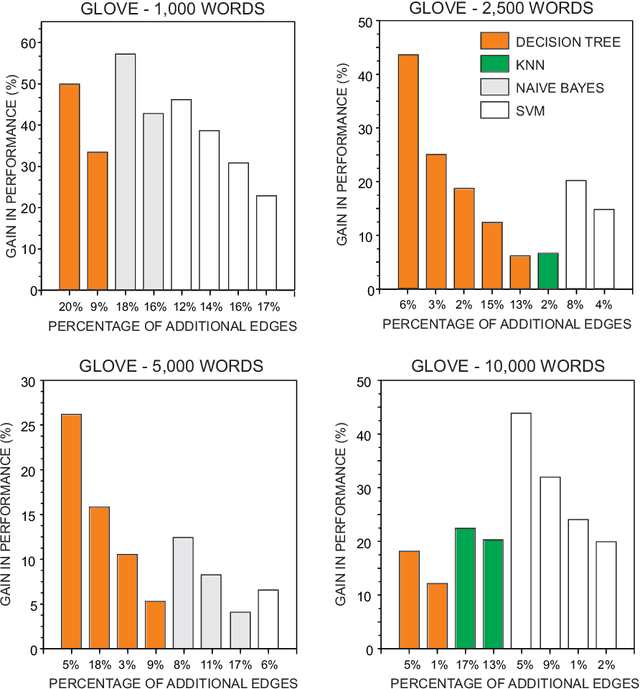
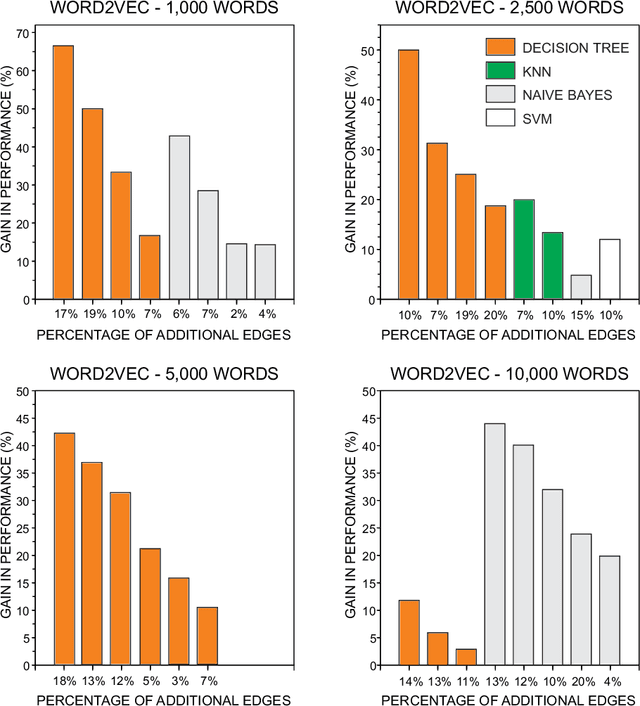
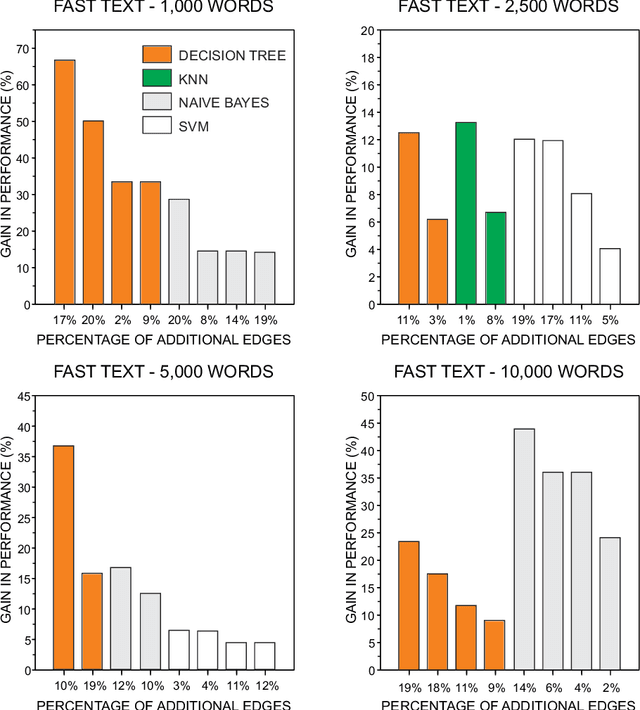
Word co-occurrence networks have been employed to analyze texts both in the practical and theoretical scenarios. Despite the relative success in several applications, traditional co-occurrence networks fail in establishing links between similar words whenever they appear distant in the text. Here we investigate whether the use of word embeddings as a tool to create virtual links in co-occurrence networks may improve the quality of classification systems. Our results revealed that the discriminability in the stylometry task is improved when using Glove, Word2Vec and FastText. In addition, we found that optimized results are obtained when stopwords are not disregarded and a simple global thresholding strategy is used to establish virtual links. Because the proposed approach is able to improve the representation of texts as complex networks, we believe that it could be extended to study other natural language processing tasks. Likewise, theoretical languages studies could benefit from the adopted enriched representation of word co-occurrence networks.