 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning and economic forecasting: the role of international trade networks
Apr 11, 2024



This study examines the effects of de-globalization trends on international trade networks and their role in improving forecasts for economic growth. Using section-level trade data from nearly 200 countries from 2010 to 2022, we identify significant shifts in the network topology driven by rising trade policy uncertainty. Our analysis highlights key global players through centrality rankings, with the United States, China, and Germany maintaining consistent dominance. Using a horse race of supervised regressors, we find that network topology descriptors evaluated from section-specific trade networks substantially enhance the quality of a country's GDP growth forecast. We also find that non-linear models, such as Random Forest, XGBoost, and LightGBM, outperform traditional linear models used in the economics literature. Using SHAP values to interpret these non-linear model's predictions, we find that about half of most important features originate from the network descriptors, underscoring their vital role in refining forecasts. Moreover, this study emphasizes the significance of recent economic performance, population growth, and the primary sector's influence in shaping economic growth predictions, offering novel insights into the intricacies of economic growth forecasting.
Using virtual edges to extract keywords from texts modeled as complex networks
May 04, 2022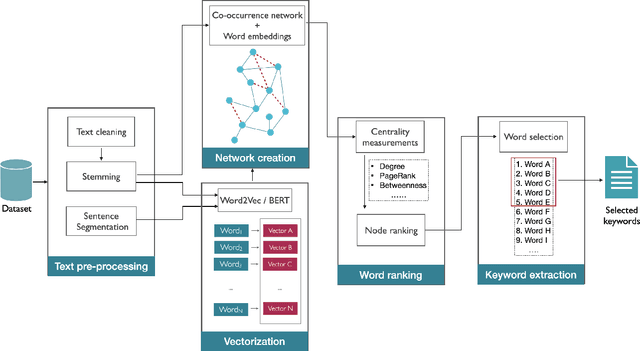

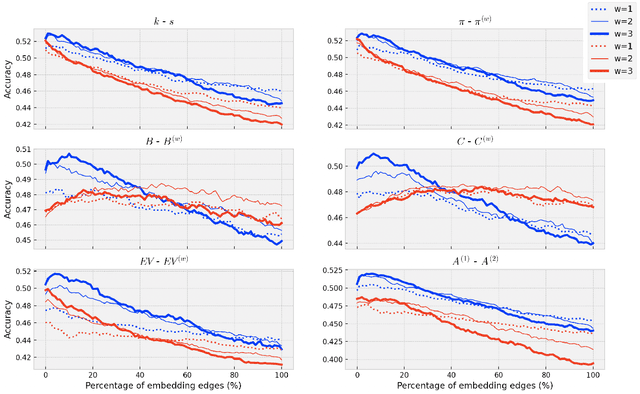
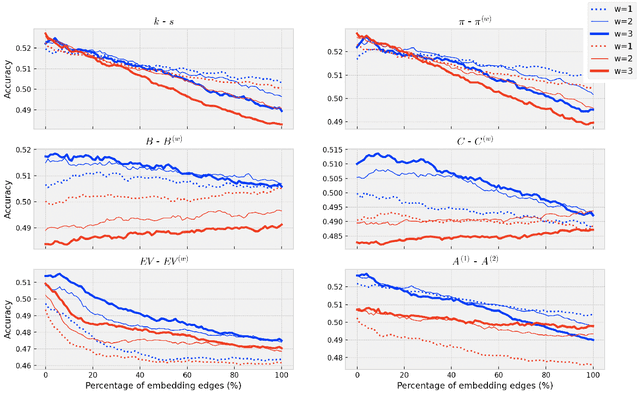
Detecting keywords in texts is important for many text mining applications. Graph-based methods have been commonly used to automatically find the key concepts in texts, however, relevant information provided by embeddings has not been widely used to enrich the graph structure. Here we modeled texts co-occurrence networks, where nodes are words and edges are established either by contextual or semantical similarity. We compared two embedding approaches -- Word2vec and BERT -- to check whether edges created via word embeddings can improve the quality of the keyword extraction method. We found that, in fact, the use of virtual edges can improve the discriminability of co-occurrence networks. The best performance was obtained when we considered low percentages of addition of virtual (embedding) edges. A comparative analysis of structural and dynamical network metrics revealed the degree, PageRank, and accessibility are the metrics displaying the best performance in the model enriched with virtual edges.
Discriminating word senses with tourist walks in complex networks
Jun 17, 2013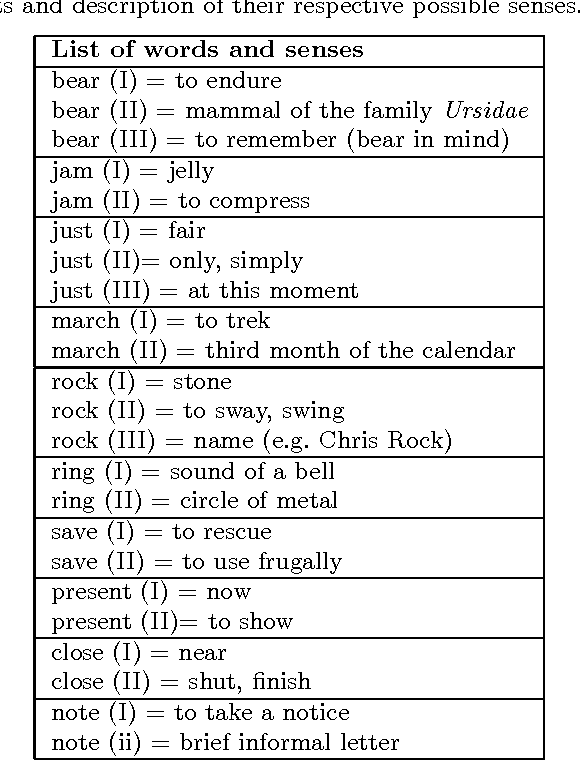
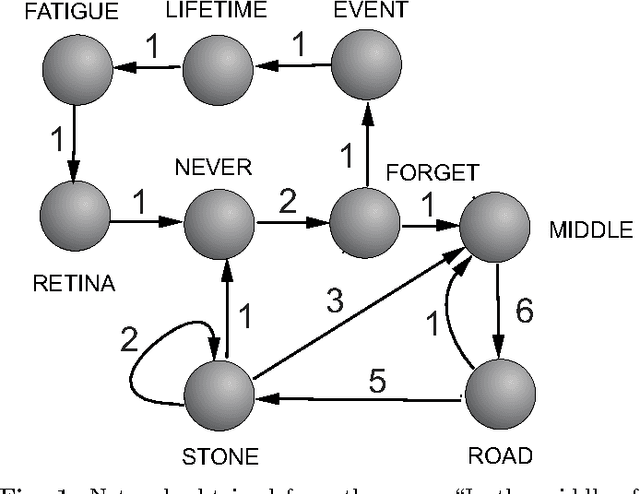


Patterns of topological arrangement are widely used for both animal and human brains in the learning process. Nevertheless, automatic learning techniques frequently overlook these patterns. In this paper, we apply a learning technique based on the structural organization of the data in the attribute space to the problem of discriminating the senses of 10 polysemous words. Using two types of characterization of meanings, namely semantical and topological approaches, we have observed significative accuracy rates in identifying the suitable meanings in both techniques. Most importantly, we have found that the characterization based on the deterministic tourist walk improves the disambiguation process when one compares with the discrimination achieved with traditional complex networks measurements such as assortativity and clustering coefficient. To our knowledge, this is the first time that such deterministic walk has been applied to such a kind of problem. Therefore, our finding suggests that the tourist walk characterization may be useful in other related applications.
Word sense disambiguation via high order of learning in complex networks
Feb 18, 2013
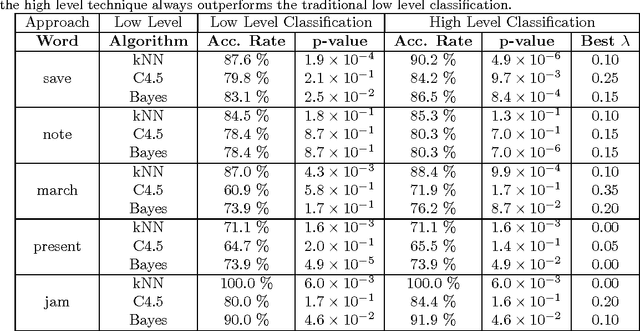


Complex networks have been employed to model many real systems and as a modeling tool in a myriad of applications. In this paper, we use the framework of complex networks to the problem of supervised classification in the word disambiguation task, which consists in deriving a function from the supervised (or labeled) training data of ambiguous words. Traditional supervised data classification takes into account only topological or physical features of the input data. On the other hand, the human (animal) brain performs both low- and high-level orders of learning and it has facility to identify patterns according to the semantic meaning of the input data. In this paper, we apply a hybrid technique which encompasses both types of learning in the field of word sense disambiguation and show that the high-level order of learning can really improve the accuracy rate of the model. This evidence serves to demonstrate that the internal structures formed by the words do present patterns that, generally, cannot be correctly unveiled by only traditional techniques. Finally, we exhibit the behavior of the model for different weights of the low- and high-level classifiers by plotting decision boundaries. This study helps one to better understand the effectiveness of the model.
* The Supplementary Information (SI) is hosted at http://dl.dropbox.com/u/2740286/epl_SI_9apr.pdf