 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the statistical properties of enriched co-occurrence networks
Dec 03, 2024



Recent studies have explored the addition of virtual edges to word co-occurrence networks using word embeddings to enhance graph representations, particularly for short texts. While these enriched networks have demonstrated some success, the impact of incorporating semantic edges into traditional co-occurrence networks remains uncertain. This study investigates two key statistical properties of text-based network models. First, we assess whether network metrics can effectively distinguish between meaningless and meaningful texts. Second, we analyze whether these metrics are more sensitive to syntactic or semantic aspects of the text. Our results show that incorporating virtual edges can have positive and negative effects, depending on the specific network metric. For instance, the informativeness of the average shortest path and closeness centrality improves in short texts, while the clustering coefficient's informativeness decreases as more virtual edges are added. Additionally, we found that including stopwords affects the statistical properties of enriched networks. Our results can serve as a guideline for determining which network metrics are most appropriate for specific applications, depending on the typical text size and the nature of the problem.
Using word embeddings to improve the discriminability of co-occurrence text networks
Mar 13, 2020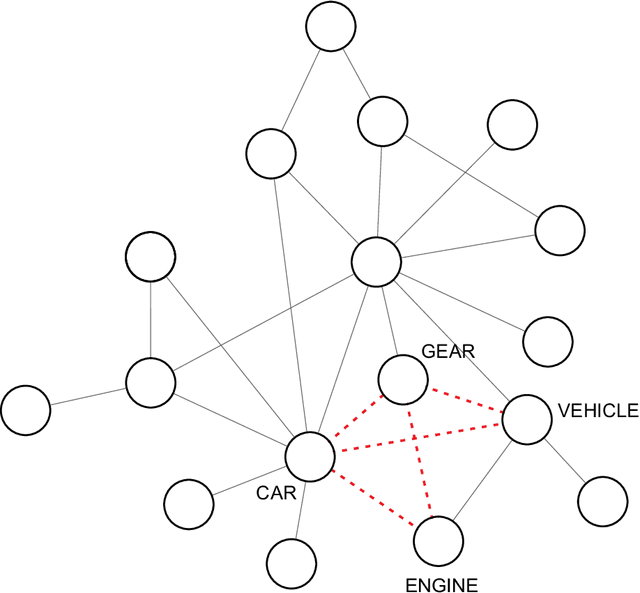
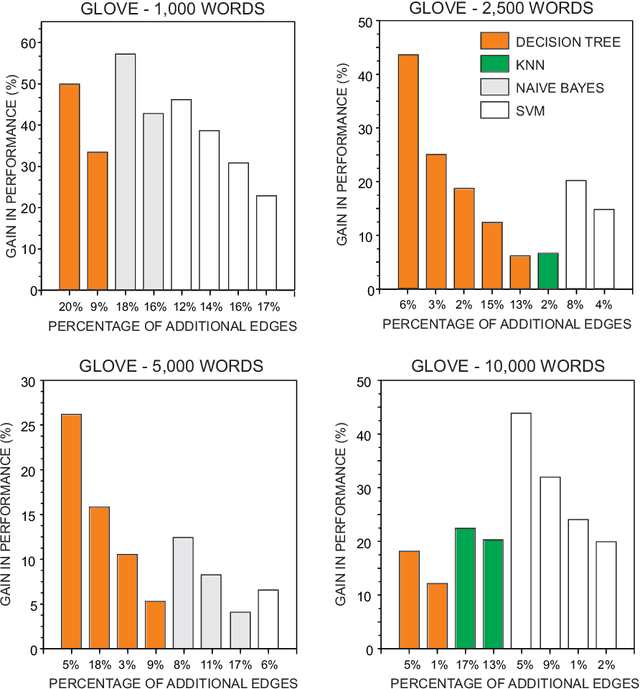
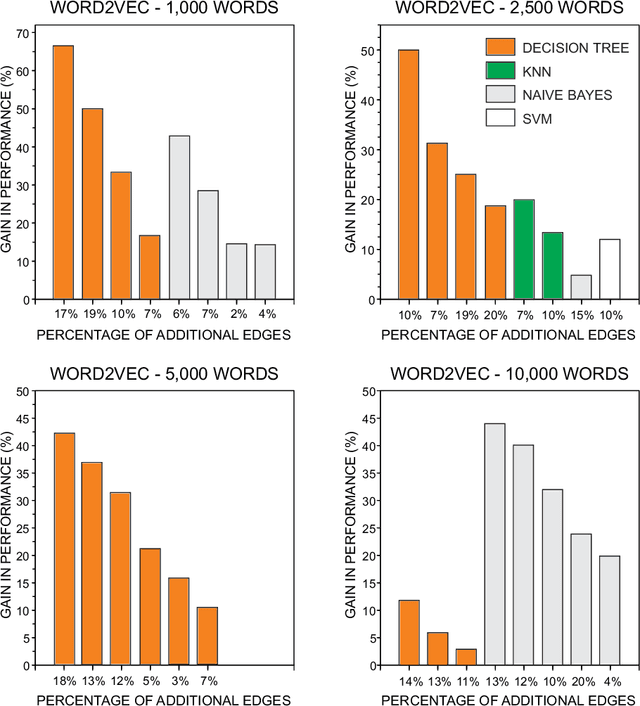
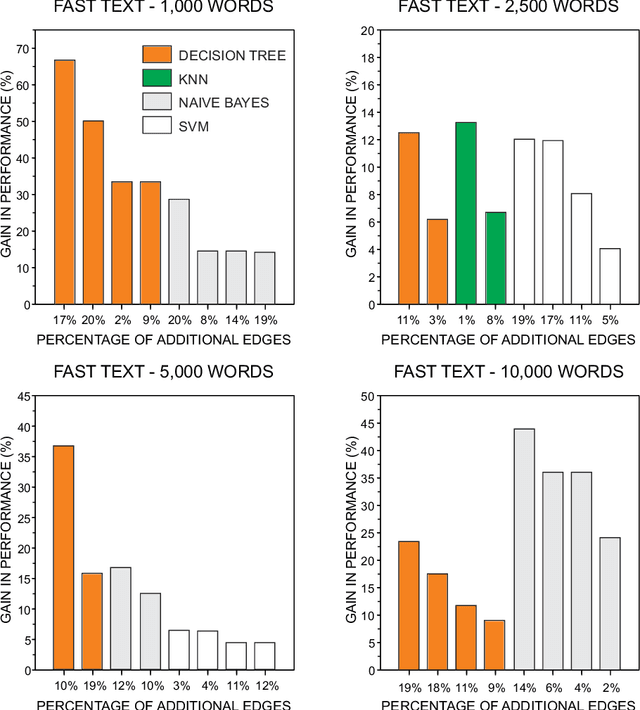
Word co-occurrence networks have been employed to analyze texts both in the practical and theoretical scenarios. Despite the relative success in several applications, traditional co-occurrence networks fail in establishing links between similar words whenever they appear distant in the text. Here we investigate whether the use of word embeddings as a tool to create virtual links in co-occurrence networks may improve the quality of classification systems. Our results revealed that the discriminability in the stylometry task is improved when using Glove, Word2Vec and FastText. In addition, we found that optimized results are obtained when stopwords are not disregarded and a simple global thresholding strategy is used to establish virtual links. Because the proposed approach is able to improve the representation of texts as complex networks, we believe that it could be extended to study other natural language processing tasks. Likewise, theoretical languages studies could benefit from the adopted enriched representation of word co-occurrence networks.