 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the statistical properties of enriched co-occurrence networks
Dec 03, 2024



Recent studies have explored the addition of virtual edges to word co-occurrence networks using word embeddings to enhance graph representations, particularly for short texts. While these enriched networks have demonstrated some success, the impact of incorporating semantic edges into traditional co-occurrence networks remains uncertain. This study investigates two key statistical properties of text-based network models. First, we assess whether network metrics can effectively distinguish between meaningless and meaningful texts. Second, we analyze whether these metrics are more sensitive to syntactic or semantic aspects of the text. Our results show that incorporating virtual edges can have positive and negative effects, depending on the specific network metric. For instance, the informativeness of the average shortest path and closeness centrality improves in short texts, while the clustering coefficient's informativeness decreases as more virtual edges are added. Additionally, we found that including stopwords affects the statistical properties of enriched networks. Our results can serve as a guideline for determining which network metrics are most appropriate for specific applications, depending on the typical text size and the nature of the problem.
A Network Classification Method based on Density Time Evolution Patterns Extracted from Network Automata
Nov 18, 2022Network modeling has proven to be an efficient tool for many interdisciplinary areas, including social, biological, transport, and many other real world complex systems. In addition, cellular automata (CA) are a formalism that has been studied in the last decades as a model for exploring patterns in the dynamic spatio-temporal behavior of these systems based on local rules. Some studies explore the use of cellular automata to analyze the dynamic behavior of networks, denominating them as network automata (NA). Recently, NA proved to be efficient for network classification, since it uses a time-evolution pattern (TEP) for the feature extraction. However, the TEPs explored by previous studies are composed of binary values, which does not represent detailed information on the network analyzed. Therefore, in this paper, we propose alternate sources of information to use as descriptor for the classification task, which we denominate as density time-evolution pattern (D-TEP) and state density time-evolution pattern (SD-TEP). We explore the density of alive neighbors of each node, which is a continuous value, and compute feature vectors based on histograms of the TEPs. Our results show a significant improvement compared to previous studies at five synthetic network databases and also seven real world databases. Our proposed method demonstrates not only a good approach for pattern recognition in networks, but also shows great potential for other kinds of data, such as images.
An optimized shape descriptor based on structural properties of networks
Nov 14, 2017
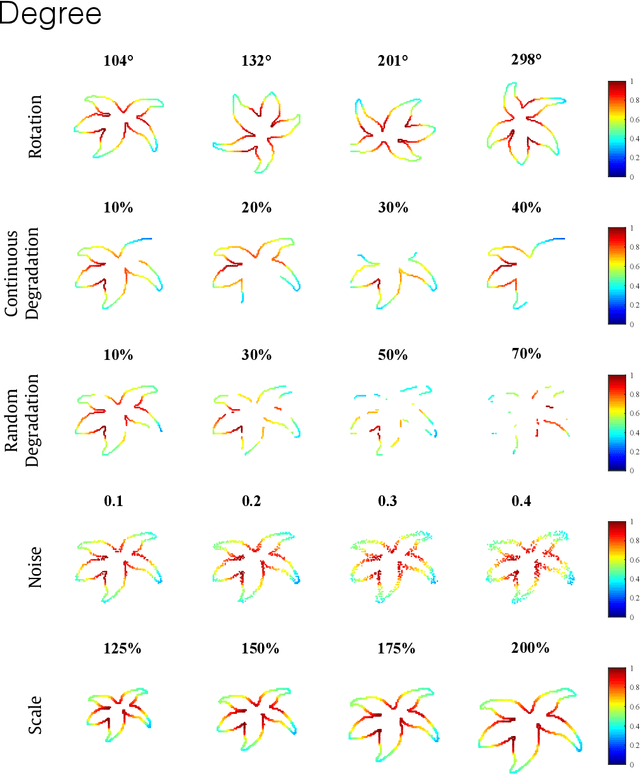


The structural analysis of shape boundaries leads to the characterization of objects as well as to the understanding of shape properties. The literature on graphs and networks have contributed to the structural characterization of shapes with different theoretical approaches. We performed a study on the relationship between the shape architecture and the network topology constructed over the shape boundary. For that, we used a method for network modeling proposed in 2009. Firstly, together with curvature analysis, we evaluated the proposed approach for regular polygons. This way, it was possible to investigate how the network measurements vary according to some specific shape properties. Secondly, we evaluated the performance of the proposed shape descriptor in classification tasks for three datasets, accounting for both real-world and synthetic shapes. We demonstrated that not only degree related measurements are capable of distinguishing classes of objects. Yet, when using measurements that account for distinct properties of the network structure, the construction of the shape descriptor becomes more computationally efficient. Given the fact the network is dynamically constructed, the number of iterations can be reduced. The proposed approach accounts for a more robust set of structural measurements, that improved the discriminant power of the shape descriptors.
Authorship Attribution Based on Life-Like Network Automata
Oct 20, 2016


The authorship attribution is a problem of considerable practical and technical interest. Several methods have been designed to infer the authorship of disputed documents in multiple contexts. While traditional statistical methods based solely on word counts and related measurements have provided a simple, yet effective solution in particular cases; they are prone to manipulation. Recently, texts have been successfully modeled as networks, where words are represented by nodes linked according to textual similarity measurements. Such models are useful to identify informative topological patterns for the authorship recognition task. However, there is no consensus on which measurements should be used. Thus, we proposed a novel method to characterize text networks, by considering both topological and dynamical aspects of networks. Using concepts and methods from cellular automata theory, we devised a strategy to grasp informative spatio-temporal patterns from this model. Our experiments revealed an outperformance over traditional analysis relying only on topological measurements. Remarkably, we have found a dependence of pre-processing steps (such as the lemmatization) on the obtained results, a feature that has mostly been disregarded in related works. The optimized results obtained here pave the way for a better characterization of textual networks.