 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic flow in language networks
May 18, 2019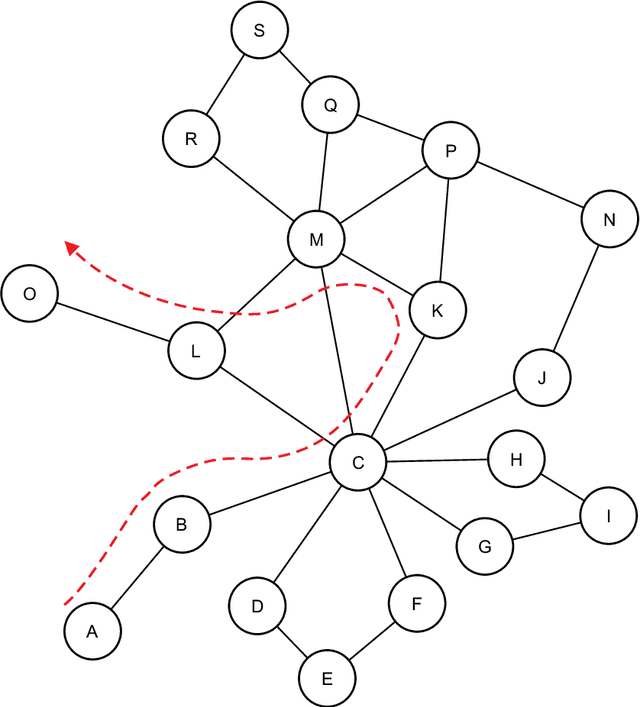



In this study we propose a framework to characterize documents based on their semantic flow. The proposed framework encompasses a network-based model that connected sentences based on their semantic similarity. Semantic fields are detected using standard community detection methods. as the story unfolds, transitions between semantic fields are represent in Markov networks, which in turned are characterized via network motifs (subgraphs). Here we show that the proposed framework can be used to classify books according to their style and publication dates. Remarkably, even without a systematic optimization of parameters, philosophy and investigative books were discriminated with an accuracy rate of 92.5%. Because this model captures semantic features of texts, it could be used as an additional feature in traditional network-based models of texts that capture only syntactical/stylistic information, as it is the case of word adjacency (co-occurrence) networks.
Word sense induction using word embeddings and community detection in complex networks
Mar 22, 2018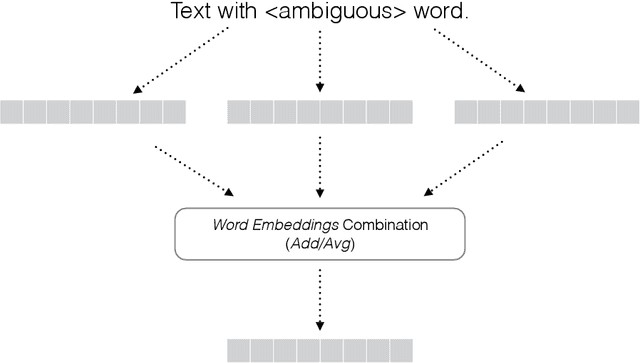
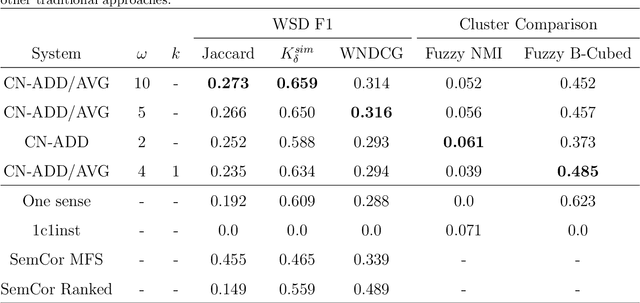

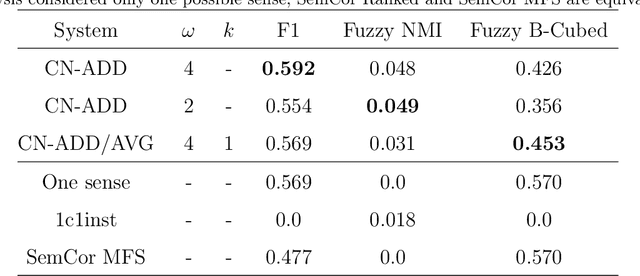
Word Sense Induction (WSI) is the ability to automatically induce word senses from corpora. The WSI task was first proposed to overcome the limitations of manually annotated corpus that are required in word sense disambiguation systems. Even though several works have been proposed to induce word senses, existing systems are still very limited in the sense that they make use of structured, domain-specific knowledge sources. In this paper, we devise a method that leverages recent findings in word embeddings research to generate context embeddings, which are embeddings containing information about the semantical context of a word. In order to induce senses, we modeled the set of ambiguous words as a complex network. In the generated network, two instances (nodes) are connected if the respective context embeddings are similar. Upon using well-established community detection methods to cluster the obtained context embeddings, we found that the proposed method yields excellent performance for the WSI task. Our method outperformed competing algorithms and baselines, in a completely unsupervised manner and without the need of any additional structured knowledge source.
NILC-USP at SemEval-2017 Task 4: A Multi-view Ensemble for Twitter Sentiment Analysis
Apr 07, 2017
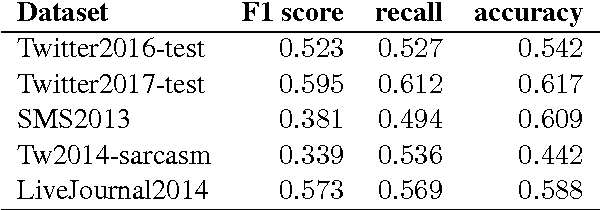
This paper describes our multi-view ensemble approach to SemEval-2017 Task 4 on Sentiment Analysis in Twitter, specifically, the Message Polarity Classification subtask for English (subtask A). Our system is a voting ensemble, where each base classifier is trained in a different feature space. The first space is a bag-of-words model and has a Linear SVM as base classifier. The second and third spaces are two different strategies of combining word embeddings to represent sentences and use a Linear SVM and a Logistic Regressor as base classifiers. The proposed system was ranked 18th out of 38 systems considering F1 score and 20th considering recall.
Authorship Attribution Based on Life-Like Network Automata
Oct 20, 2016
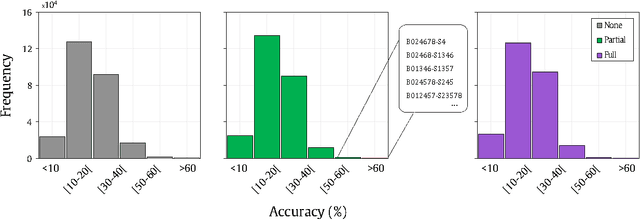


The authorship attribution is a problem of considerable practical and technical interest. Several methods have been designed to infer the authorship of disputed documents in multiple contexts. While traditional statistical methods based solely on word counts and related measurements have provided a simple, yet effective solution in particular cases; they are prone to manipulation. Recently, texts have been successfully modeled as networks, where words are represented by nodes linked according to textual similarity measurements. Such models are useful to identify informative topological patterns for the authorship recognition task. However, there is no consensus on which measurements should be used. Thus, we proposed a novel method to characterize text networks, by considering both topological and dynamical aspects of networks. Using concepts and methods from cellular automata theory, we devised a strategy to grasp informative spatio-temporal patterns from this model. Our experiments revealed an outperformance over traditional analysis relying only on topological measurements. Remarkably, we have found a dependence of pre-processing steps (such as the lemmatization) on the obtained results, a feature that has mostly been disregarded in related works. The optimized results obtained here pave the way for a better characterization of textual networks.