 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic flow in language networks
May 18, 2019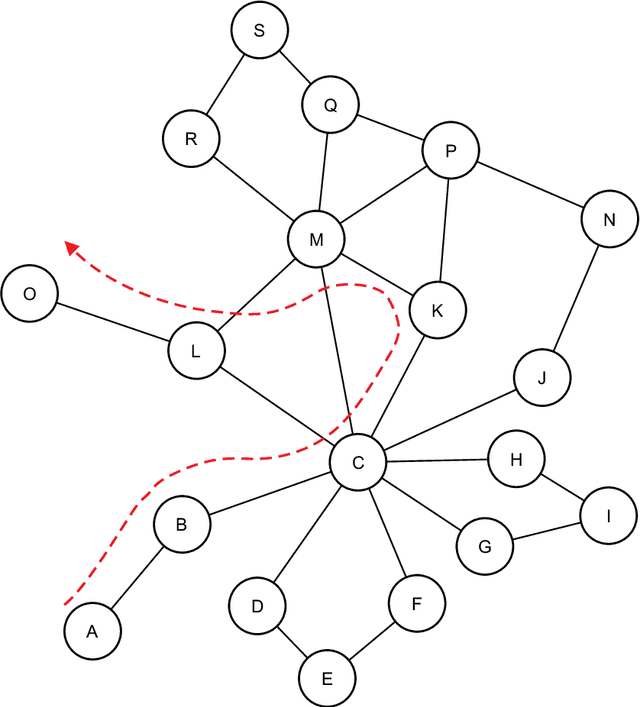



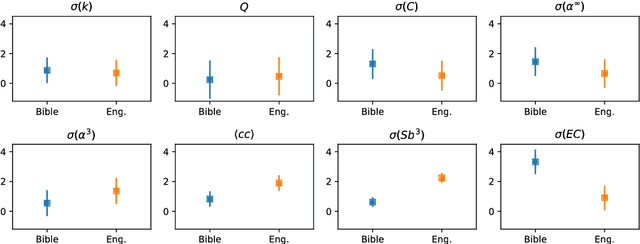
In this study we propose a framework to characterize documents based on their semantic flow. The proposed framework encompasses a network-based model that connected sentences based on their semantic similarity. Semantic fields are detected using standard community detection methods. as the story unfolds, transitions between semantic fields are represent in Markov networks, which in turned are characterized via network motifs (subgraphs). Here we show that the proposed framework can be used to classify books according to their style and publication dates. Remarkably, even without a systematic optimization of parameters, philosophy and investigative books were discriminated with an accuracy rate of 92.5%. Because this model captures semantic features of texts, it could be used as an additional feature in traditional network-based models of texts that capture only syntactical/stylistic information, as it is the case of word adjacency (co-occurrence) networks.
Paragraph-based complex networks: application to document classification and authenticity verification
Jun 22, 2018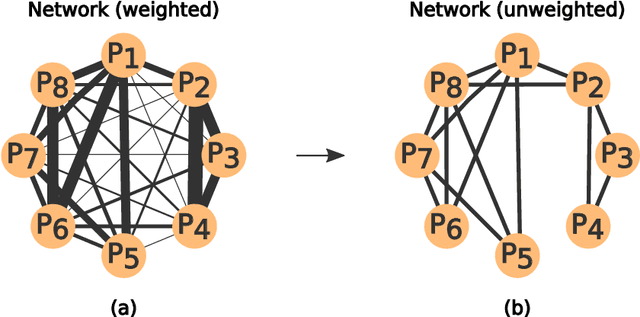
With the increasing number of texts made available on the Internet, many applications have relied on text mining tools to tackle a diversity of problems. A relevant model to represent texts is the so-called word adjacency (co-occurrence) representation, which is known to capture mainly syntactical features of texts.In this study, we introduce a novel network representation that considers the semantic similarity between paragraphs. Two main properties of paragraph networks are considered: (i) their ability to incorporate characteristics that can discriminate real from artificial, shuffled manuscripts and (ii) their ability to capture syntactical and semantic textual features. Our results revealed that real texts are organized into communities, which turned out to be an important feature for discriminating them from artificial texts. Interestingly, we have also found that, differently from traditional co-occurrence networks, the adopted representation is able to capture semantic features. Additionally, the proposed framework was employed to analyze the Voynich manuscript, which was found to be compatible with texts written in natural languages. Taken together, our findings suggest that the proposed methodology can be combined with traditional network models to improve text classification tasks.
Labelled network subgraphs reveal stylistic subtleties in written texts
Nov 08, 2017



The vast amount of data and increase of computational capacity have allowed the analysis of texts from several perspectives, including the representation of texts as complex networks. Nodes of the network represent the words, and edges represent some relationship, usually word co-occurrence. Even though networked representations have been applied to study some tasks, such approaches are not usually combined with traditional models relying upon statistical paradigms. Because networked models are able to grasp textual patterns, we devised a hybrid classifier, called labelled subgraphs, that combines the frequency of common words with small structures found in the topology of the network, known as motifs. Our approach is illustrated in two contexts, authorship attribution and translationese identification. In the former, a set of novels written by different authors is analyzed. To identify translationese, texts from the Canadian Hansard and the European parliament were classified as to original and translated instances. Our results suggest that labelled subgraphs are able to represent texts and it should be further explored in other tasks, such as the analysis of text complexity, language proficiency, and machine translation.
An Image Analysis Approach to the Calligraphy of Books
Aug 24, 2017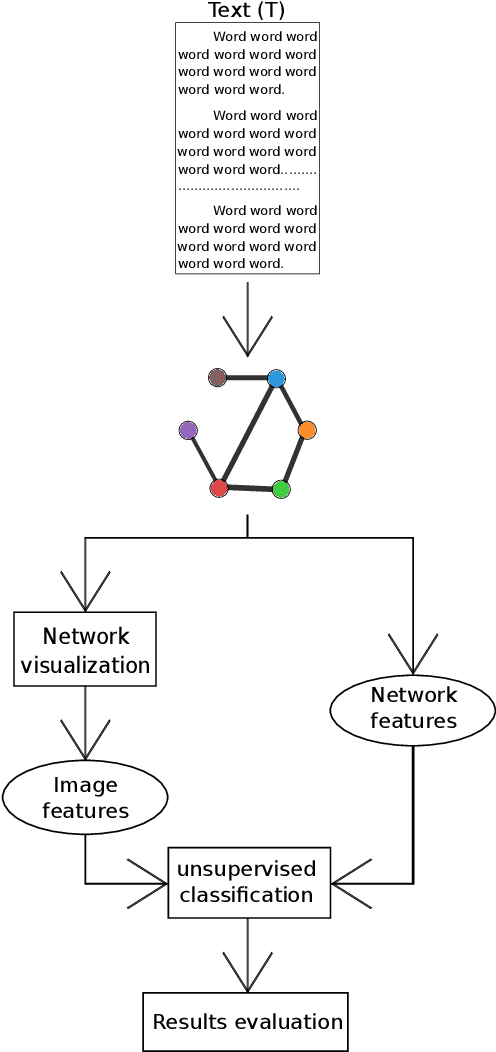
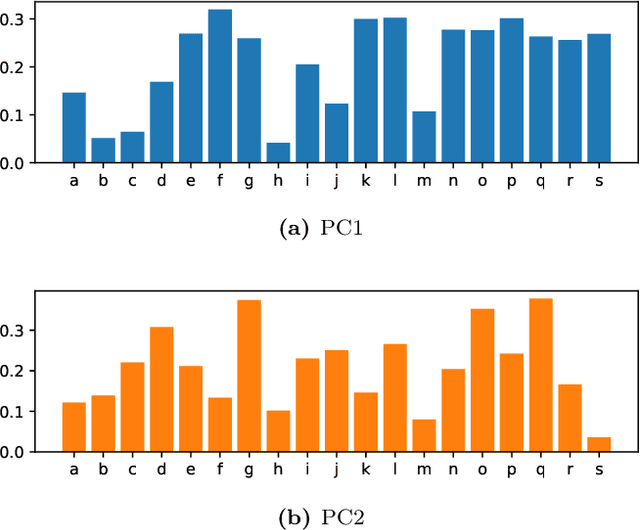
Text network analysis has received increasing attention as a consequence of its wide range of applications. In this work, we extend a previous work founded on the study of topological features of mesoscopic networks. Here, the geometrical properties of visualized networks are quantified in terms of several image analysis techniques and used as subsidies for authorship attribution. It was found that the visual features account for performance similar to that achieved by using topological measurements. In addition, the combination of these two types of features improved the performance.
PELESent: Cross-domain polarity classification using distant supervision
Jul 09, 2017
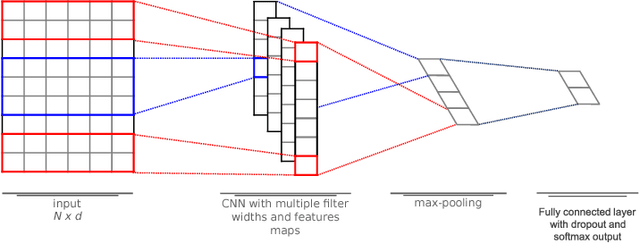
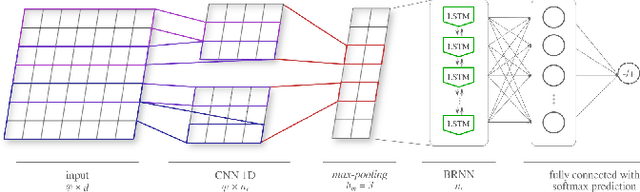
The enormous amount of texts published daily by Internet users has fostered the development of methods to analyze this content in several natural language processing areas, such as sentiment analysis. The main goal of this task is to classify the polarity of a message. Even though many approaches have been proposed for sentiment analysis, some of the most successful ones rely on the availability of large annotated corpus, which is an expensive and time-consuming process. In recent years, distant supervision has been used to obtain larger datasets. So, inspired by these techniques, in this paper we extend such approaches to incorporate popular graphic symbols used in electronic messages, the emojis, in order to create a large sentiment corpus for Portuguese. Trained on almost one million tweets, several models were tested in both same domain and cross-domain corpora. Our methods obtained very competitive results in five annotated corpora from mixed domains (Twitter and product reviews), which proves the domain-independent property of such approach. In addition, our results suggest that the combination of emoticons and emojis is able to properly capture the sentiment of a message.
On the "Calligraphy" of Books
May 29, 2017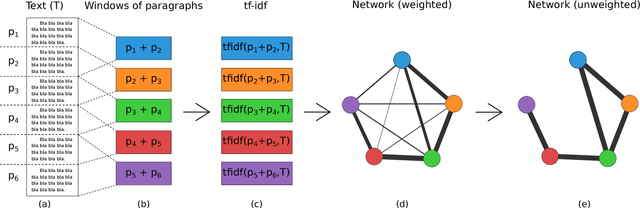

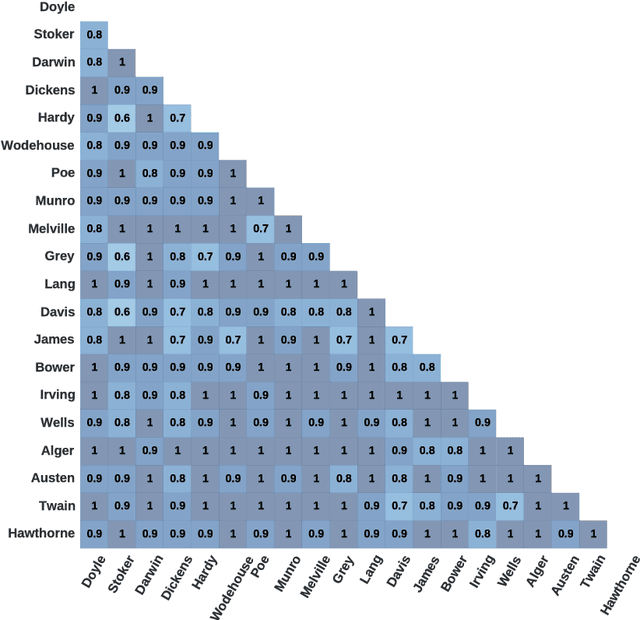
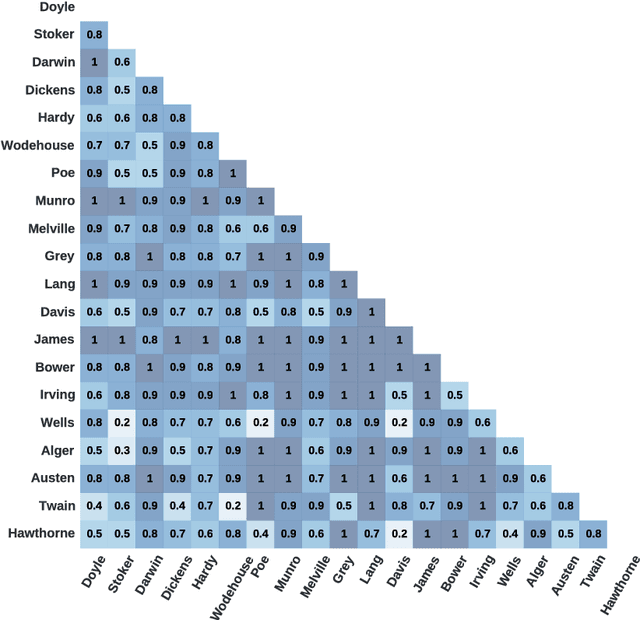
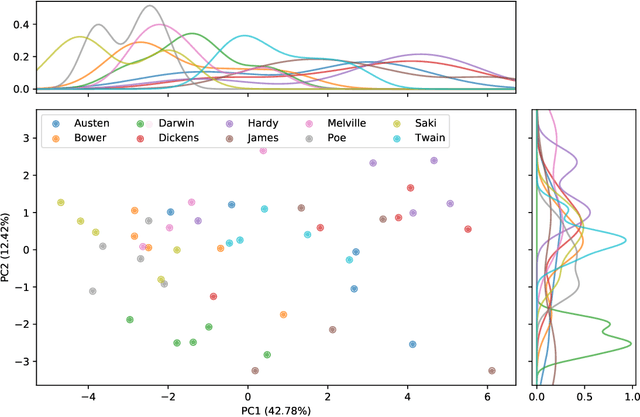
Authorship attribution is a natural language processing task that has been widely studied, often by considering small order statistics. In this paper, we explore a complex network approach to assign the authorship of texts based on their mesoscopic representation, in an attempt to capture the flow of the narrative. Indeed, as reported in this work, such an approach allowed the identification of the dominant narrative structure of the studied authors. This has been achieved due to the ability of the mesoscopic approach to take into account relationships between different, not necessarily adjacent, parts of the text, which is able to capture the story flow. The potential of the proposed approach has been illustrated through principal component analysis, a comparison with the chance baseline method, and network visualization. Such visualizations reveal individual characteristics of the authors, which can be understood as a kind of calligraphy.
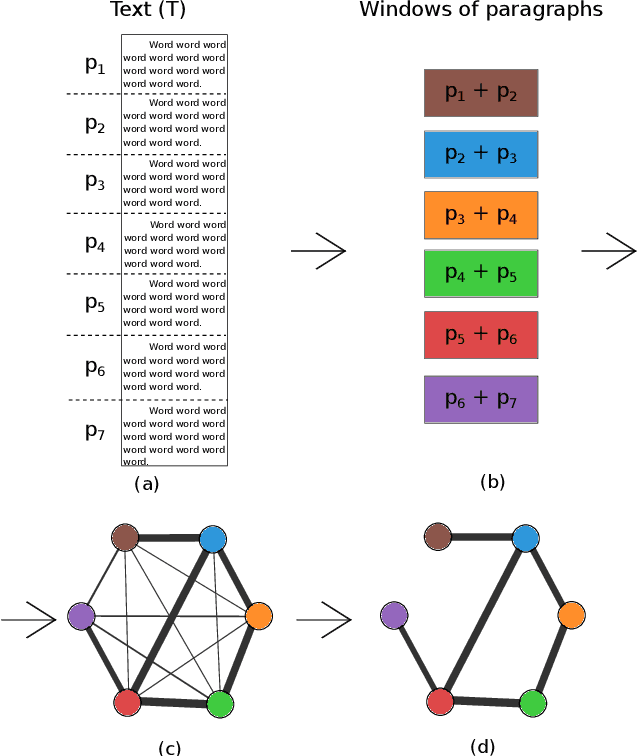
Representation of texts as complex networks: a mesoscopic approach
Feb 25, 2017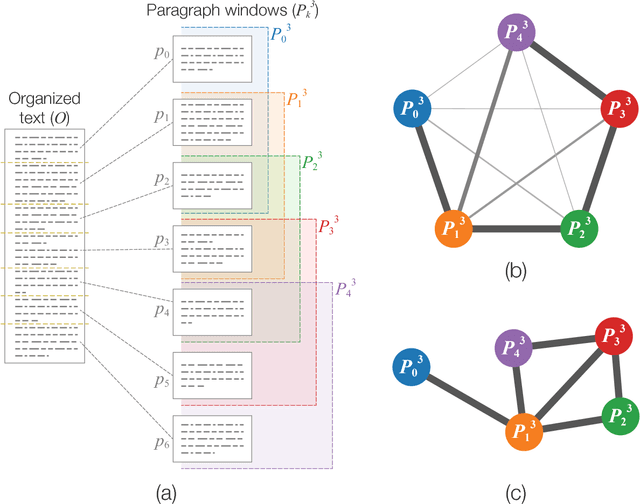
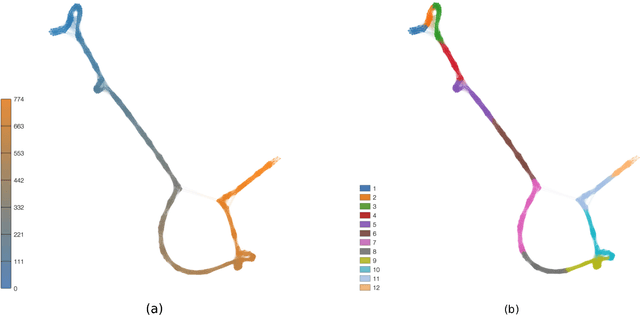
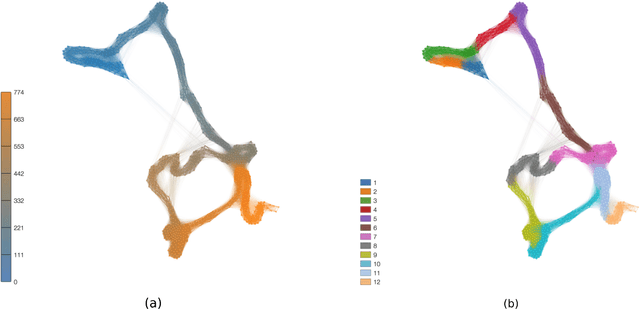
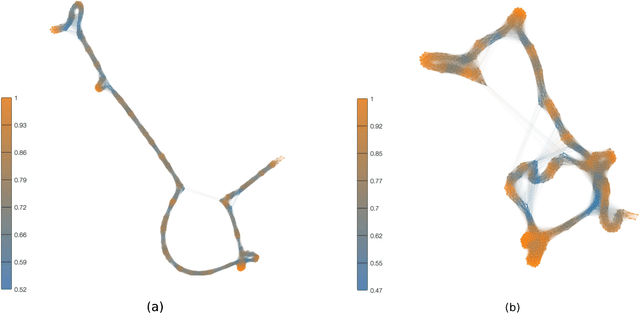
Statistical techniques that analyze texts, referred to as text analytics, have departed from the use of simple word count statistics towards a new paradigm. Text mining now hinges on a more sophisticated set of methods, including the representations in terms of complex networks. While well-established word-adjacency (co-occurrence) methods successfully grasp syntactical features of written texts, they are unable to represent important aspects of textual data, such as its topical structure, i.e. the sequence of subjects developing at a mesoscopic level along the text. Such aspects are often overlooked by current methodologies. In order to grasp the mesoscopic characteristics of semantical content in written texts, we devised a network model which is able to analyze documents in a multi-scale fashion. In the proposed model, a limited amount of adjacent paragraphs are represented as nodes, which are connected whenever they share a minimum semantical content. To illustrate the capabilities of our model, we present, as a case example, a qualitative analysis of "Alice's Adventures in Wonderland". We show that the mesoscopic structure of a document, modeled as a network, reveals many semantic traits of texts. Such an approach paves the way to a myriad of semantic-based applications. In addition, our approach is illustrated in a machine learning context, in which texts are classified among real texts and randomized instances.