 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting the U.S. building types from OpenStreetMap data
Sep 09, 2024


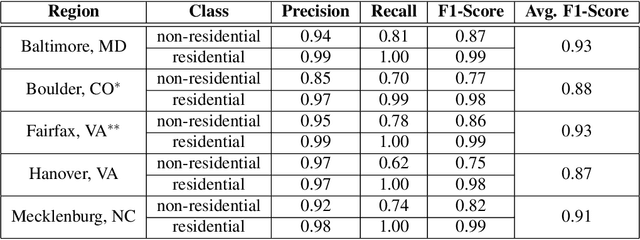
Building type information is crucial for population estimation, traffic planning, urban planning, and emergency response applications. Although essential, such data is often not readily available. To alleviate this problem, this work creates a comprehensive dataset by providing residential/non-residential building classification covering the entire United States. We propose and utilize an unsupervised machine learning method to classify building types based on building footprints and available OpenStreetMap information. The classification result is validated using authoritative ground truth data for select counties in the U.S. The validation shows a high precision for non-residential building classification and a high recall for residential buildings. We identified various approaches to improving the quality of the classification, such as removing sheds and garages from the dataset. Furthermore, analyzing the misclassifications revealed that they are mainly due to missing and scarce metadata in OSM. A major result of this work is the resulting dataset of classifying 67,705,475 buildings. We hope that this data is of value to the scientific community, including urban and transportation planners.
Using Full-Text Content to Characterize and Identify Best Seller Books
Oct 05, 2022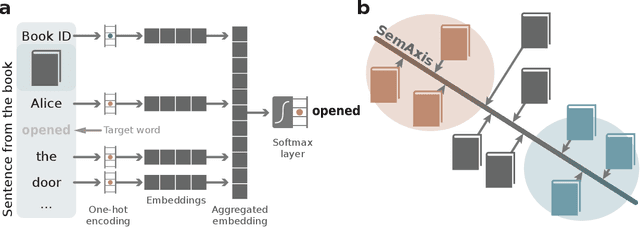
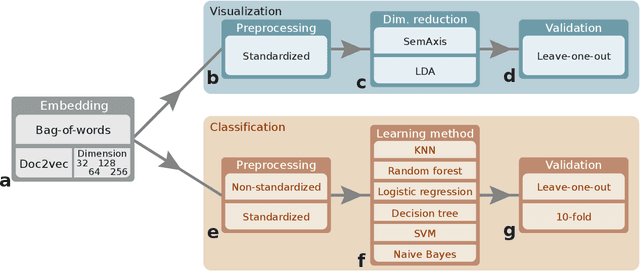


Artistic pieces can be studied from several perspectives, one example being their reception among readers over time. In the present work, we approach this interesting topic from the standpoint of literary works, particularly assessing the task of predicting whether a book will become a best seller. Dissimilarly from previous approaches, we focused on the full content of books and considered visualization and classification tasks. We employed visualization for the preliminary exploration of the data structure and properties, involving SemAxis and linear discriminant analyses. Then, to obtain quantitative and more objective results, we employed various classifiers. Such approaches were used along with a dataset containing (i) books published from 1895 to 1924 and consecrated as best sellers by the \emph{Publishers Weekly Bestseller Lists} and (ii) literary works published in the same period but not being mentioned in that list. Our comparison of methods revealed that the best-achieved result - combining a bag-of-words representation with a logistic regression classifier - led to an average accuracy of 0.75 both for the leave-one-out and 10-fold cross-validations. Such an outcome suggests that it is unfeasible to predict the success of books with high accuracy using only the full content of the texts. Nevertheless, our findings provide insights into the factors leading to the relative success of a literary work.
Accessibility and Trajectory-Based Text Characterization
Jan 17, 2022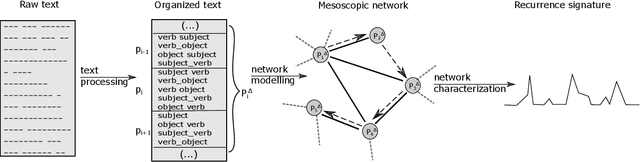
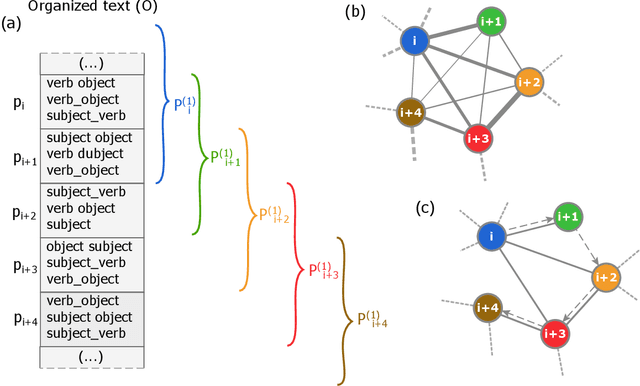
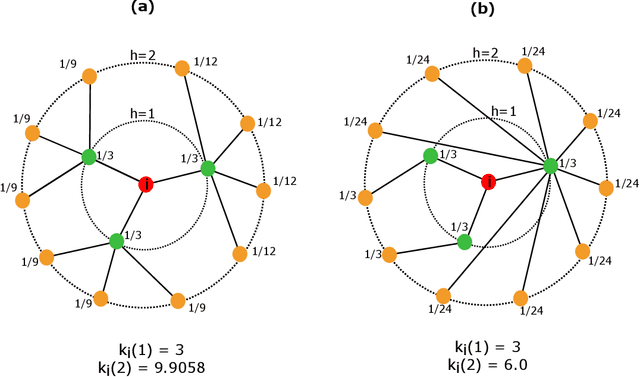
Several complex systems are characterized by presenting intricate characteristics extending along many scales. These characterizations are used in various applications, including text classification, better understanding of diseases, and comparison between cities, among others. In particular, texts are also characterized by a hierarchical structure that can be approached by using multi-scale concepts and methods. The present work aims at developing these possibilities while focusing on mesoscopic representations of networks. More specifically, we adopt an extension to the mesoscopic approach to represent text narratives, in which only the recurrent relationships among tagged parts of speech are considered to establish connections among sequential pieces of text (e.g., paragraphs). The characterization of the texts was then achieved by considering scale-dependent complementary methods: accessibility, symmetry and recurrence signatures. In order to evaluate the potential of these concepts and methods, we approached the problem of distinguishing between literary genres (fiction and non-fiction). A set of 300 books organized into the two genres was considered and were compared by using the aforementioned approaches. All the methods were capable of differentiating to some extent between the two genres. The accessibility and symmetry reflected the narrative asymmetries, while the recurrence signature provide a more direct indication about the non-sequential semantic connections taking place along the narrative.
A pattern recognition approach for distinguishing between prose and poetry
Jul 18, 2021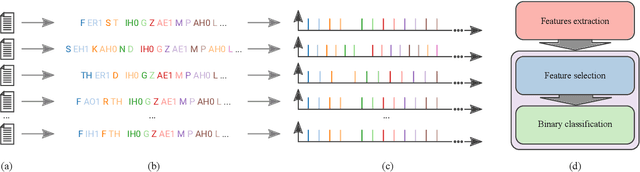
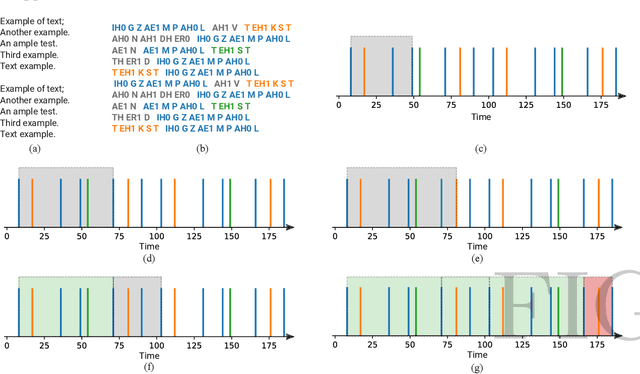


Poetry and prose are written artistic expressions that help us to appreciate the reality we live. Each of these styles has its own set of subjective properties, such as rhyme and rhythm, which are easily caught by a human reader's eye and ear. With the recent advances in artificial intelligence, the gap between humans and machines may have decreased, and today we observe algorithms mastering tasks that were once exclusively performed by humans. In this paper, we propose an automated method to distinguish between poetry and prose based solely on aural and rhythmic properties. In other to compare prose and poetry rhythms, we represent the rhymes and phones as temporal sequences and thus we propose a procedure for extracting rhythmic features from these sequences. The classification of the considered texts using the set of features extracted resulted in a best accuracy of 0.78, obtained with a neural network. Interestingly, by using an approach based on complex networks to visualize the similarities between the different texts considered, we found that the patterns of poetry vary much more than prose. Consequently, a much richer and complex set of rhythmic possibilities tends to be found in that modality.
How Coupled are Mass Spectrometry and Capillary Electrophoresis?
Oct 18, 2019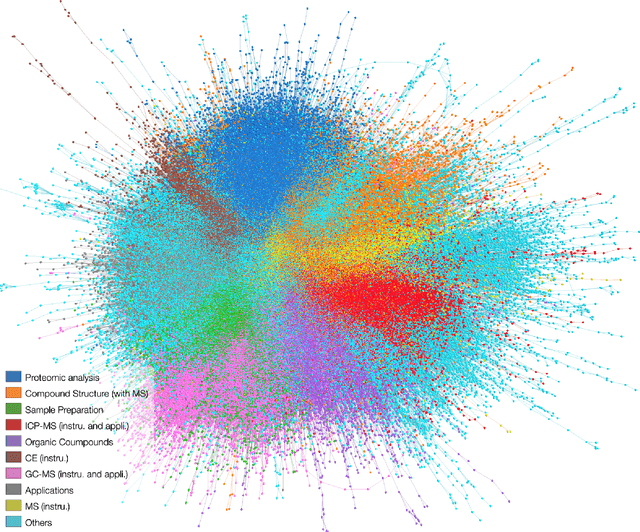

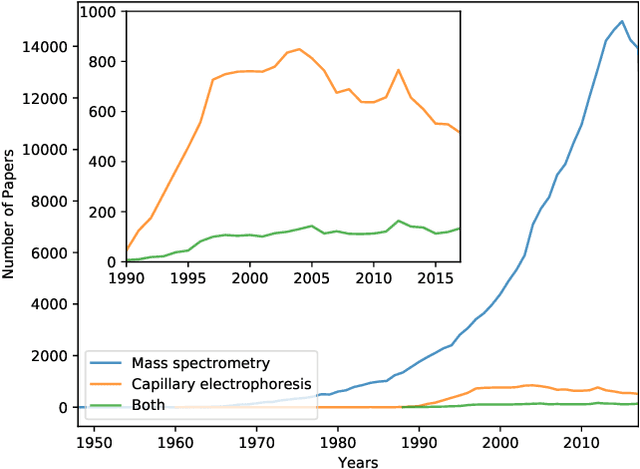
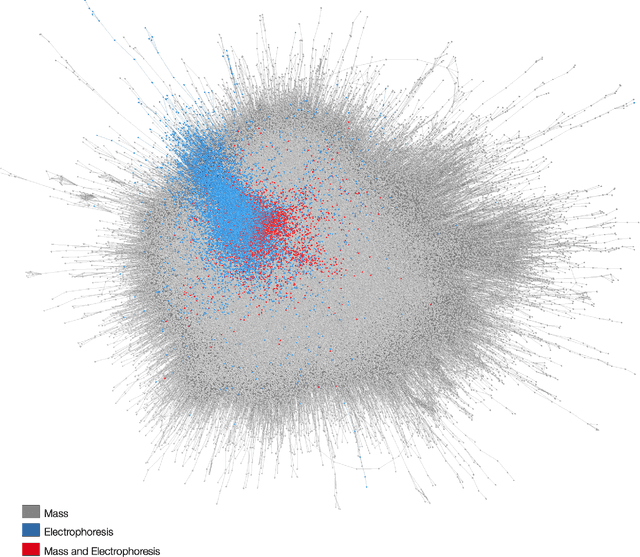
The understanding of how science works can contribute to making scientific development more effective. In this paper, we report an analysis of the organization and interconnection between two important issues in chemistry, namely mass spectrometry (MS) and capillary electrophoresis (CE). For that purpose, we employed science of science techniques based on complex networks. More specifically, we considered a citation network in which the nodes and connections represent papers and citations, respectively. Interesting results were found, including a good separation between some clusters of articles devoted to instrumentation techniques and applications. However, the papers that describe CE-MS did not lead to a well-defined cluster. In order to better understand the organization of the citation network, we considered a multi-scale analysis, in which we used the information regarding sub-clusters. Firstly, we analyzed the sub-cluster of the first article devoted to the coupling between CE and MS, which was found to be a good representation of its sub-cluster. The second analysis was about the sub-cluster of a seminal paper known to be the first that dealt with proteins by using CE-MS. By considering the proposed methodologies, our paper paves the way for researchers working with both techniques, since it elucidates the knowledge organization and can therefore lead to better literature reviews.
Paragraph-based complex networks: application to document classification and authenticity verification
Jun 22, 2018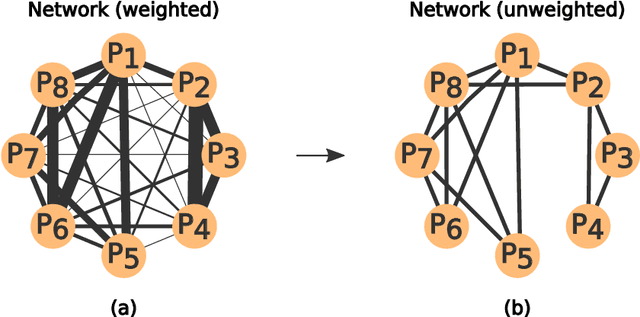
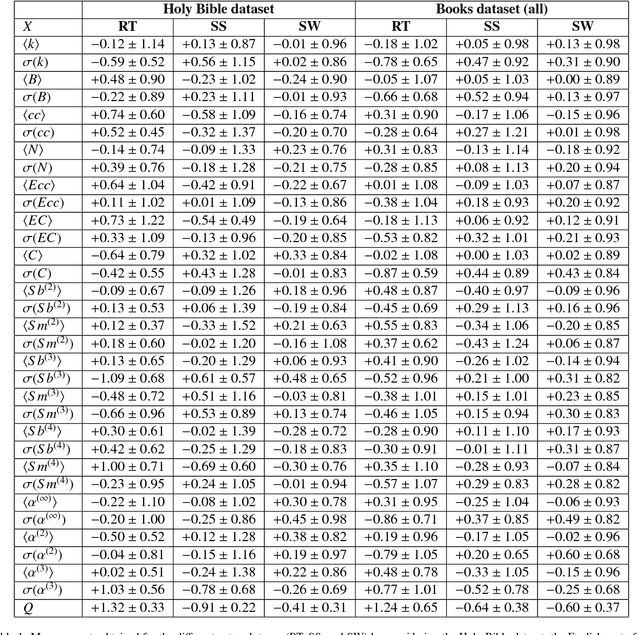
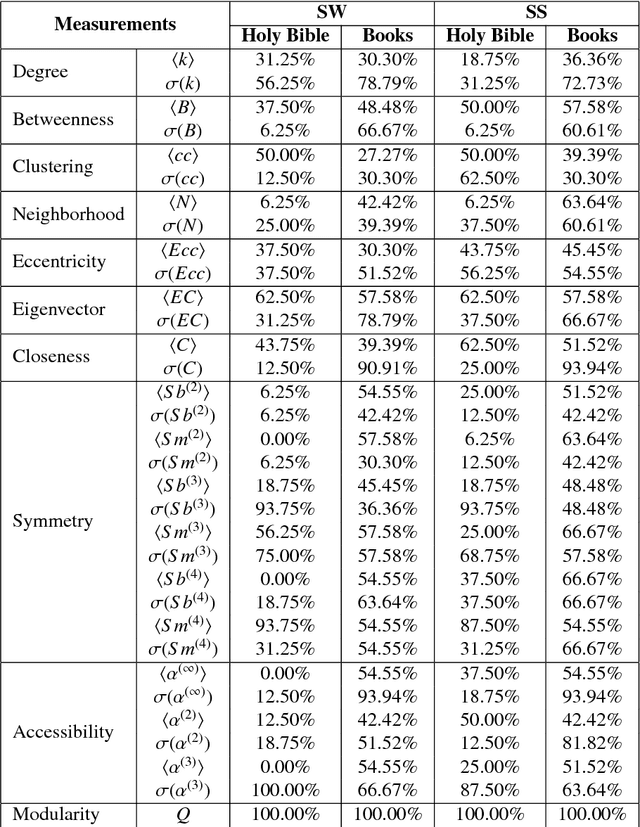
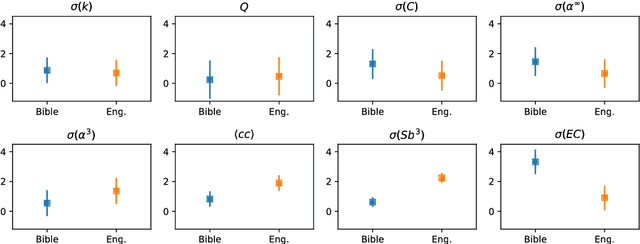
With the increasing number of texts made available on the Internet, many applications have relied on text mining tools to tackle a diversity of problems. A relevant model to represent texts is the so-called word adjacency (co-occurrence) representation, which is known to capture mainly syntactical features of texts.In this study, we introduce a novel network representation that considers the semantic similarity between paragraphs. Two main properties of paragraph networks are considered: (i) their ability to incorporate characteristics that can discriminate real from artificial, shuffled manuscripts and (ii) their ability to capture syntactical and semantic textual features. Our results revealed that real texts are organized into communities, which turned out to be an important feature for discriminating them from artificial texts. Interestingly, we have also found that, differently from traditional co-occurrence networks, the adopted representation is able to capture semantic features. Additionally, the proposed framework was employed to analyze the Voynich manuscript, which was found to be compatible with texts written in natural languages. Taken together, our findings suggest that the proposed methodology can be combined with traditional network models to improve text classification tasks.
An Image Analysis Approach to the Calligraphy of Books
Aug 24, 2017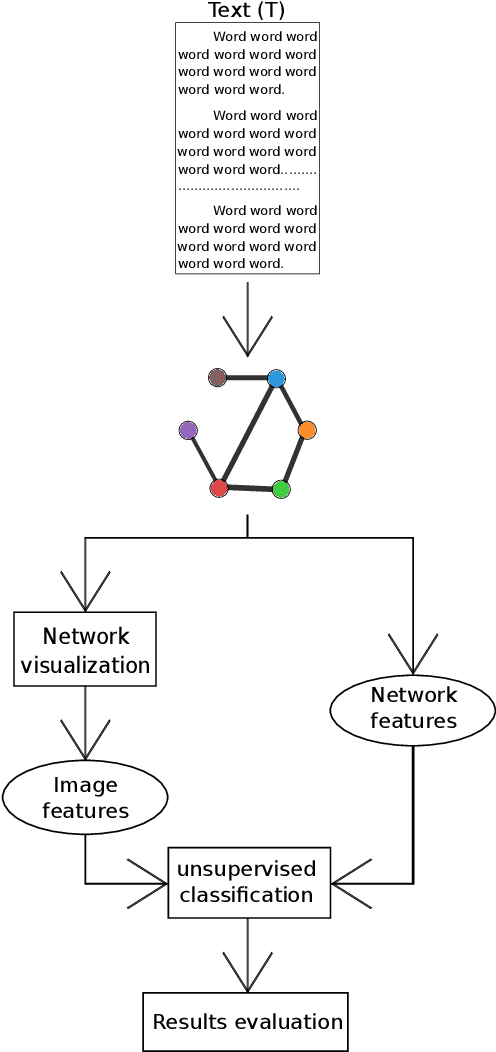
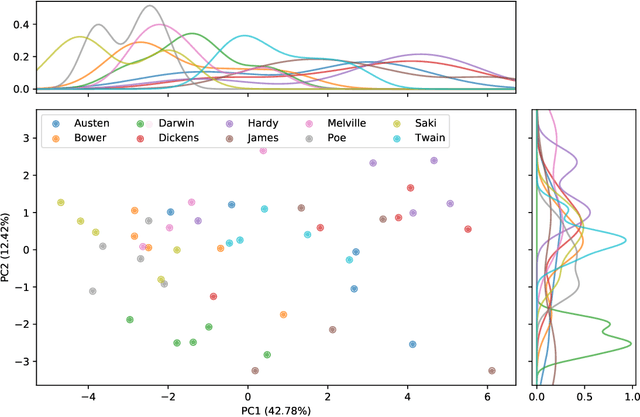
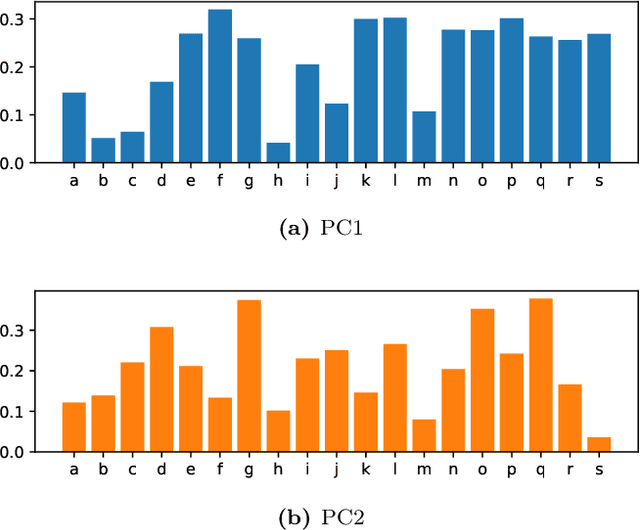
Text network analysis has received increasing attention as a consequence of its wide range of applications. In this work, we extend a previous work founded on the study of topological features of mesoscopic networks. Here, the geometrical properties of visualized networks are quantified in terms of several image analysis techniques and used as subsidies for authorship attribution. It was found that the visual features account for performance similar to that achieved by using topological measurements. In addition, the combination of these two types of features improved the performance.
On the "Calligraphy" of Books
May 29, 2017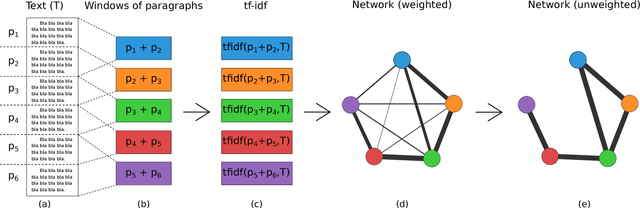

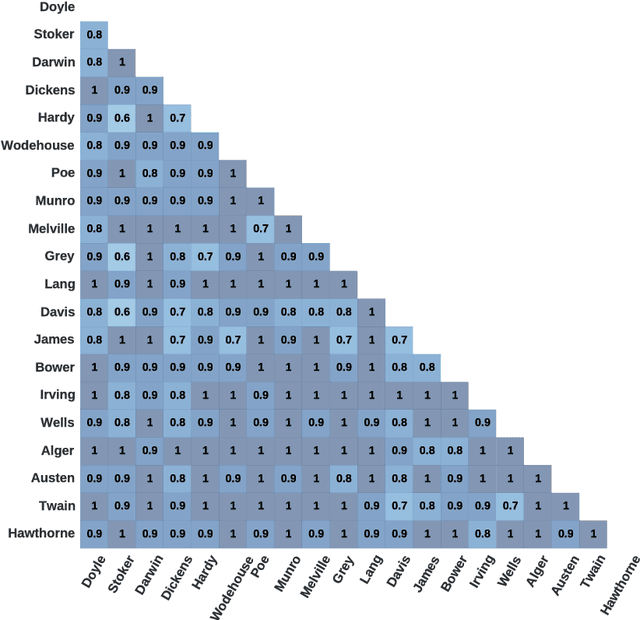
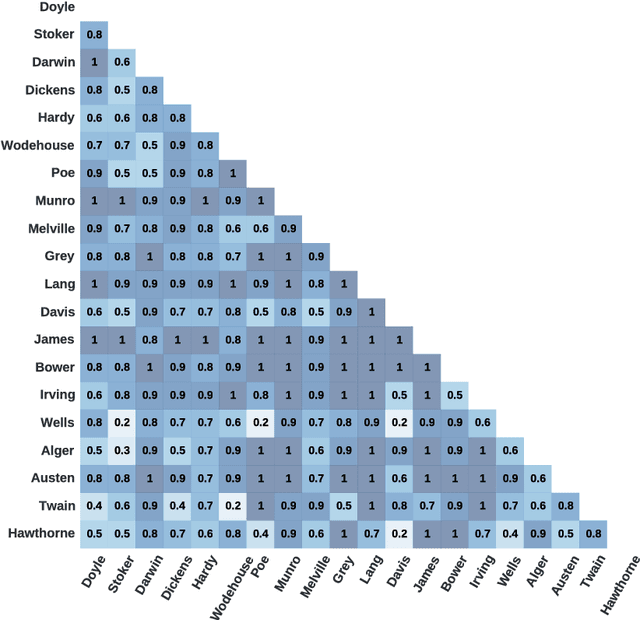
Authorship attribution is a natural language processing task that has been widely studied, often by considering small order statistics. In this paper, we explore a complex network approach to assign the authorship of texts based on their mesoscopic representation, in an attempt to capture the flow of the narrative. Indeed, as reported in this work, such an approach allowed the identification of the dominant narrative structure of the studied authors. This has been achieved due to the ability of the mesoscopic approach to take into account relationships between different, not necessarily adjacent, parts of the text, which is able to capture the story flow. The potential of the proposed approach has been illustrated through principal component analysis, a comparison with the chance baseline method, and network visualization. Such visualizations reveal individual characteristics of the authors, which can be understood as a kind of calligraphy.
Representation of texts as complex networks: a mesoscopic approach
Feb 25, 2017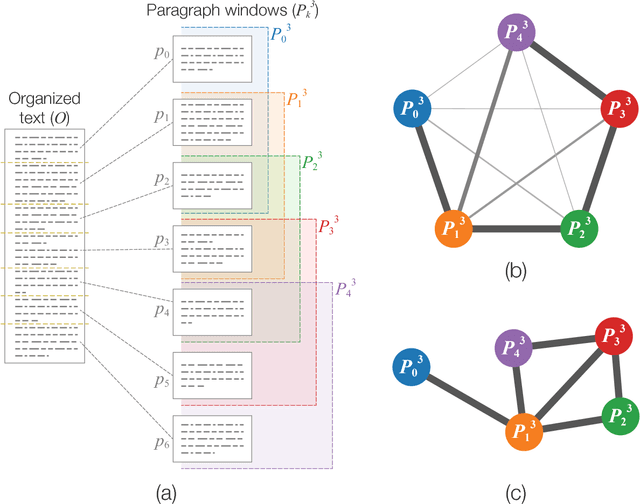
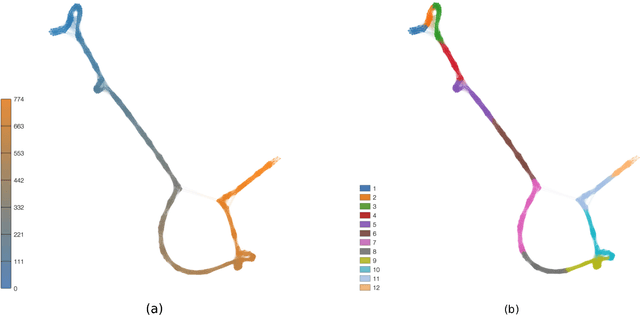
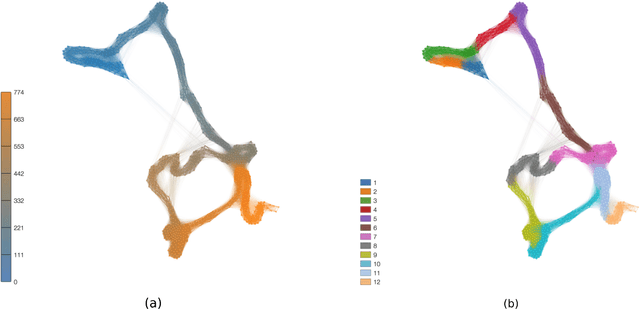
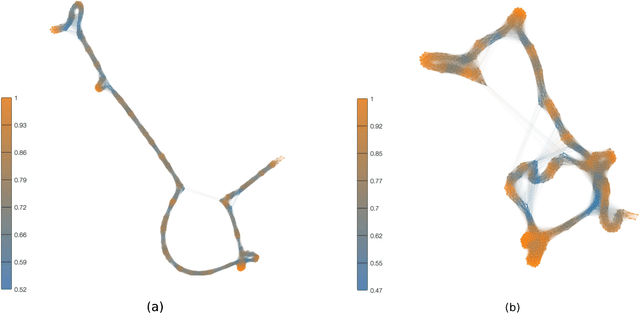
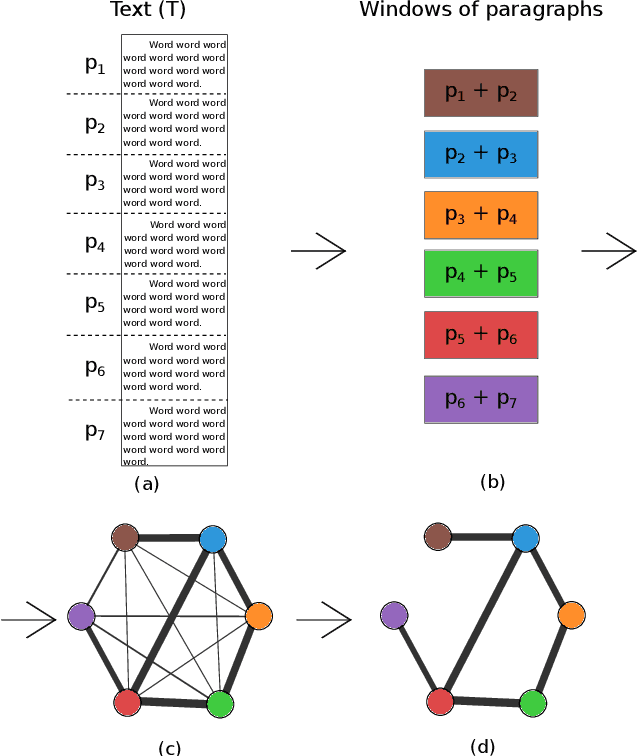
Statistical techniques that analyze texts, referred to as text analytics, have departed from the use of simple word count statistics towards a new paradigm. Text mining now hinges on a more sophisticated set of methods, including the representations in terms of complex networks. While well-established word-adjacency (co-occurrence) methods successfully grasp syntactical features of written texts, they are unable to represent important aspects of textual data, such as its topical structure, i.e. the sequence of subjects developing at a mesoscopic level along the text. Such aspects are often overlooked by current methodologies. In order to grasp the mesoscopic characteristics of semantical content in written texts, we devised a network model which is able to analyze documents in a multi-scale fashion. In the proposed model, a limited amount of adjacent paragraphs are represented as nodes, which are connected whenever they share a minimum semantical content. To illustrate the capabilities of our model, we present, as a case example, a qualitative analysis of "Alice's Adventures in Wonderland". We show that the mesoscopic structure of a document, modeled as a network, reveals many semantic traits of texts. Such an approach paves the way to a myriad of semantic-based applications. In addition, our approach is illustrated in a machine learning context, in which texts are classified among real texts and randomized instances.
Topic segmentation via community detection in complex networks
Dec 04, 2015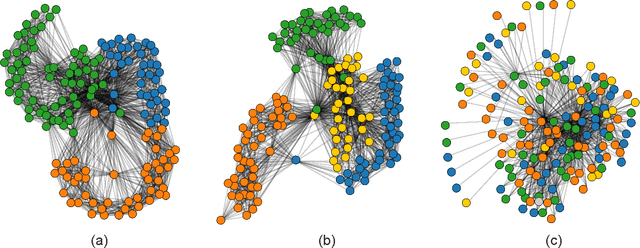

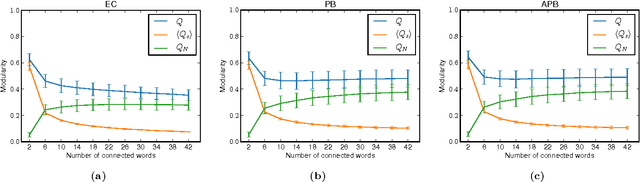
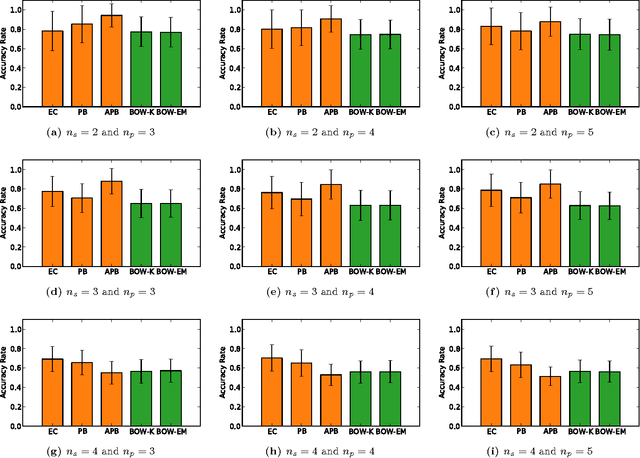
Many real systems have been modelled in terms of network concepts, and written texts are a particular example of information networks. In recent years, the use of network methods to analyze language has allowed the discovery of several interesting findings, including the proposition of novel models to explain the emergence of fundamental universal patterns. While syntactical networks, one of the most prevalent networked models of written texts, display both scale-free and small-world properties, such representation fails in capturing other textual features, such as the organization in topics or subjects. In this context, we propose a novel network representation whose main purpose is to capture the semantical relationships of words in a simple way. To do so, we link all words co-occurring in the same semantic context, which is defined in a threefold way. We show that the proposed representations favours the emergence of communities of semantically related words, and this feature may be used to identify relevant topics. The proposed methodology to detect topics was applied to segment selected Wikipedia articles. We have found that, in general, our methods outperform traditional bag-of-words representations, which suggests that a high-level textual representation may be useful to study semantical features of texts.