 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Full-Text Content to Characterize and Identify Best Seller Books
Oct 05, 2022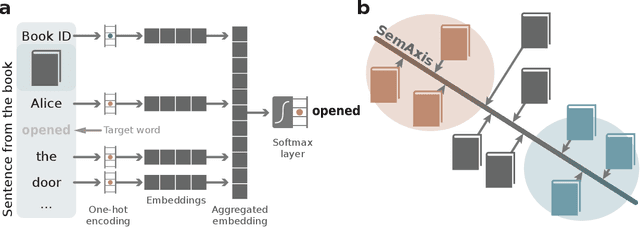
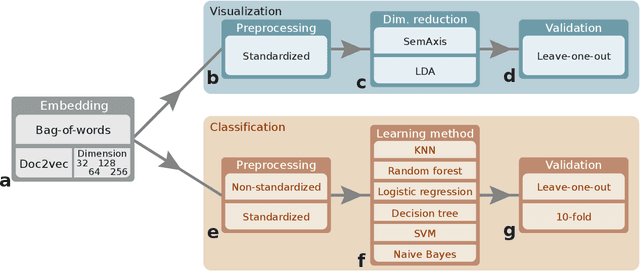


Artistic pieces can be studied from several perspectives, one example being their reception among readers over time. In the present work, we approach this interesting topic from the standpoint of literary works, particularly assessing the task of predicting whether a book will become a best seller. Dissimilarly from previous approaches, we focused on the full content of books and considered visualization and classification tasks. We employed visualization for the preliminary exploration of the data structure and properties, involving SemAxis and linear discriminant analyses. Then, to obtain quantitative and more objective results, we employed various classifiers. Such approaches were used along with a dataset containing (i) books published from 1895 to 1924 and consecrated as best sellers by the \emph{Publishers Weekly Bestseller Lists} and (ii) literary works published in the same period but not being mentioned in that list. Our comparison of methods revealed that the best-achieved result - combining a bag-of-words representation with a logistic regression classifier - led to an average accuracy of 0.75 both for the leave-one-out and 10-fold cross-validations. Such an outcome suggests that it is unfeasible to predict the success of books with high accuracy using only the full content of the texts. Nevertheless, our findings provide insights into the factors leading to the relative success of a literary work.
Accessibility and Trajectory-Based Text Characterization
Jan 17, 2022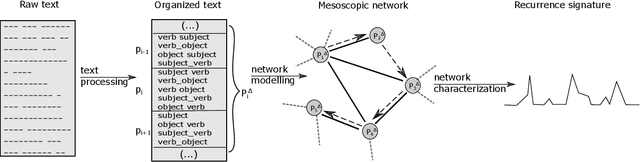
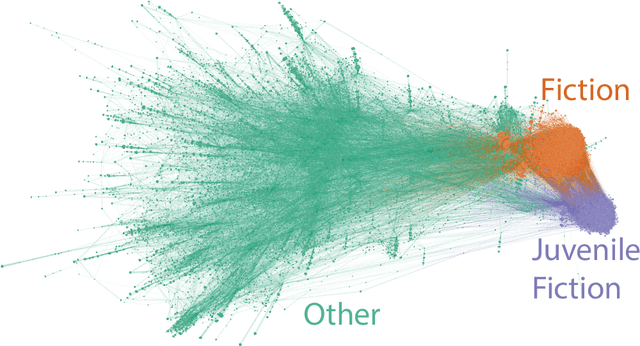
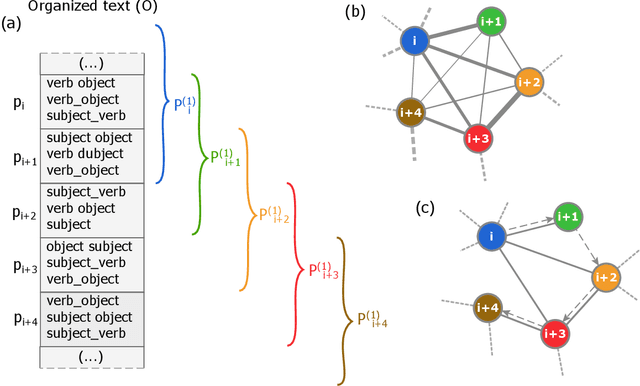
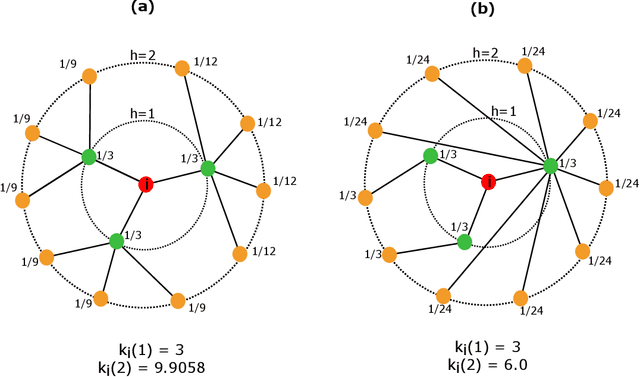
Several complex systems are characterized by presenting intricate characteristics extending along many scales. These characterizations are used in various applications, including text classification, better understanding of diseases, and comparison between cities, among others. In particular, texts are also characterized by a hierarchical structure that can be approached by using multi-scale concepts and methods. The present work aims at developing these possibilities while focusing on mesoscopic representations of networks. More specifically, we adopt an extension to the mesoscopic approach to represent text narratives, in which only the recurrent relationships among tagged parts of speech are considered to establish connections among sequential pieces of text (e.g., paragraphs). The characterization of the texts was then achieved by considering scale-dependent complementary methods: accessibility, symmetry and recurrence signatures. In order to evaluate the potential of these concepts and methods, we approached the problem of distinguishing between literary genres (fiction and non-fiction). A set of 300 books organized into the two genres was considered and were compared by using the aforementioned approaches. All the methods were capable of differentiating to some extent between the two genres. The accessibility and symmetry reflected the narrative asymmetries, while the recurrence signature provide a more direct indication about the non-sequential semantic connections taking place along the narrative.