 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Prediction Explainability through Sparse Communication
Apr 28, 2020

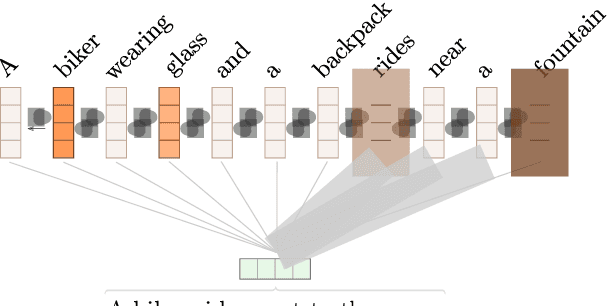
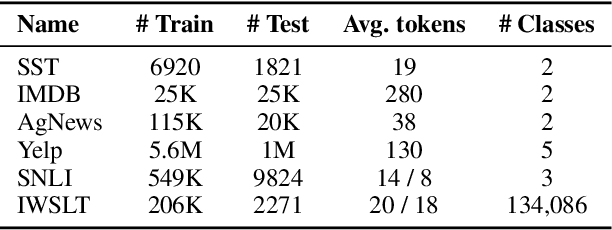
Explainability is a topic of growing importance in NLP. In this work, we provide a unified perspective of explainability as a communication problem between an explainer and a layperson about a classifier's decision. We use this framework to compare several prior approaches for extracting explanations, including gradient methods, representation erasure, and attention mechanisms, in terms of their communication success. In addition, we reinterpret these methods at the light of classical feature selection, and we use this as inspiration to propose new embedded methods for explainability, through the use of selective, sparse attention. Experiments in text classification, natural language entailment, and machine translation, using different configurations of explainers and laypeople (including both machines and humans), reveal an advantage of attention-based explainers over gradient and erasure methods. Furthermore, human evaluation experiments show promising results with post-hoc explainers trained to optimize communication success and faithfulness.
Evaluating Word Embeddings for Sentence Boundary Detection in Speech Transcripts
Aug 15, 2017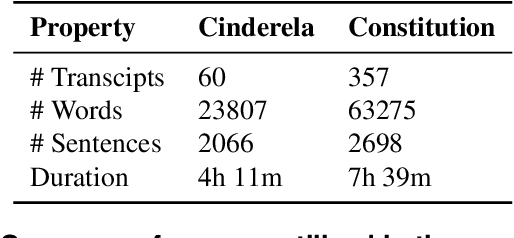
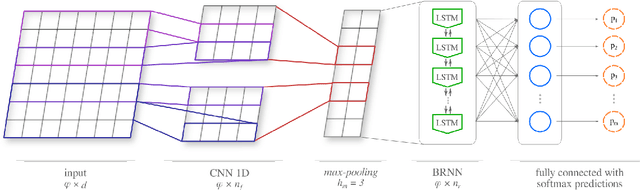
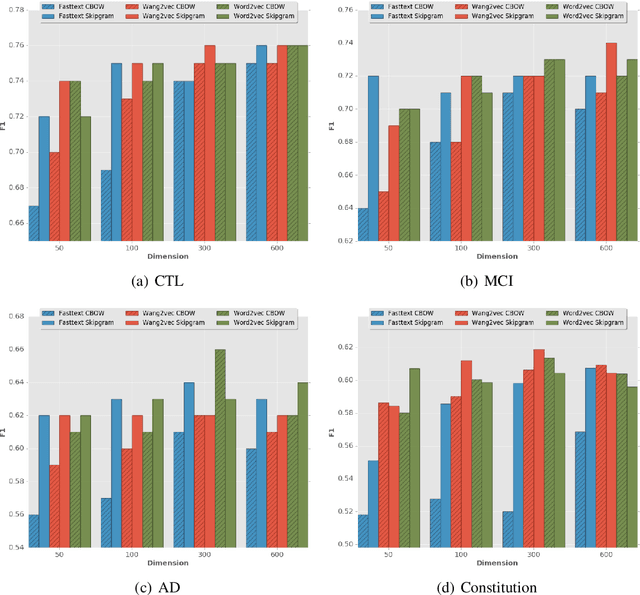
This paper is motivated by the automation of neuropsychological tests involving discourse analysis in the retellings of narratives by patients with potential cognitive impairment. In this scenario the task of sentence boundary detection in speech transcripts is important as discourse analysis involves the application of Natural Language Processing tools, such as taggers and parsers, which depend on the sentence as a processing unit. Our aim in this paper is to verify which embedding induction method works best for the sentence boundary detection task, specifically whether it be those which were proposed to capture semantic, syntactic or morphological similarities.
PELESent: Cross-domain polarity classification using distant supervision
Jul 09, 2017
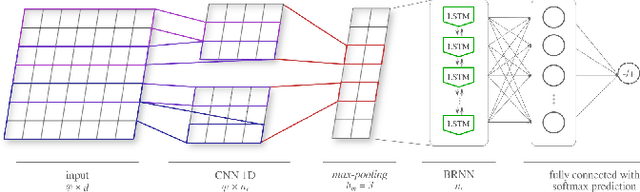
The enormous amount of texts published daily by Internet users has fostered the development of methods to analyze this content in several natural language processing areas, such as sentiment analysis. The main goal of this task is to classify the polarity of a message. Even though many approaches have been proposed for sentiment analysis, some of the most successful ones rely on the availability of large annotated corpus, which is an expensive and time-consuming process. In recent years, distant supervision has been used to obtain larger datasets. So, inspired by these techniques, in this paper we extend such approaches to incorporate popular graphic symbols used in electronic messages, the emojis, in order to create a large sentiment corpus for Portuguese. Trained on almost one million tweets, several models were tested in both same domain and cross-domain corpora. Our methods obtained very competitive results in five annotated corpora from mixed domains (Twitter and product reviews), which proves the domain-independent property of such approach. In addition, our results suggest that the combination of emoticons and emojis is able to properly capture the sentiment of a message.