 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePELESent: Cross-domain polarity classification using distant supervision
Jul 09, 2017
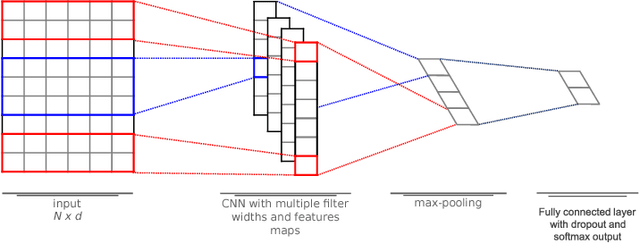
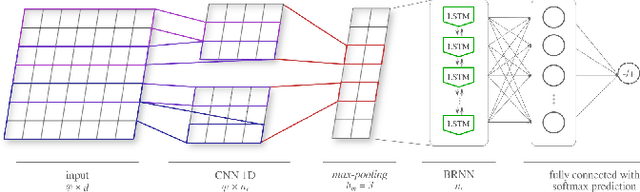
The enormous amount of texts published daily by Internet users has fostered the development of methods to analyze this content in several natural language processing areas, such as sentiment analysis. The main goal of this task is to classify the polarity of a message. Even though many approaches have been proposed for sentiment analysis, some of the most successful ones rely on the availability of large annotated corpus, which is an expensive and time-consuming process. In recent years, distant supervision has been used to obtain larger datasets. So, inspired by these techniques, in this paper we extend such approaches to incorporate popular graphic symbols used in electronic messages, the emojis, in order to create a large sentiment corpus for Portuguese. Trained on almost one million tweets, several models were tested in both same domain and cross-domain corpora. Our methods obtained very competitive results in five annotated corpora from mixed domains (Twitter and product reviews), which proves the domain-independent property of such approach. In addition, our results suggest that the combination of emoticons and emojis is able to properly capture the sentiment of a message.
A Lightweight Regression Method to Infer Psycholinguistic Properties for Brazilian Portuguese
May 19, 2017


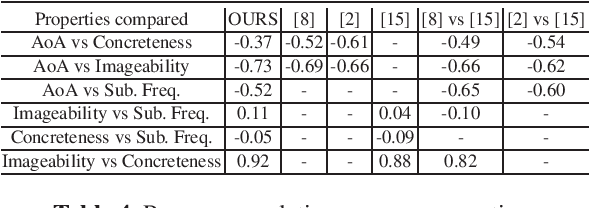
Psycholinguistic properties of words have been used in various approaches to Natural Language Processing tasks, such as text simplification and readability assessment. Most of these properties are subjective, involving costly and time-consuming surveys to be gathered. Recent approaches use the limited datasets of psycholinguistic properties to extend them automatically to large lexicons. However, some of the resources used by such approaches are not available to most languages. This study presents a method to infer psycholinguistic properties for Brazilian Portuguese (BP) using regressors built with a light set of features usually available for less resourced languages: word length, frequency lists, lexical databases composed of school dictionaries and word embedding models. The correlations between the properties inferred are close to those obtained by related works. The resulting resource contains 26,874 words in BP annotated with concreteness, age of acquisition, imageability and subjective frequency.
Enriching Complex Networks with Word Embeddings for Detecting Mild Cognitive Impairment from Speech Transcripts
Apr 26, 2017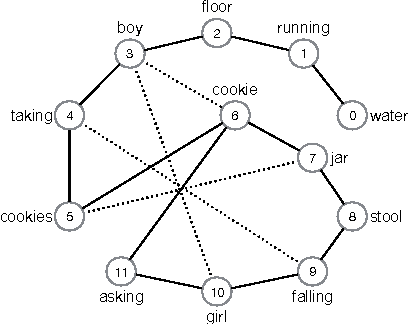
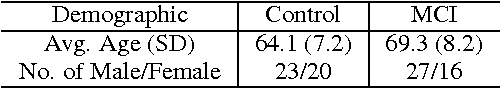


Mild Cognitive Impairment (MCI) is a mental disorder difficult to diagnose. Linguistic features, mainly from parsers, have been used to detect MCI, but this is not suitable for large-scale assessments. MCI disfluencies produce non-grammatical speech that requires manual or high precision automatic correction of transcripts. In this paper, we modeled transcripts into complex networks and enriched them with word embedding (CNE) to better represent short texts produced in neuropsychological assessments. The network measurements were applied with well-known classifiers to automatically identify MCI in transcripts, in a binary classification task. A comparison was made with the performance of traditional approaches using Bag of Words (BoW) and linguistic features for three datasets: DementiaBank in English, and Cinderella and Arizona-Battery in Portuguese. Overall, CNE provided higher accuracy than using only complex networks, while Support Vector Machine was superior to other classifiers. CNE provided the highest accuracies for DementiaBank and Cinderella, but BoW was more efficient for the Arizona-Battery dataset probably owing to its short narratives. The approach using linguistic features yielded higher accuracy if the transcriptions of the Cinderella dataset were manually revised. Taken together, the results indicate that complex networks enriched with embedding is promising for detecting MCI in large-scale assessments