 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Report on the Complex Word Identification Shared Task 2018
Apr 24, 2018
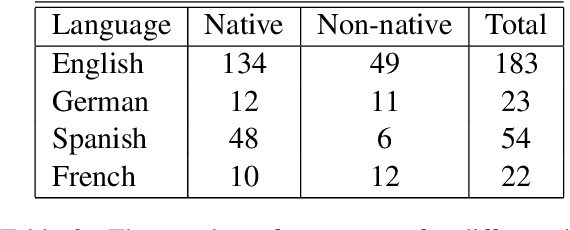
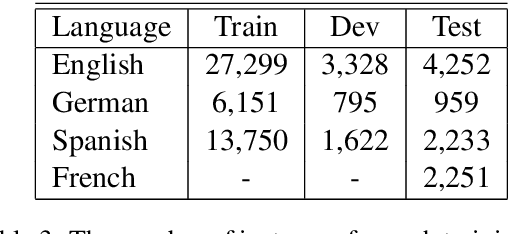
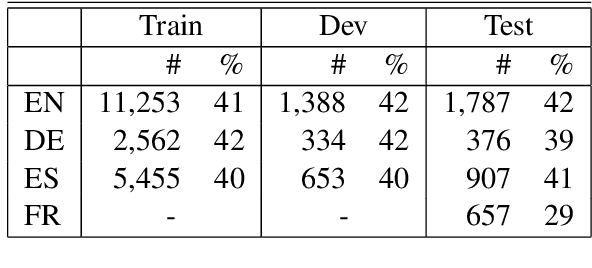
We report the findings of the second Complex Word Identification (CWI) shared task organized as part of the BEA workshop co-located with NAACL-HLT'2018. The second CWI shared task featured multilingual and multi-genre datasets divided into four tracks: English monolingual, German monolingual, Spanish monolingual, and a multilingual track with a French test set, and two tasks: binary classification and probabilistic classification. A total of 12 teams submitted their results in different task/track combinations and 11 of them wrote system description papers that are referred to in this report and appear in the BEA workshop proceedings.
A Lightweight Regression Method to Infer Psycholinguistic Properties for Brazilian Portuguese
May 19, 2017


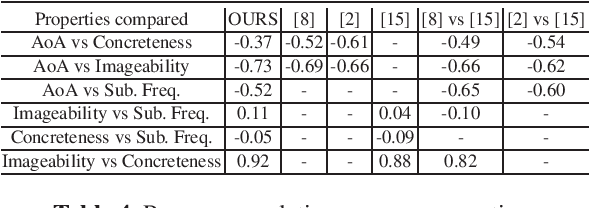
Psycholinguistic properties of words have been used in various approaches to Natural Language Processing tasks, such as text simplification and readability assessment. Most of these properties are subjective, involving costly and time-consuming surveys to be gathered. Recent approaches use the limited datasets of psycholinguistic properties to extend them automatically to large lexicons. However, some of the resources used by such approaches are not available to most languages. This study presents a method to infer psycholinguistic properties for Brazilian Portuguese (BP) using regressors built with a light set of features usually available for less resourced languages: word length, frequency lists, lexical databases composed of school dictionaries and word embedding models. The correlations between the properties inferred are close to those obtained by related works. The resulting resource contains 26,874 words in BP annotated with concreteness, age of acquisition, imageability and subjective frequency.