 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the role of words in the network structure of texts: application to authorship attribution
May 11, 2017



Well-established automatic analyses of texts mainly consider frequencies of linguistic units, e.g. letters, words and bigrams, while methods based on co-occurrence networks consider the structure of texts regardless of the nodes label (i.e. the words semantics). In this paper, we reconcile these distinct viewpoints by introducing a generalized similarity measure to compare texts which accounts for both the network structure of texts and the role of individual words in the networks. We use the similarity measure for authorship attribution of three collections of books, each composed of 8 authors and 10 books per author. High accuracy rates were obtained with typical values from 90% to 98.75%, much higher than with the traditional the TF-IDF approach for the same collections. These accuracies are also higher than taking only the topology of networks into account. We conclude that the different properties of specific words on the macroscopic scale structure of a whole text are as relevant as their frequency of appearance; conversely, considering the identity of nodes brings further knowledge about a piece of text represented as a network.
Enriching Complex Networks with Word Embeddings for Detecting Mild Cognitive Impairment from Speech Transcripts
Apr 26, 2017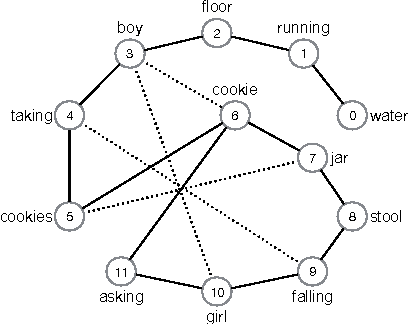
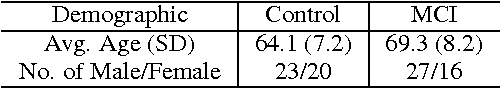


Mild Cognitive Impairment (MCI) is a mental disorder difficult to diagnose. Linguistic features, mainly from parsers, have been used to detect MCI, but this is not suitable for large-scale assessments. MCI disfluencies produce non-grammatical speech that requires manual or high precision automatic correction of transcripts. In this paper, we modeled transcripts into complex networks and enriched them with word embedding (CNE) to better represent short texts produced in neuropsychological assessments. The network measurements were applied with well-known classifiers to automatically identify MCI in transcripts, in a binary classification task. A comparison was made with the performance of traditional approaches using Bag of Words (BoW) and linguistic features for three datasets: DementiaBank in English, and Cinderella and Arizona-Battery in Portuguese. Overall, CNE provided higher accuracy than using only complex networks, while Support Vector Machine was superior to other classifiers. CNE provided the highest accuracies for DementiaBank and Cinderella, but BoW was more efficient for the Arizona-Battery dataset probably owing to its short narratives. The approach using linguistic features yielded higher accuracy if the transcriptions of the Cinderella dataset were manually revised. Taken together, the results indicate that complex networks enriched with embedding is promising for detecting MCI in large-scale assessments
Text authorship identified using the dynamics of word co-occurrence networks
Jul 29, 2016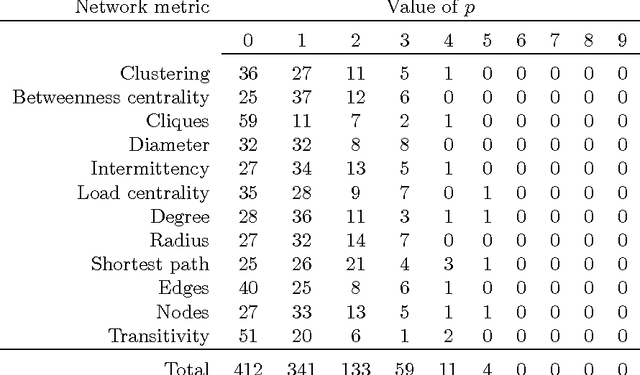
The identification of authorship in disputed documents still requires human expertise, which is now unfeasible for many tasks owing to the large volumes of text and authors in practical applications. In this study, we introduce a methodology based on the dynamics of word co-occurrence networks representing written texts to classify a corpus of 80 texts by 8 authors. The texts were divided into sections with equal number of linguistic tokens, from which time series were created for 12 topological metrics. The series were proven to be stationary (p-value>0.05), which permits to use distribution moments as learning attributes. With an optimized supervised learning procedure using a Radial Basis Function Network, 68 out of 80 texts were correctly classified, i.e. a remarkable 85% author matching success rate. Therefore, fluctuations in purely dynamic network metrics were found to characterize authorship, thus opening the way for the description of texts in terms of small evolving networks. Moreover, the approach introduced allows for comparison of texts with diverse characteristics in a simple, fast fashion.