 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Emotion Dynamics of Literary Novels
Mar 04, 2024



Stories are rich in the emotions they exhibit in their narratives and evoke in the readers. The emotional journeys of the various characters within a story are central to their appeal. Computational analysis of the emotions of novels, however, has rarely examined the variation in the emotional trajectories of the different characters within them, instead considering the entire novel to represent a single story arc. In this work, we use character dialogue to distinguish between the emotion arcs of the narration and the various characters. We analyze the emotion arcs of the various characters in a dataset of English literary novels using the framework of Utterance Emotion Dynamics. Our findings show that the narration and the dialogue largely express disparate emotions through the course of a novel, and that the commonalities or differences in the emotional arcs of stories are more accurately captured by those associated with individual characters.
Improving Automatic Quotation Attribution in Literary Novels
Jul 07, 2023



Current models for quotation attribution in literary novels assume varying levels of available information in their training and test data, which poses a challenge for in-the-wild inference. Here, we approach quotation attribution as a set of four interconnected sub-tasks: character identification, coreference resolution, quotation identification, and speaker attribution. We benchmark state-of-the-art models on each of these sub-tasks independently, using a large dataset of annotated coreferences and quotations in literary novels (the Project Dialogism Novel Corpus). We also train and evaluate models for the speaker attribution task in particular, showing that a simple sequential prediction model achieves accuracy scores on par with state-of-the-art models.
The Project Dialogism Novel Corpus: A Dataset for Quotation Attribution in Literary Texts
Apr 12, 2022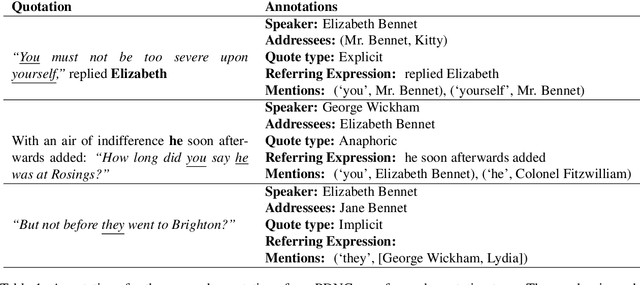
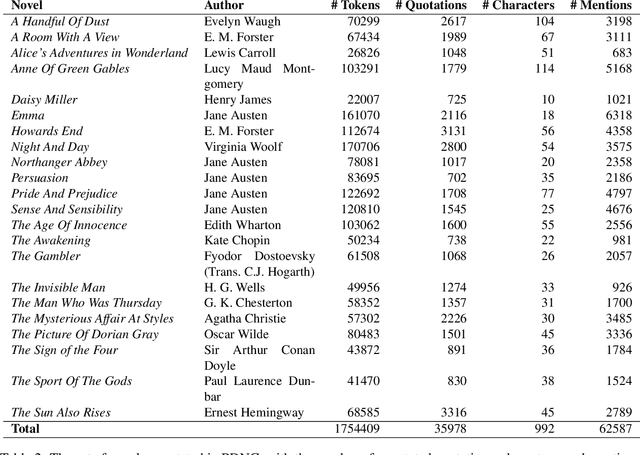

We present the Project Dialogism Novel Corpus, or PDNC, an annotated dataset of quotations for English literary texts. PDNC contains annotations for 35,978 quotations across 22 full-length novels, and is by an order of magnitude the largest corpus of its kind. Each quotation is annotated for the speaker, addressees, type of quotation, referring expression, and character mentions within the quotation text. The annotated attributes allow for a comprehensive evaluation of models of quotation attribution and coreference for literary texts.
Contextualized moral inference
Aug 25, 2020



Developing moral awareness in intelligent systems has shifted from a topic of philosophical inquiry to a critical and practical issue in artificial intelligence over the past decades. However, automated inference of everyday moral situations remains an under-explored problem. We present a text-based approach that predicts people's intuitive judgment of moral vignettes. Our methodology builds on recent work in contextualized language models and textual inference of moral sentiment. We show that a contextualized representation offers a substantial advantage over alternative representations based on word embeddings and emotion sentiment in inferring human moral judgment, evaluated and reflected in three independent datasets from moral psychology. We discuss the promise and limitations of our approach toward automated textual moral reasoning.
Text-based inference of moral sentiment change
Jan 20, 2020



We present a text-based framework for investigating moral sentiment change of the public via longitudinal corpora. Our framework is based on the premise that language use can inform people's moral perception toward right or wrong, and we build our methodology by exploring moral biases learned from diachronic word embeddings. We demonstrate how a parameter-free model supports inference of historical shifts in moral sentiment toward concepts such as slavery and democracy over centuries at three incremental levels: moral relevance, moral polarity, and fine-grained moral dimensions. We apply this methodology to visualizing moral time courses of individual concepts and analyzing the relations between psycholinguistic variables and rates of moral sentiment change at scale. Our work offers opportunities for applying natural language processing toward characterizing moral sentiment change in society.
Understanding Undesirable Word Embedding Associations
Aug 18, 2019
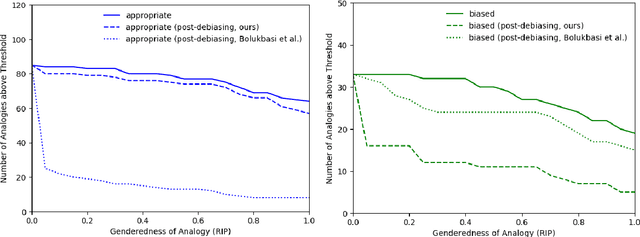

Word embeddings are often criticized for capturing undesirable word associations such as gender stereotypes. However, methods for measuring and removing such biases remain poorly understood. We show that for any embedding model that implicitly does matrix factorization, debiasing vectors post hoc using subspace projection (Bolukbasi et al., 2016) is, under certain conditions, equivalent to training on an unbiased corpus. We also prove that WEAT, the most common association test for word embeddings, systematically overestimates bias. Given that the subspace projection method is provably effective, we use it to derive a new measure of association called the $\textit{relational inner product association}$ (RIPA). Experiments with RIPA reveal that, on average, skipgram with negative sampling (SGNS) does not make most words any more gendered than they are in the training corpus. However, for gender-stereotyped words, SGNS actually amplifies the gender association in the corpus.
Towards Understanding Linear Word Analogies
Oct 27, 2018



A surprising property of word vectors is that vector algebra can often be used to solve word analogies. However, it is unclear why - and when - linear operators correspond to non-linear embedding models such as skip-gram with negative sampling (SGNS). We provide a rigorous explanation of this phenomenon without making the strong assumptions that past work has made about the vector space and word distribution. Our theory has several implications. Past work has often conjectured that linear structures exist in vector spaces because relations can be represented as ratios; we prove that this holds for SGNS. We provide novel theoretical justification for the addition of SGNS word vectors by showing that it automatically down-weights the more frequent word, as weighting schemes do ad hoc. Lastly, we offer an information theoretic interpretation of Euclidean distance in vector spaces, providing rigorous justification for its use in capturing word dissimilarity.
Labelled network subgraphs reveal stylistic subtleties in written texts
Nov 08, 2017



The vast amount of data and increase of computational capacity have allowed the analysis of texts from several perspectives, including the representation of texts as complex networks. Nodes of the network represent the words, and edges represent some relationship, usually word co-occurrence. Even though networked representations have been applied to study some tasks, such approaches are not usually combined with traditional models relying upon statistical paradigms. Because networked models are able to grasp textual patterns, we devised a hybrid classifier, called labelled subgraphs, that combines the frequency of common words with small structures found in the topology of the network, known as motifs. Our approach is illustrated in two contexts, authorship attribution and translationese identification. In the former, a set of novels written by different authors is analyzed. To identify translationese, texts from the Canadian Hansard and the European parliament were classified as to original and translated instances. Our results suggest that labelled subgraphs are able to represent texts and it should be further explored in other tasks, such as the analysis of text complexity, language proficiency, and machine translation.
Cross-Lingual Sentiment Analysis Without (Good) Translation
Oct 24, 2017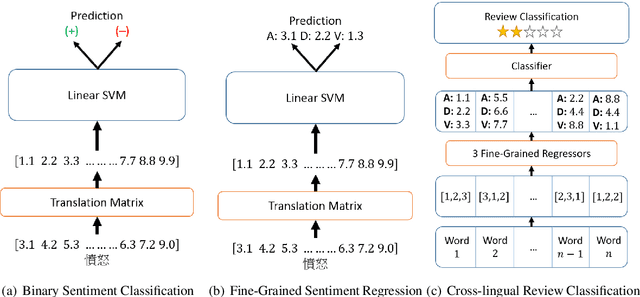

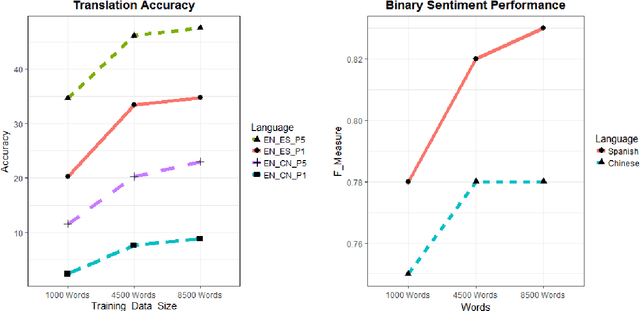
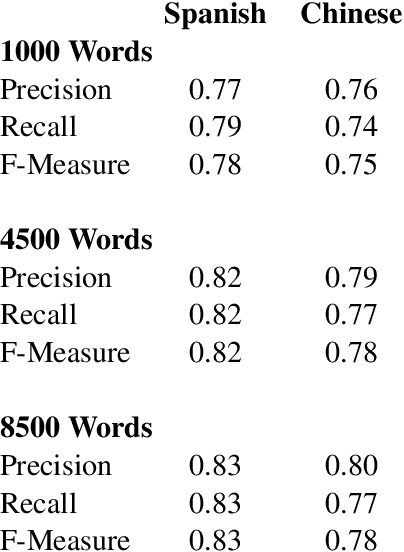
Current approaches to cross-lingual sentiment analysis try to leverage the wealth of labeled English data using bilingual lexicons, bilingual vector space embeddings, or machine translation systems. Here we show that it is possible to use a single linear transformation, with as few as 2000 word pairs, to capture fine-grained sentiment relationships between words in a cross-lingual setting. We apply these cross-lingual sentiment models to a diverse set of tasks to demonstrate their functionality in a non-English context. By effectively leveraging English sentiment knowledge without the need for accurate translation, we can analyze and extract features from other languages with scarce data at a very low cost, thus making sentiment and related analyses for many languages inexpensive.
Authorship attribution via network motifs identification
Jul 23, 2016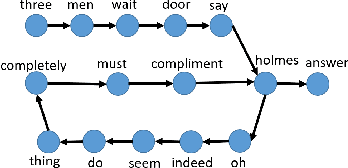
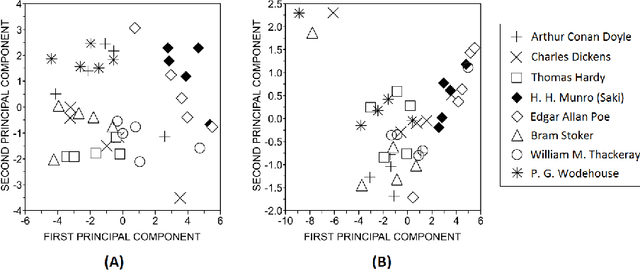
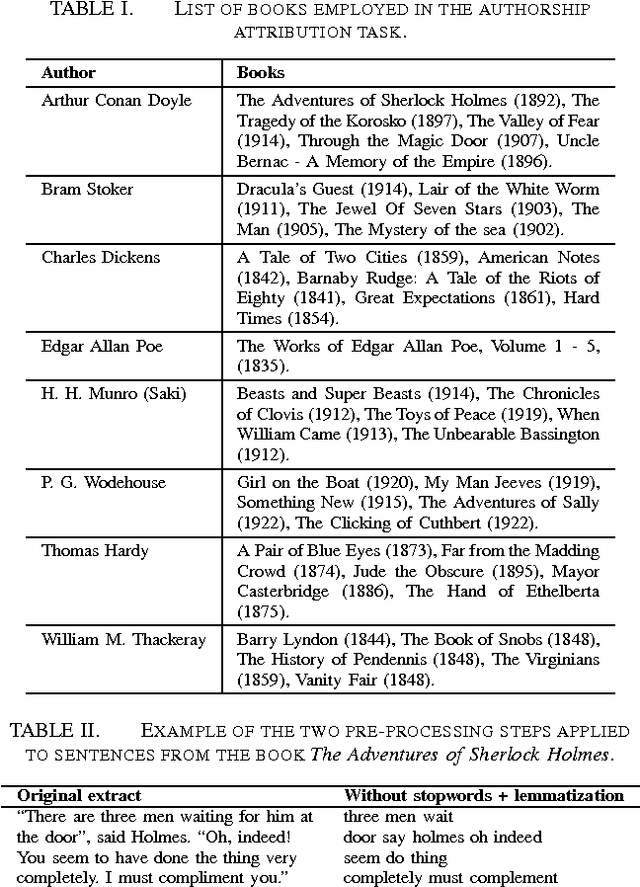
Concepts and methods of complex networks can be used to analyse texts at their different complexity levels. Examples of natural language processing (NLP) tasks studied via topological analysis of networks are keyword identification, automatic extractive summarization and authorship attribution. Even though a myriad of network measurements have been applied to study the authorship attribution problem, the use of motifs for text analysis has been restricted to a few works. The goal of this paper is to apply the concept of motifs, recurrent interconnection patterns, in the authorship attribution task. The absolute frequencies of all thirteen directed motifs with three nodes were extracted from the co-occurrence networks and used as classification features. The effectiveness of these features was verified with four machine learning methods. The results show that motifs are able to distinguish the writing style of different authors. In our best scenario, 57.5% of the books were correctly classified. The chance baseline for this problem is 12.5%. In addition, we have found that function words play an important role in these recurrent patterns. Taken together, our findings suggest that motifs should be further explored in other related linguistic tasks.
* Preprint submitted for the 5th Brazilian Conference on Intelligent Systems