 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Emotion Dynamics of Literary Novels
Mar 04, 2024



Stories are rich in the emotions they exhibit in their narratives and evoke in the readers. The emotional journeys of the various characters within a story are central to their appeal. Computational analysis of the emotions of novels, however, has rarely examined the variation in the emotional trajectories of the different characters within them, instead considering the entire novel to represent a single story arc. In this work, we use character dialogue to distinguish between the emotion arcs of the narration and the various characters. We analyze the emotion arcs of the various characters in a dataset of English literary novels using the framework of Utterance Emotion Dynamics. Our findings show that the narration and the dialogue largely express disparate emotions through the course of a novel, and that the commonalities or differences in the emotional arcs of stories are more accurately captured by those associated with individual characters.
Improving Automatic Quotation Attribution in Literary Novels
Jul 07, 2023



Current models for quotation attribution in literary novels assume varying levels of available information in their training and test data, which poses a challenge for in-the-wild inference. Here, we approach quotation attribution as a set of four interconnected sub-tasks: character identification, coreference resolution, quotation identification, and speaker attribution. We benchmark state-of-the-art models on each of these sub-tasks independently, using a large dataset of annotated coreferences and quotations in literary novels (the Project Dialogism Novel Corpus). We also train and evaluate models for the speaker attribution task in particular, showing that a simple sequential prediction model achieves accuracy scores on par with state-of-the-art models.
The Project Dialogism Novel Corpus: A Dataset for Quotation Attribution in Literary Texts
Apr 12, 2022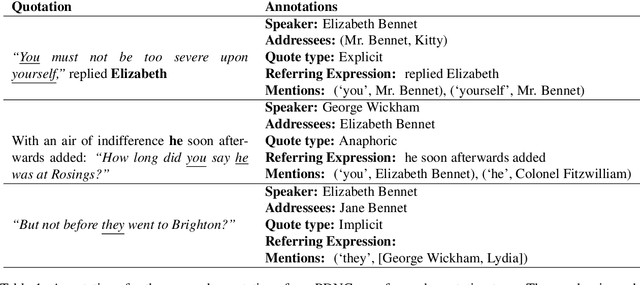
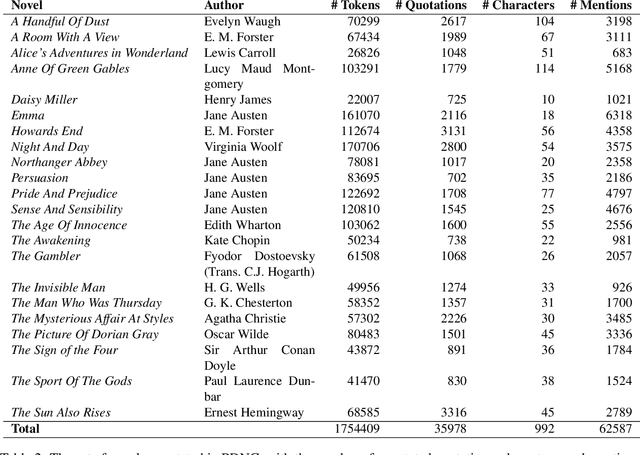

We present the Project Dialogism Novel Corpus, or PDNC, an annotated dataset of quotations for English literary texts. PDNC contains annotations for 35,978 quotations across 22 full-length novels, and is by an order of magnitude the largest corpus of its kind. Each quotation is annotated for the speaker, addressees, type of quotation, referring expression, and character mentions within the quotation text. The annotated attributes allow for a comprehensive evaluation of models of quotation attribution and coreference for literary texts.
Deep-speare: A Joint Neural Model of Poetic Language, Meter and Rhyme
Jul 10, 2018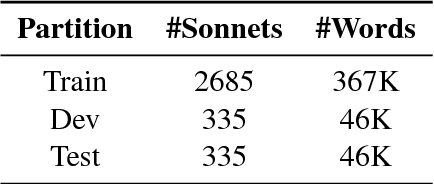

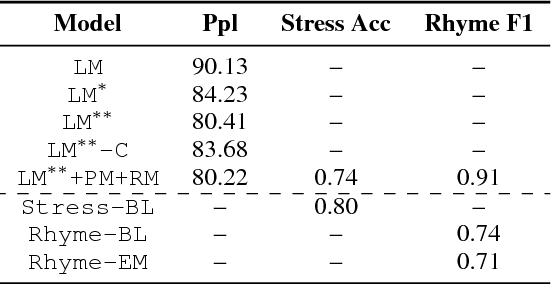
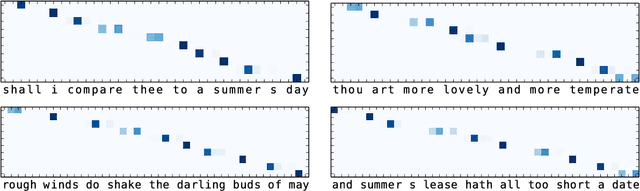
In this paper, we propose a joint architecture that captures language, rhyme and meter for sonnet modelling. We assess the quality of generated poems using crowd and expert judgements. The stress and rhyme models perform very well, as generated poems are largely indistinguishable from human-written poems. Expert evaluation, however, reveals that a vanilla language model captures meter implicitly, and that machine-generated poems still underperform in terms of readability and emotion. Our research shows the importance expert evaluation for poetry generation, and that future research should look beyond rhyme/meter and focus on poetic language.
* 11 pages; ACL2018