 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
Affect, Body, Cognition, Demographics, and Emotion: The ABCDE of Text Features for Computational Affective Science
Dec 19, 2025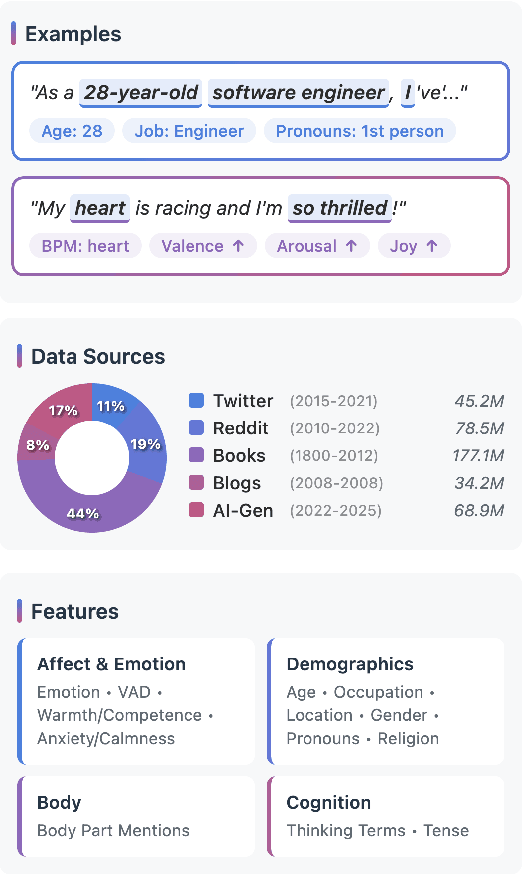
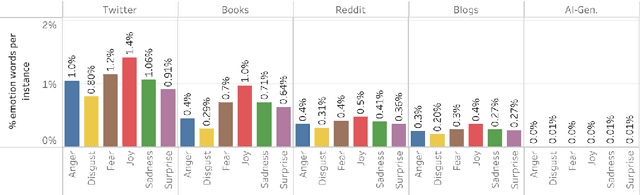
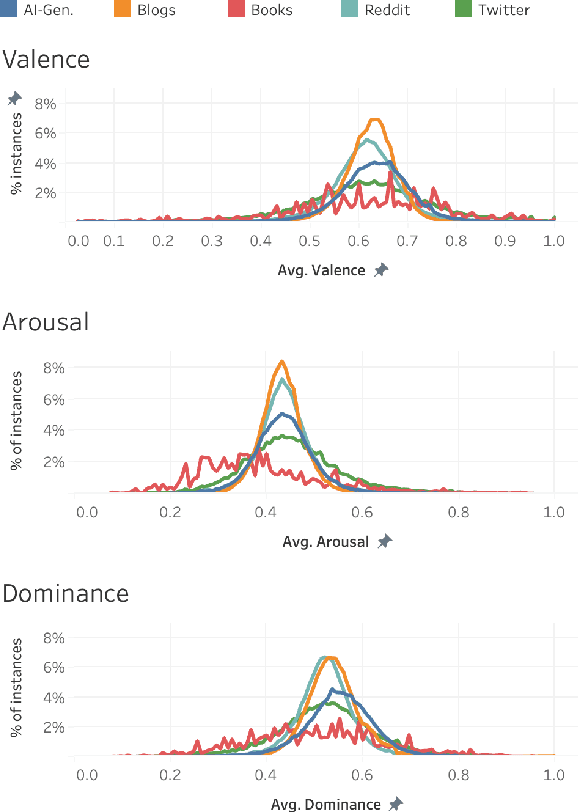

Work in Computational Affective Science and Computational Social Science explores a wide variety of research questions about people, emotions, behavior, and health. Such work often relies on language data that is first labeled with relevant information, such as the use of emotion words or the age of the speaker. Although many resources and algorithms exist to enable this type of labeling, discovering, accessing, and using them remains a substantial impediment, particularly for practitioners outside of computer science. Here, we present the ABCDE dataset (Affect, Body, Cognition, Demographics, and Emotion), a large-scale collection of over 400 million text utterances drawn from social media, blogs, books, and AI-generated sources. The dataset is annotated with a wide range of features relevant to computational affective and social science. ABCDE facilitates interdisciplinary research across numerous fields, including affective science, cognitive science, the digital humanities, sociology, political science, and computational linguistics.
The GPT-WritingPrompts Dataset: A Comparative Analysis of Character Portrayal in Short Stories
Jun 24, 2024The improved generative capabilities of large language models have made them a powerful tool for creative writing and storytelling. It is therefore important to quantitatively understand the nature of generated stories, and how they differ from human storytelling. We augment the Reddit WritingPrompts dataset with short stories generated by GPT-3.5, given the same prompts. We quantify and compare the emotional and descriptive features of storytelling from both generative processes, human and machine, along a set of six dimensions. We find that generated stories differ significantly from human stories along all six dimensions, and that human and machine generations display similar biases when grouped according to the narrative point-of-view and gender of the main protagonist. We release our dataset and code at https://github.com/KristinHuangg/gpt-writing-prompts.
SemEval Task 1: Semantic Textual Relatedness for African and Asian Languages
Apr 04, 2024

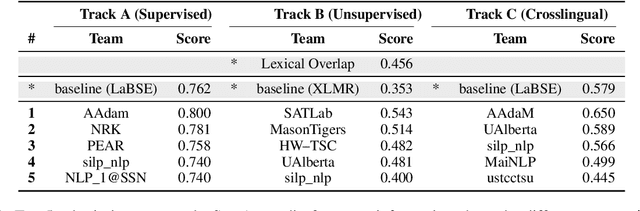
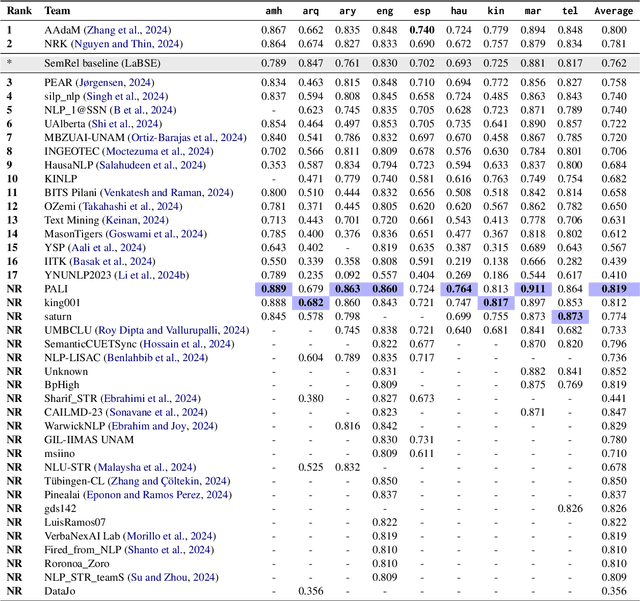
We present the first shared task on Semantic Textual Relatedness (STR). While earlier shared tasks primarily focused on semantic similarity, we instead investigate the broader phenomenon of semantic relatedness across 14 languages: Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by the relatively limited availability of NLP resources. Each instance in the datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. Participating systems were asked to rank sentence pairs by their closeness in meaning (i.e., their degree of semantic relatedness) in the 14 languages in three main tracks: (a) supervised, (b) unsupervised, and (c) crosslingual. The task attracted 163 participants. We received 70 submissions in total (across all tasks) from 51 different teams, and 38 system description papers. We report on the best-performing systems as well as the most common and the most effective approaches for the three different tracks.
The Emotion Dynamics of Literary Novels
Mar 04, 2024



Stories are rich in the emotions they exhibit in their narratives and evoke in the readers. The emotional journeys of the various characters within a story are central to their appeal. Computational analysis of the emotions of novels, however, has rarely examined the variation in the emotional trajectories of the different characters within them, instead considering the entire novel to represent a single story arc. In this work, we use character dialogue to distinguish between the emotion arcs of the narration and the various characters. We analyze the emotion arcs of the various characters in a dataset of English literary novels using the framework of Utterance Emotion Dynamics. Our findings show that the narration and the dialogue largely express disparate emotions through the course of a novel, and that the commonalities or differences in the emotional arcs of stories are more accurately captured by those associated with individual characters.
Emotion Granularity from Text: An Aggregate-Level Indicator of Mental Health
Mar 04, 2024We are united in how emotions are central to shaping our experiences; and yet, individuals differ greatly in how we each identify, categorize, and express emotions. In psychology, variation in the ability of individuals to differentiate between emotion concepts is called emotion granularity (determined through self-reports of one's emotions). High emotion granularity has been linked with better mental and physical health; whereas low emotion granularity has been linked with maladaptive emotion regulation strategies and poor health outcomes. In this work, we propose computational measures of emotion granularity derived from temporally-ordered speaker utterances in social media (in lieu of self-reports that suffer from various biases). We then investigate the effectiveness of such text-derived measures of emotion granularity in functioning as markers of various mental health conditions (MHCs). We establish baseline measures of emotion granularity derived from textual utterances, and show that, at an aggregate level, emotion granularities are significantly lower for people self-reporting as having an MHC than for the control population. This paves the way towards a better understanding of the MHCs, and specifically the role emotions play in our well-being.
SemRel2024: A Collection of Semantic Textual Relatedness Datasets for 14 Languages
Feb 15, 2024



Exploring and quantifying semantic relatedness is central to representing language. It holds significant implications across various NLP tasks, including offering insights into the capabilities and performance of Large Language Models (LLMs). While earlier NLP research primarily focused on semantic similarity, often within the English language context, we instead investigate the broader phenomenon of semantic relatedness. In this paper, we present SemRel, a new semantic relatedness dataset collection annotated by native speakers across 14 languages:Afrikaans, Algerian Arabic, Amharic, English, Hausa, Hindi, Indonesian, Kinyarwanda, Marathi, Moroccan Arabic, Modern Standard Arabic, Punjabi, Spanish, and Telugu. These languages originate from five distinct language families and are predominantly spoken in Africa and Asia -- regions characterised by a relatively limited availability of NLP resources. Each instance in the SemRel datasets is a sentence pair associated with a score that represents the degree of semantic textual relatedness between the two sentences. The scores are obtained using a comparative annotation framework. We describe the data collection and annotation processes, related challenges when building the datasets, and their impact and utility in NLP. We further report experiments for each language and across the different languages.
Improving Automatic Quotation Attribution in Literary Novels
Jul 07, 2023



Current models for quotation attribution in literary novels assume varying levels of available information in their training and test data, which poses a challenge for in-the-wild inference. Here, we approach quotation attribution as a set of four interconnected sub-tasks: character identification, coreference resolution, quotation identification, and speaker attribution. We benchmark state-of-the-art models on each of these sub-tasks independently, using a large dataset of annotated coreferences and quotations in literary novels (the Project Dialogism Novel Corpus). We also train and evaluate models for the speaker attribution task in particular, showing that a simple sequential prediction model achieves accuracy scores on par with state-of-the-art models.
The Project Dialogism Novel Corpus: A Dataset for Quotation Attribution in Literary Texts
Apr 12, 2022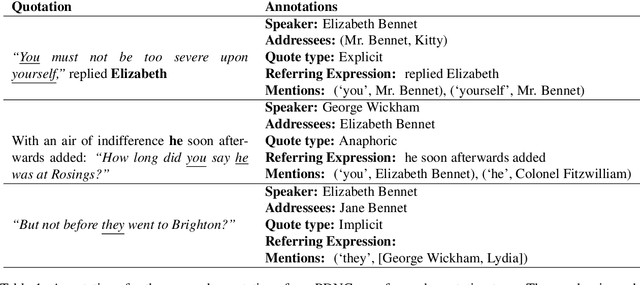
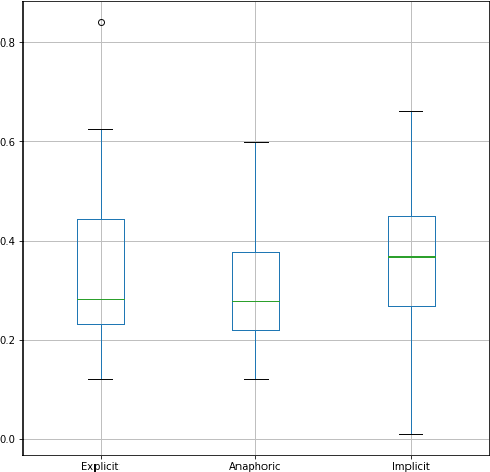
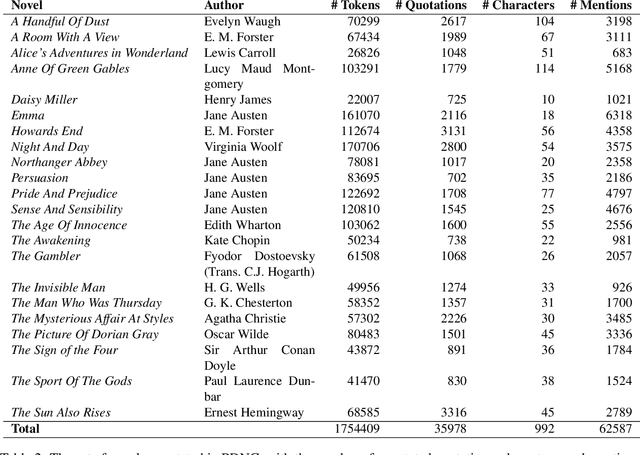

We present the Project Dialogism Novel Corpus, or PDNC, an annotated dataset of quotations for English literary texts. PDNC contains annotations for 35,978 quotations across 22 full-length novels, and is by an order of magnitude the largest corpus of its kind. Each quotation is annotated for the speaker, addressees, type of quotation, referring expression, and character mentions within the quotation text. The annotated attributes allow for a comprehensive evaluation of models of quotation attribution and coreference for literary texts.
Tweet Emotion Dynamics: Emotion Word Usage in Tweets from US and Canada
Apr 11, 2022
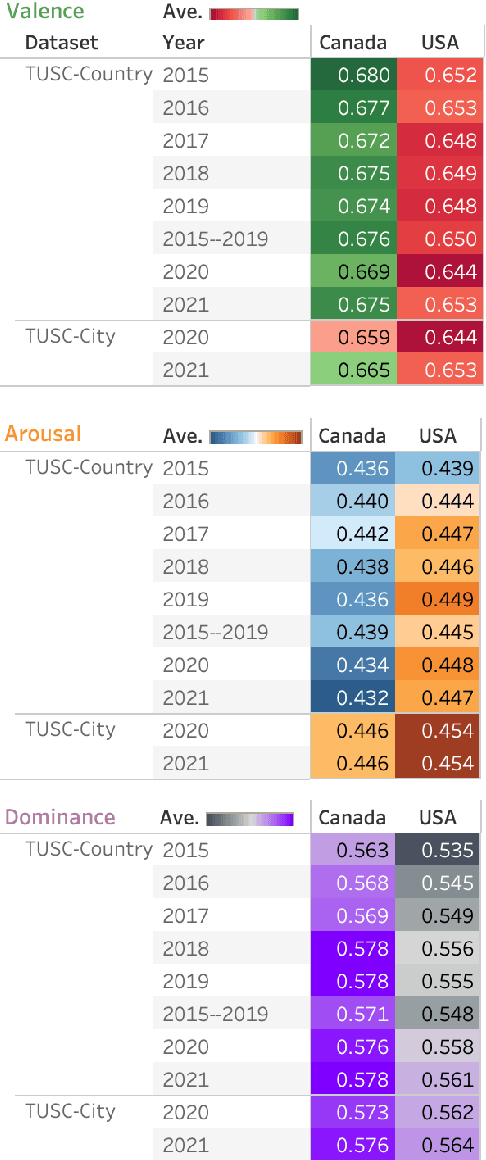
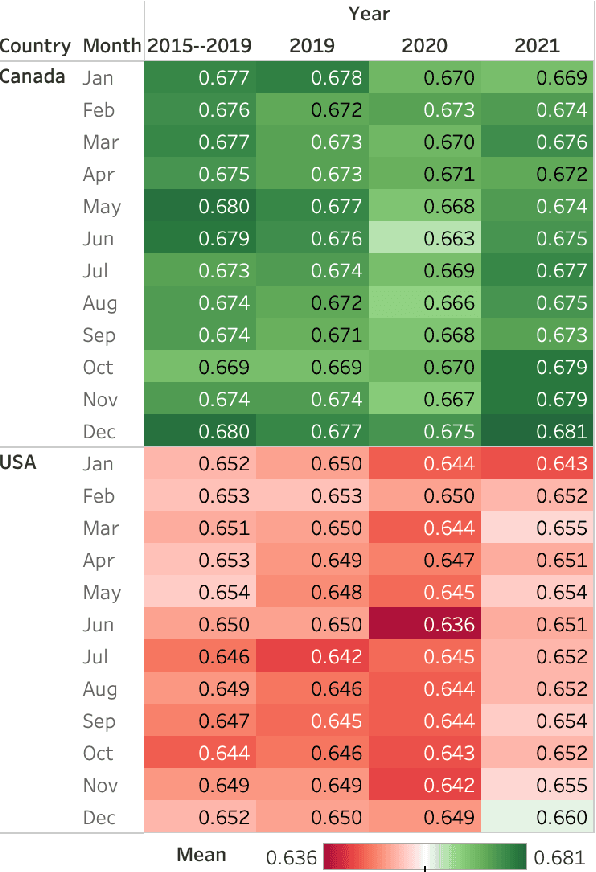

Over the last decade, Twitter has emerged as one of the most influential forums for social, political, and health discourse. In this paper, we introduce a massive dataset of more than 45 million geo-located tweets posted between 2015 and 2021 from US and Canada (TUSC), especially curated for natural language analysis. We also introduce Tweet Emotion Dynamics (TED) -- metrics to capture patterns of emotions associated with tweets over time. We use TED and TUSC to explore the use of emotion-associated words across US and Canada; across 2019 (pre-pandemic), 2020 (the year the pandemic hit), and 2021 (the second year of the pandemic); and across individual tweeters. We show that Canadian tweets tend to have higher valence, lower arousal, and higher dominance than the US tweets. Further, we show that the COVID-19 pandemic had a marked impact on the emotional signature of tweets posted in 2020, when compared to the adjoining years. Finally, we determine metrics of TED for 170,000 tweeters to benchmark characteristics of TED metrics at an aggregate level. TUSC and the metrics for TED will enable a wide variety of research on studying how we use language to express ourselves, persuade, communicate, and influence, with particularly promising applications in public health, affective science, social science, and psychology.