 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShrinking Bigfoot: Reducing wav2vec 2.0 footprint
Apr 01, 2021
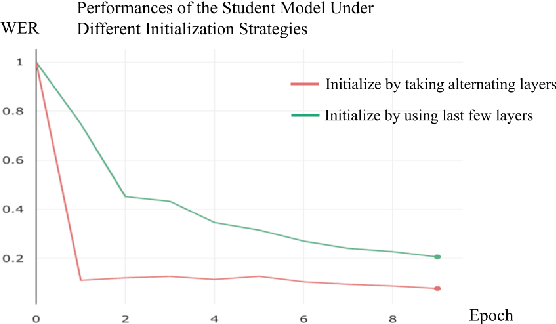
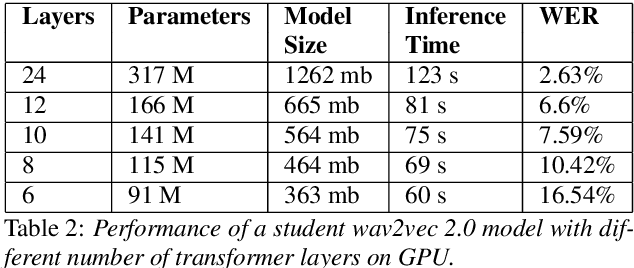
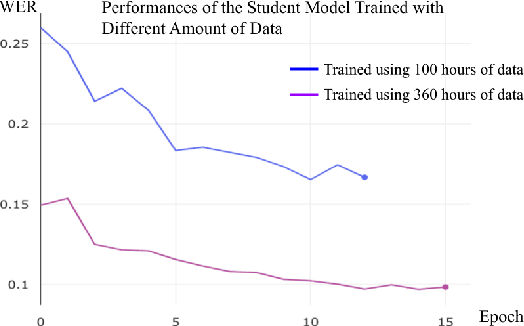
Wav2vec 2.0 is a state-of-the-art speech recognition model which maps speech audio waveforms into latent representations. The largest version of wav2vec 2.0 contains 317 million parameters. Hence, the inference latency of wav2vec 2.0 will be a bottleneck in production, leading to high costs and a significant environmental footprint. To improve wav2vec's applicability to a production setting, we explore multiple model compression methods borrowed from the domain of large language models. Using a teacher-student approach, we distilled the knowledge from the original wav2vec 2.0 model into a student model, which is 2 times faster and 4.8 times smaller than the original model. This increase in performance is accomplished with only a 7% degradation in word error rate (WER). Our quantized model is 3.6 times smaller than the original model, with only a 0.1% degradation in WER. To the best of our knowledge, this is the first work that compresses wav2vec 2.0.
Generative Adversarial Networks for text using word2vec intermediaries
Apr 04, 2019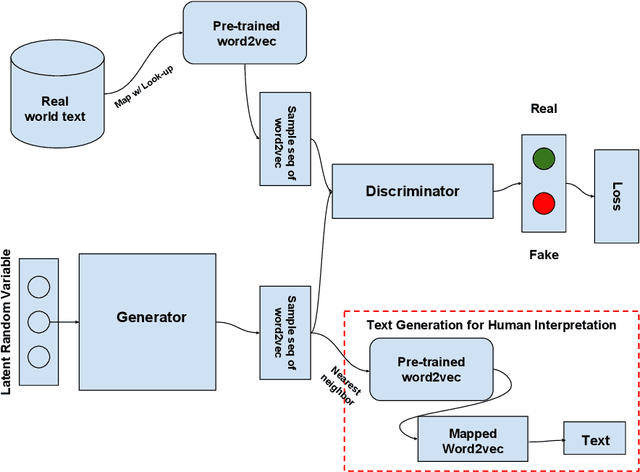
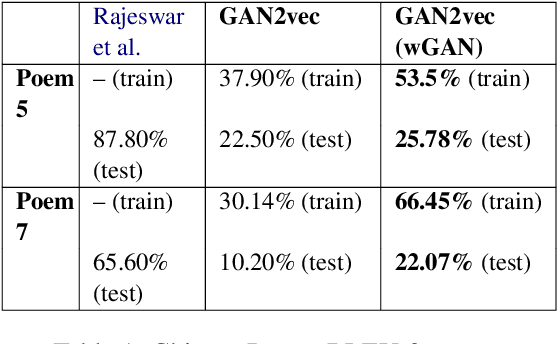

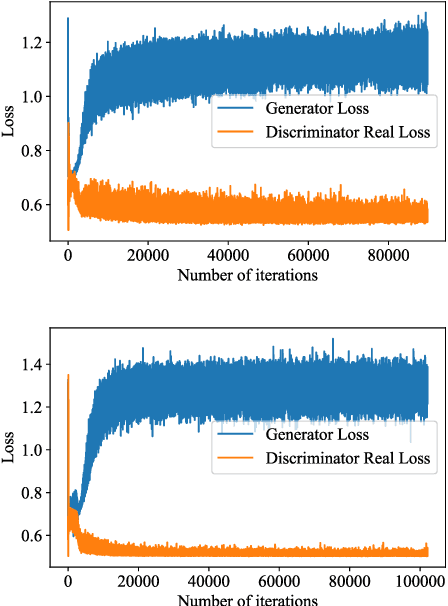
Generative adversarial networks (GANs) have shown considerable success, especially in the realistic generation of images. In this work, we apply similar techniques for the generation of text. We propose a novel approach to handle the discrete nature of text, during training, using word embeddings. Our method is agnostic to vocabulary size and achieves competitive results relative to methods with various discrete gradient estimators.
Augmenting word2vec with latent Dirichlet allocation within a clinical application
Aug 12, 2018



This paper presents three hybrid models that directly combine latent Dirichlet allocation and word embedding for distinguishing between speakers with and without Alzheimer's disease from transcripts of picture descriptions. Two of our models get F-scores over the current state-of-the-art using automatic methods on the DementiaBank dataset.