 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Trustworthiness of Tree Ensemble Explainability Methods
Sep 30, 2021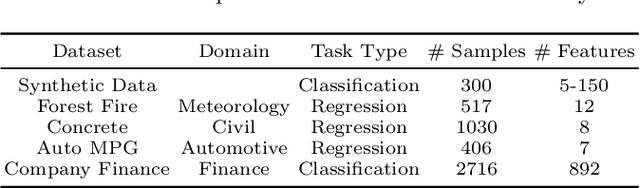
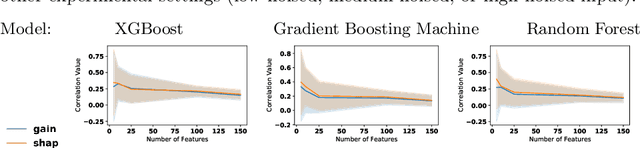
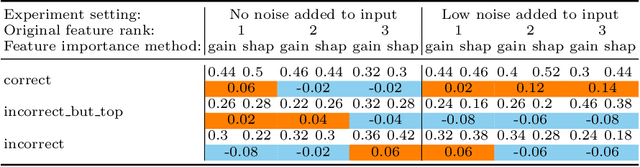

The recent increase in the deployment of machine learning models in critical domains such as healthcare, criminal justice, and finance has highlighted the need for trustworthy methods that can explain these models to stakeholders. Feature importance methods (e.g. gain and SHAP) are among the most popular explainability methods used to address this need. For any explainability technique to be trustworthy and meaningful, it has to provide an explanation that is accurate and stable. Although the stability of local feature importance methods (explaining individual predictions) has been studied before, there is yet a knowledge gap about the stability of global features importance methods (explanations for the whole model). Additionally, there is no study that evaluates and compares the accuracy of global feature importance methods with respect to feature ordering. In this paper, we evaluate the accuracy and stability of global feature importance methods through comprehensive experiments done on simulations as well as four real-world datasets. We focus on tree-based ensemble methods as they are used widely in industry and measure the accuracy and stability of explanations under two scenarios: 1) when inputs are perturbed 2) when models are perturbed. Our findings provide a comparison of these methods under a variety of settings and shed light on the limitations of global feature importance methods by indicating their lack of accuracy with and without noisy inputs, as well as their lack of stability with respect to: 1) increase in input dimension or noise in the data; 2) perturbations in models initialized by different random seeds or hyperparameter settings.
Shrinking Bigfoot: Reducing wav2vec 2.0 footprint
Apr 01, 2021
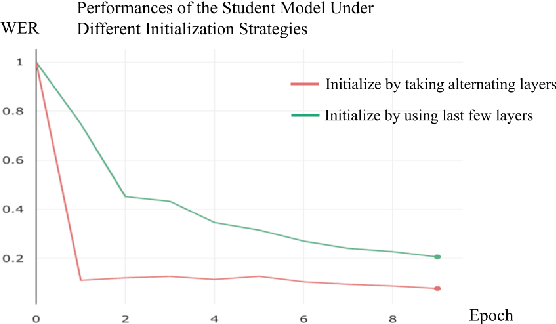
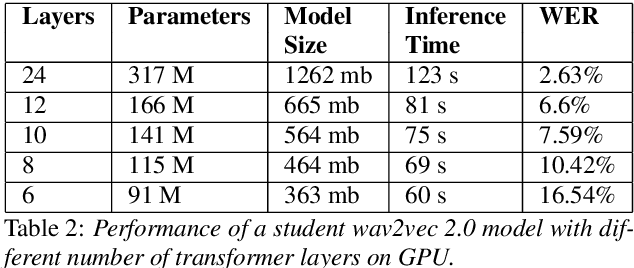
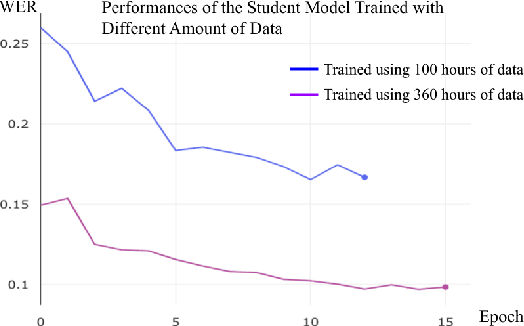
Wav2vec 2.0 is a state-of-the-art speech recognition model which maps speech audio waveforms into latent representations. The largest version of wav2vec 2.0 contains 317 million parameters. Hence, the inference latency of wav2vec 2.0 will be a bottleneck in production, leading to high costs and a significant environmental footprint. To improve wav2vec's applicability to a production setting, we explore multiple model compression methods borrowed from the domain of large language models. Using a teacher-student approach, we distilled the knowledge from the original wav2vec 2.0 model into a student model, which is 2 times faster and 4.8 times smaller than the original model. This increase in performance is accomplished with only a 7% degradation in word error rate (WER). Our quantized model is 3.6 times smaller than the original model, with only a 0.1% degradation in WER. To the best of our knowledge, this is the first work that compresses wav2vec 2.0.
Boosting Model Performance through Differentially Private Model Aggregation
Dec 04, 2018



A key factor in developing high performing machine learning models is the availability of sufficiently large datasets. This work is motivated by applications arising in Software as a Service (SaaS) companies where there exist numerous similar yet disjoint datasets from multiple client companies. To overcome the challenges of insufficient data without explicitly aggregating the clients' datasets due to privacy concerns, one solution is to collect more data for each individual client, another is to privately aggregate information from models trained on each client's data. In this work, two approaches for private model aggregation are proposed that enable the transfer of knowledge from existing models trained on other companies' datasets to a new company with limited labeled data while protecting each client company's underlying individual sensitive information. The two proposed approaches are based on state-of-the-art private learning algorithms: Differentially Private Permutation-based Stochastic Gradient Descent and Approximate Minima Perturbation. We empirically show that by leveraging differentially private techniques, we can enable private model aggregation and augment data utility while providing provable mathematical guarantees on privacy. The proposed methods thus provide significant business value for SaaS companies and their clients, specifically as a solution for the cold-start problem.
A Hybrid Instance-based Transfer Learning Method
Dec 03, 2018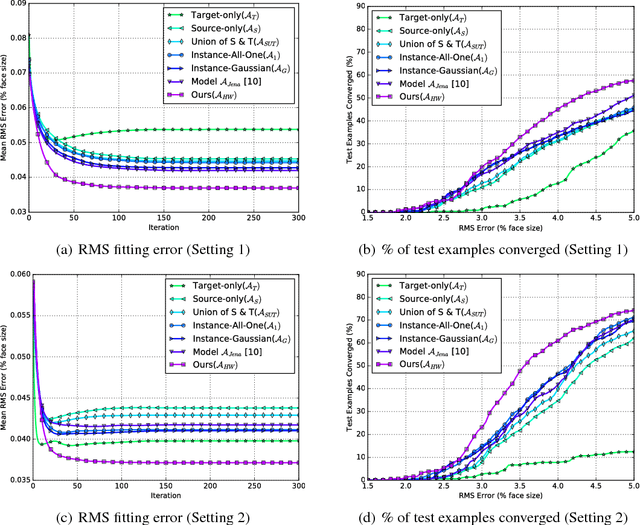
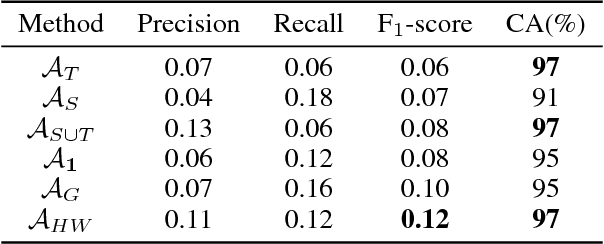
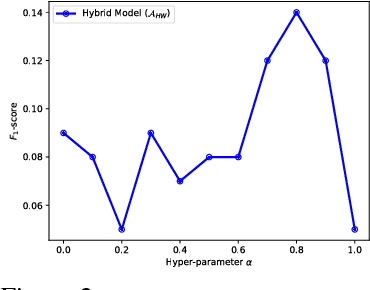

In recent years, supervised machine learning models have demonstrated tremendous success in a variety of application domains. Despite the promising results, these successful models are data hungry and their performance relies heavily on the size of training data. However, in many healthcare applications it is difficult to collect sufficiently large training datasets. Transfer learning can help overcome this issue by transferring the knowledge from readily available datasets (source) to a new dataset (target). In this work, we propose a hybrid instance-based transfer learning method that outperforms a set of baselines including state-of-the-art instance-based transfer learning approaches. Our method uses a probabilistic weighting strategy to fuse information from the source domain to the model learned in the target domain. Our method is generic, applicable to multiple source domains, and robust with respect to negative transfer. We demonstrate the effectiveness of our approach through extensive experiments for two different applications.
Stance and Sentiment in Tweets
May 05, 2016


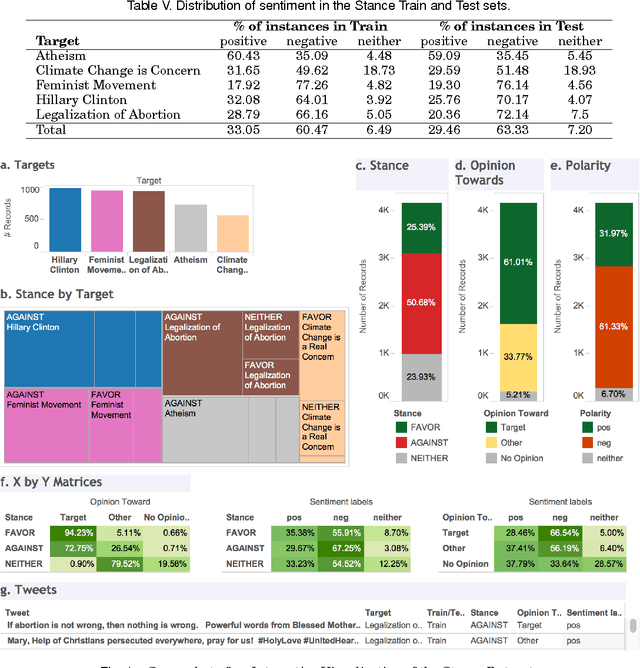
We can often detect from a person's utterances whether he/she is in favor of or against a given target entity -- their stance towards the target. However, a person may express the same stance towards a target by using negative or positive language. Here for the first time we present a dataset of tweet--target pairs annotated for both stance and sentiment. The targets may or may not be referred to in the tweets, and they may or may not be the target of opinion in the tweets. Partitions of this dataset were used as training and test sets in a SemEval-2016 shared task competition. We propose a simple stance detection system that outperforms submissions from all 19 teams that participated in the shared task. Additionally, access to both stance and sentiment annotations allows us to explore several research questions. We show that while knowing the sentiment expressed by a tweet is beneficial for stance classification, it alone is not sufficient. Finally, we use additional unlabeled data through distant supervision techniques and word embeddings to further improve stance classification.
Long Short-Term Memory Over Tree Structures
Mar 16, 2015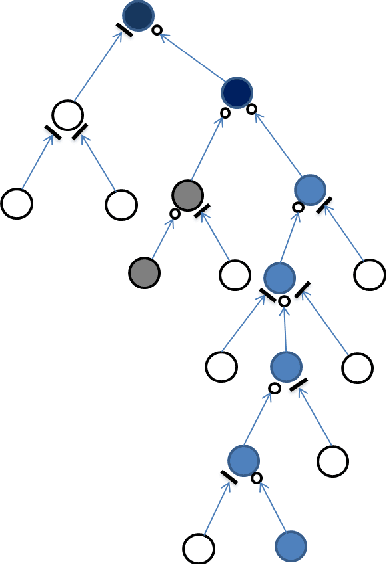



The chain-structured long short-term memory (LSTM) has showed to be effective in a wide range of problems such as speech recognition and machine translation. In this paper, we propose to extend it to tree structures, in which a memory cell can reflect the history memories of multiple child cells or multiple descendant cells in a recursive process. We call the model S-LSTM, which provides a principled way of considering long-distance interaction over hierarchies, e.g., language or image parse structures. We leverage the models for semantic composition to understand the meaning of text, a fundamental problem in natural language understanding, and show that it outperforms a state-of-the-art recursive model by replacing its composition layers with the S-LSTM memory blocks. We also show that utilizing the given structures is helpful in achieving a performance better than that without considering the structures.