 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFUGC: Benchmarking Semi-Supervised Learning Methods for Cervical Segmentation
Jan 22, 2026Accurate segmentation of cervical structures in transvaginal ultrasound (TVS) is critical for assessing the risk of spontaneous preterm birth (PTB), yet the scarcity of labeled data limits the performance of supervised learning approaches. This paper introduces the Fetal Ultrasound Grand Challenge (FUGC), the first benchmark for semi-supervised learning in cervical segmentation, hosted at ISBI 2025. FUGC provides a dataset of 890 TVS images, including 500 training images, 90 validation images, and 300 test images. Methods were evaluated using the Dice Similarity Coefficient (DSC), Hausdorff Distance (HD), and runtime (RT), with a weighted combination of 0.4/0.4/0.2. The challenge attracted 10 teams with 82 participants submitting innovative solutions. The best-performing methods for each individual metric achieved 90.26\% mDSC, 38.88 mHD, and 32.85 ms RT, respectively. FUGC establishes a standardized benchmark for cervical segmentation, demonstrates the efficacy of semi-supervised methods with limited labeled data, and provides a foundation for AI-assisted clinical PTB risk assessment.
Shrinking Bigfoot: Reducing wav2vec 2.0 footprint
Apr 01, 2021
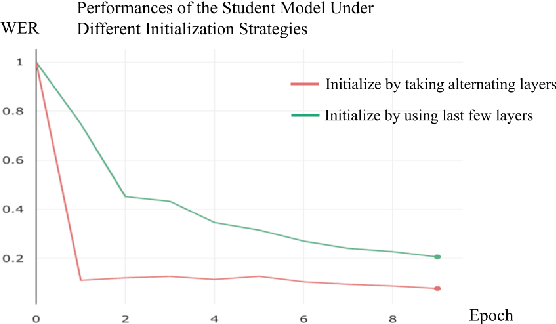
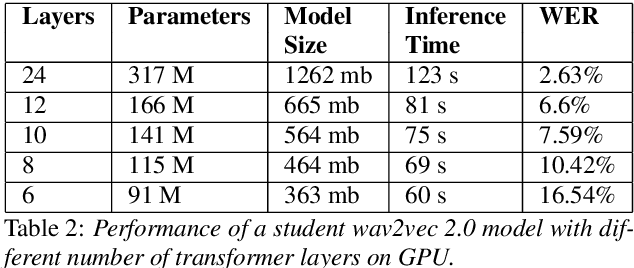
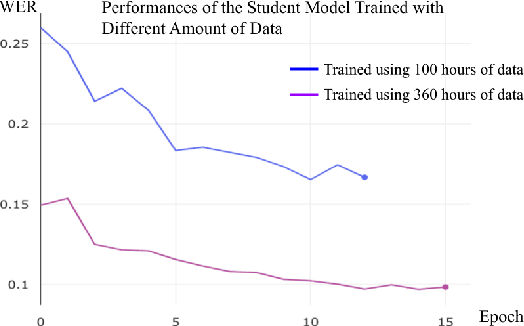
Wav2vec 2.0 is a state-of-the-art speech recognition model which maps speech audio waveforms into latent representations. The largest version of wav2vec 2.0 contains 317 million parameters. Hence, the inference latency of wav2vec 2.0 will be a bottleneck in production, leading to high costs and a significant environmental footprint. To improve wav2vec's applicability to a production setting, we explore multiple model compression methods borrowed from the domain of large language models. Using a teacher-student approach, we distilled the knowledge from the original wav2vec 2.0 model into a student model, which is 2 times faster and 4.8 times smaller than the original model. This increase in performance is accomplished with only a 7% degradation in word error rate (WER). Our quantized model is 3.6 times smaller than the original model, with only a 0.1% degradation in WER. To the best of our knowledge, this is the first work that compresses wav2vec 2.0.
SVRG for Policy Evaluation with Fewer Gradient Evaluations
Jun 09, 2019
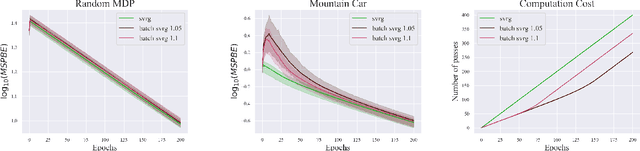
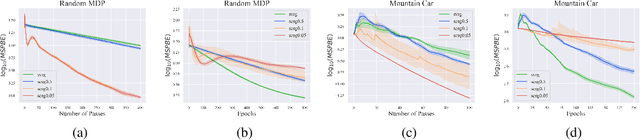
Stochastic variance-reduced gradient (SVRG) is an optimization method originally designed for tackling machine learning problems with a finite sum structure. SVRG was later shown to work for policy evaluation, a problem in reinforcement learning in which one aims to estimate the value function of a given policy. SVRG makes use of gradient estimates at two scales. At the slower scale, SVRG computes a full gradient over the whole dataset, which could lead to prohibitive computation costs. In this work, we show that two variants of SVRG for policy evaluation could significantly diminish the number of gradient calculations while preserving a linear convergence speed. More importantly, our theoretical result implies that one does not need to use the entire dataset in every epoch of SVRG when it is applied to policy evaluation with linear function approximation. Our experiments demonstrate large computational savings provided by the proposed methods.
Navigation Objects Extraction for Better Content Structure Understanding
Aug 26, 2017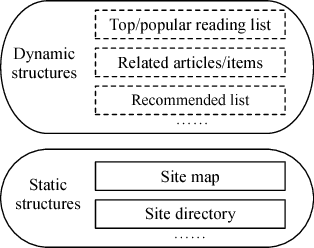
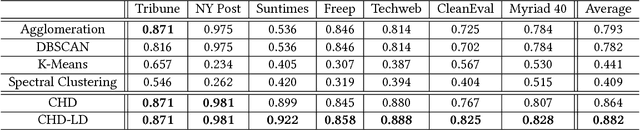
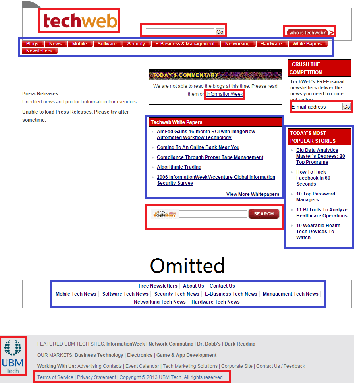
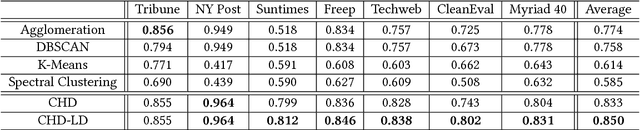
Existing works for extracting navigation objects from webpages focus on navigation menus, so as to reveal the information architecture of the site. However, web 2.0 sites such as social networks, e-commerce portals etc. are making the understanding of the content structure in a web site increasingly difficult. Dynamic and personalized elements such as top stories, recommended list in a webpage are vital to the understanding of the dynamic nature of web 2.0 sites. To better understand the content structure in web 2.0 sites, in this paper we propose a new extraction method for navigation objects in a webpage. Our method will extract not only the static navigation menus, but also the dynamic and personalized page-specific navigation lists. Since the navigation objects in a webpage naturally come in blocks, we first cluster hyperlinks into different blocks by exploiting spatial locations of hyperlinks, the hierarchical structure of the DOM-tree and the hyperlink density. Then we identify navigation objects from those blocks using the SVM classifier with novel features such as anchor text lengths etc. Experiments on real-world data sets with webpages from various domains and styles verified the effectiveness of our method.
Comparing Aggregators for Relational Probabilistic Models
Jul 25, 2017

Relational probabilistic models have the challenge of aggregation, where one variable depends on a population of other variables. Consider the problem of predicting gender from movie ratings; this is challenging because the number of movies per user and users per movie can vary greatly. Surprisingly, aggregation is not well understood. In this paper, we show that existing relational models (implicitly or explicitly) either use simple numerical aggregators that lose great amounts of information, or correspond to naive Bayes, logistic regression, or noisy-OR that suffer from overconfidence. We propose new simple aggregators and simple modifications of existing models that empirically outperform the existing ones. The intuition we provide on different (existing or new) models and their shortcomings plus our empirical findings promise to form the foundation for future representations.