 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Neural Network Hyperparameter Optimization for Extrapolation: Lessons Learned from Visible and Near-Infrared Spectroscopy of Mango Fruit
Oct 03, 2022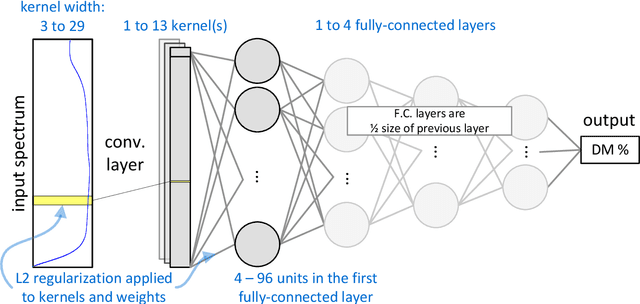
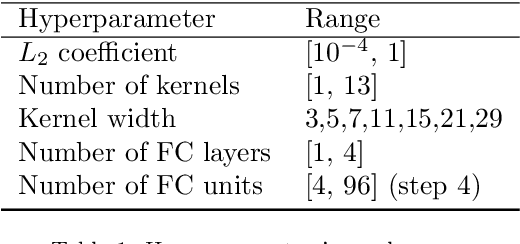

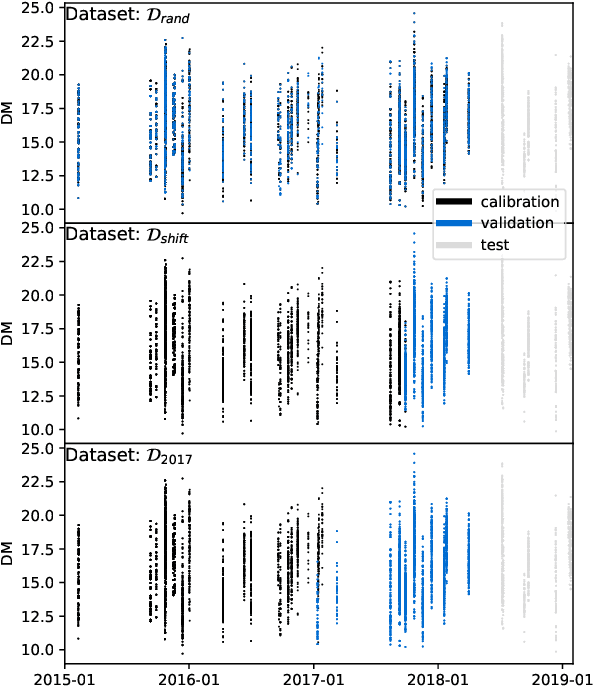
Neural networks are configured by choosing an architecture and hyperparameter values; doing so often involves expert intuition and hand-tuning to find a configuration that extrapolates well without overfitting. This paper considers automatic methods for configuring a neural network that extrapolates in time for the domain of visible and near-infrared (VNIR) spectroscopy. In particular, we study the effect of (a) selecting samples for validating configurations and (b) using ensembles. Most of the time, models are built of the past to predict the future. To encourage the neural network model to extrapolate, we consider validating model configurations on samples that are shifted in time similar to the test set. We experiment with three validation set choices: (1) a random sample of 1/3 of non-test data (the technique used in previous work), (2) using the latest 1/3 (sorted by time), and (3) using a semantically meaningful subset of the data. Hyperparameter optimization relies on the validation set to estimate test-set error, but neural network variance obfuscates the true error value. Ensemble averaging - computing the average across many neural networks - can reduce the variance of prediction errors. To test these methods, we do a comprehensive study of a held-out 2018 harvest season of mango fruit given VNIR spectra from 3 prior years. We find that ensembling improves the state-of-the-art model's variance and accuracy. Furthermore, hyperparameter optimization experiments - with and without ensemble averaging and with each validation set choice - show that when ensembling is combined with using the latest 1/3 of samples as the validation set, a neural network configuration is found automatically that is on par with the state-of-the-art.
Binarised Regression with Instance-Varying Costs: Evaluation using Impact Curves
Aug 14, 2020
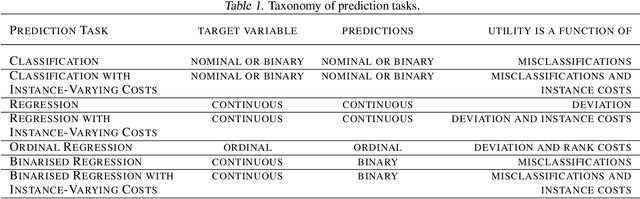
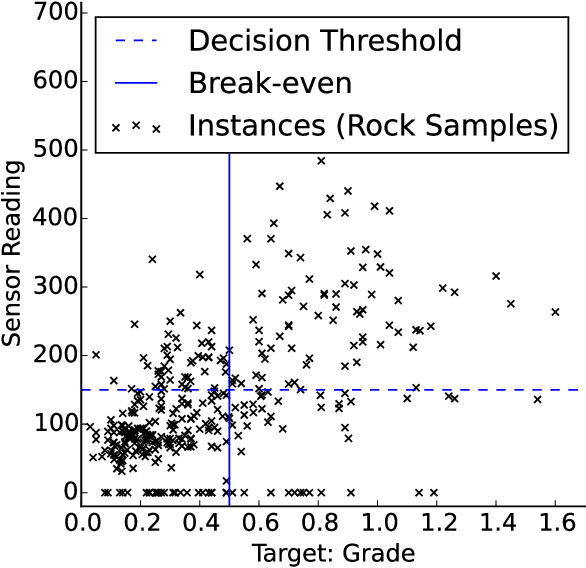
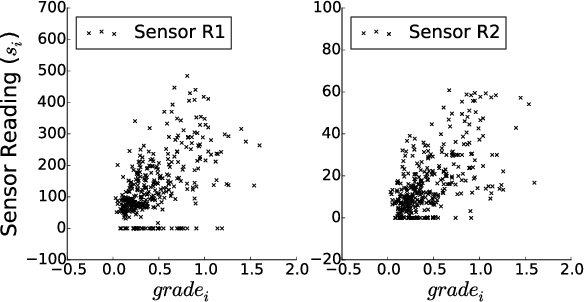
Many evaluation methods exist, each for a particular prediction task, and there are a number of prediction tasks commonly performed including classification and regression. In binarised regression, binary decisions are generated from a learned regression model (or real-valued dependent variable), which is useful when the division between instances that should be predicted positive or negative depends on the utility. For example, in mining, the boundary between a valuable rock and a waste rock depends on the market price of various metals, which varies with time. This paper proposes impact curves to evaluate binarised regression with instance-varying costs, where some instances are much worse to be classified as positive (or negative) than other instances; e.g., it is much worse to throw away a high-grade gold rock than a medium-grade copper-ore rock, even if the mine wishes to keep both because both are profitable. We show how to construct an impact curve for a variety of domains, including examples from healthcare, mining, and entertainment. Impact curves optimize binary decisions across all utilities of the chosen utility function, identify the conditions where one model may be favoured over another, and quantitatively assess improvement between competing models.
Comparing Aggregators for Relational Probabilistic Models
Jul 25, 2017

Relational probabilistic models have the challenge of aggregation, where one variable depends on a population of other variables. Consider the problem of predicting gender from movie ratings; this is challenging because the number of movies per user and users per movie can vary greatly. Surprisingly, aggregation is not well understood. In this paper, we show that existing relational models (implicitly or explicitly) either use simple numerical aggregators that lose great amounts of information, or correspond to naive Bayes, logistic regression, or noisy-OR that suffer from overconfidence. We propose new simple aggregators and simple modifications of existing models that empirically outperform the existing ones. The intuition we provide on different (existing or new) models and their shortcomings plus our empirical findings promise to form the foundation for future representations.