 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Isn't Relational Learning Taking Over the World?
Jul 17, 2025AI seems to be taking over the world with systems that model pixels, words, and phonemes. The world is arguably made up, not of pixels, words, and phonemes but of entities (objects, things, including events) with properties and relations among them. Surely we should model these, not the perception or description of them. You might suspect that concentrating on modeling words and pixels is because all of the (valuable) data in the world is in terms of text and images. If you look into almost any company you will find their most valuable data is in spreadsheets, databases and other relational formats. These are not the form that are studied in introductory machine learning, but are full of product numbers, student numbers, transaction numbers and other identifiers that can't be interpreted naively as numbers. The field that studies this sort of data has various names including relational learning, statistical relational AI, and many others. This paper explains why relational learning is not taking over the world -- except in a few cases with restricted relations -- and what needs to be done to bring it to it's rightful prominence.
Automatic Neural Network Hyperparameter Optimization for Extrapolation: Lessons Learned from Visible and Near-Infrared Spectroscopy of Mango Fruit
Oct 03, 2022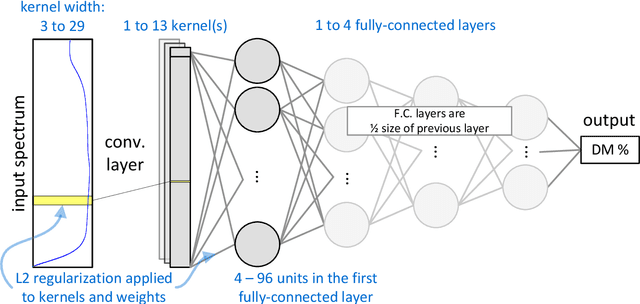
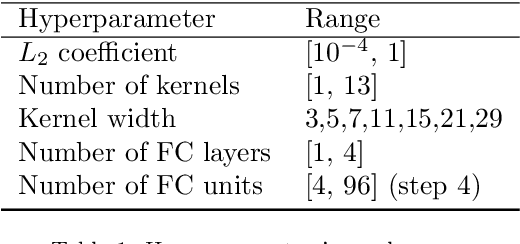

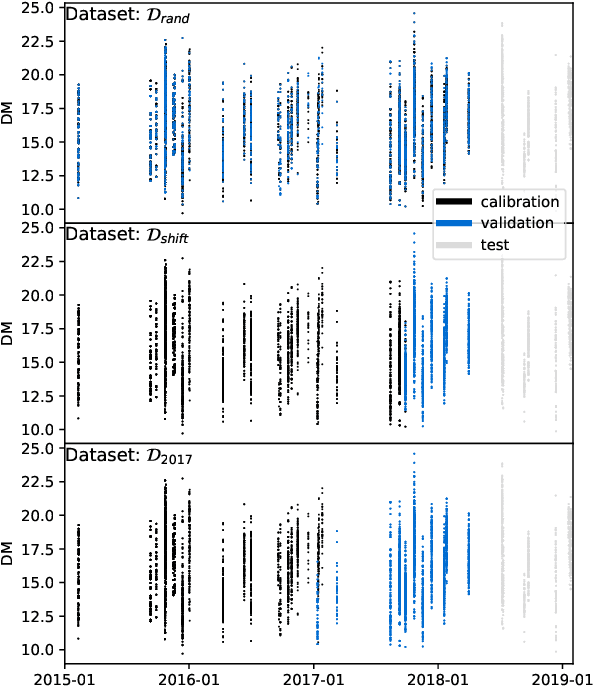
Neural networks are configured by choosing an architecture and hyperparameter values; doing so often involves expert intuition and hand-tuning to find a configuration that extrapolates well without overfitting. This paper considers automatic methods for configuring a neural network that extrapolates in time for the domain of visible and near-infrared (VNIR) spectroscopy. In particular, we study the effect of (a) selecting samples for validating configurations and (b) using ensembles. Most of the time, models are built of the past to predict the future. To encourage the neural network model to extrapolate, we consider validating model configurations on samples that are shifted in time similar to the test set. We experiment with three validation set choices: (1) a random sample of 1/3 of non-test data (the technique used in previous work), (2) using the latest 1/3 (sorted by time), and (3) using a semantically meaningful subset of the data. Hyperparameter optimization relies on the validation set to estimate test-set error, but neural network variance obfuscates the true error value. Ensemble averaging - computing the average across many neural networks - can reduce the variance of prediction errors. To test these methods, we do a comprehensive study of a held-out 2018 harvest season of mango fruit given VNIR spectra from 3 prior years. We find that ensembling improves the state-of-the-art model's variance and accuracy. Furthermore, hyperparameter optimization experiments - with and without ensemble averaging and with each validation set choice - show that when ensembling is combined with using the latest 1/3 of samples as the validation set, a neural network configuration is found automatically that is on par with the state-of-the-art.
Knowledge Hypergraph Embedding Meets Relational Algebra
Feb 18, 2021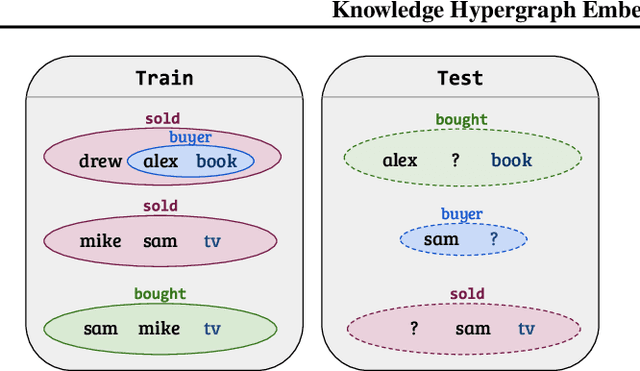
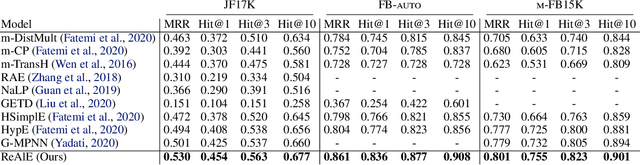
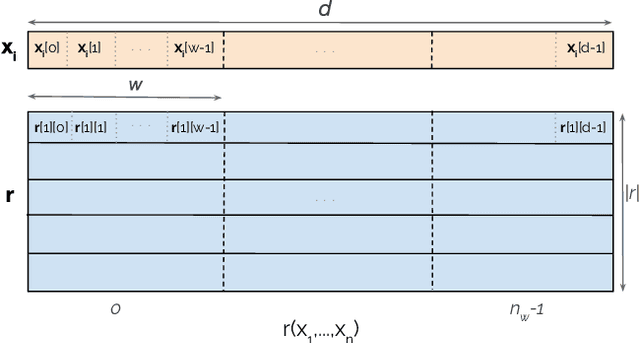

Embedding-based methods for reasoning in knowledge hypergraphs learn a representation for each entity and relation. Current methods do not capture the procedural rules underlying the relations in the graph. We propose a simple embedding-based model called ReAlE that performs link prediction in knowledge hypergraphs (generalized knowledge graphs) and can represent high-level abstractions in terms of relational algebra operations. We show theoretically that ReAlE is fully expressive and provide proofs and empirical evidence that it can represent a large subset of the primitive relational algebra operations, namely renaming, projection, set union, selection, and set difference. We also verify experimentally that ReAlE outperforms state-of-the-art models in knowledge hypergraph completion, and in representing each of these primitive relational algebra operations. For the latter experiment, we generate a synthetic knowledge hypergraph, for which we design an algorithm based on the Erdos-R'enyi model for generating random graphs.
Binarised Regression with Instance-Varying Costs: Evaluation using Impact Curves
Aug 14, 2020
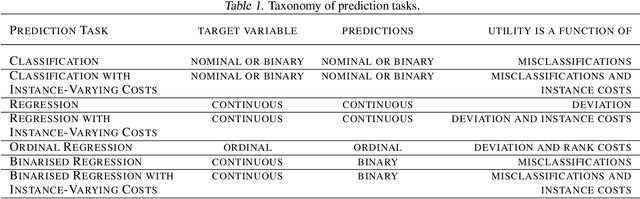
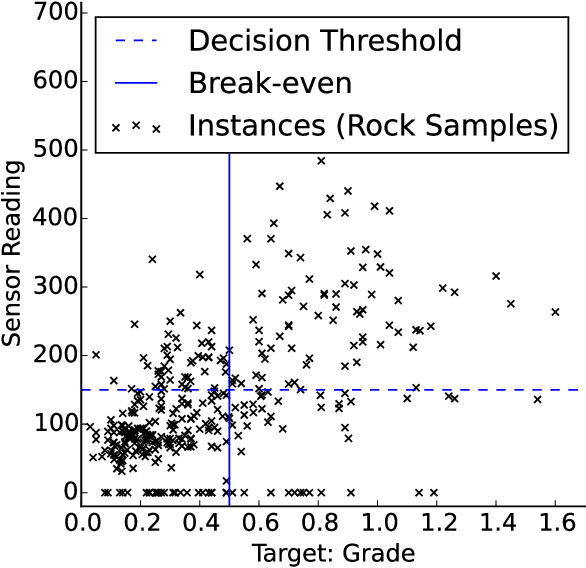
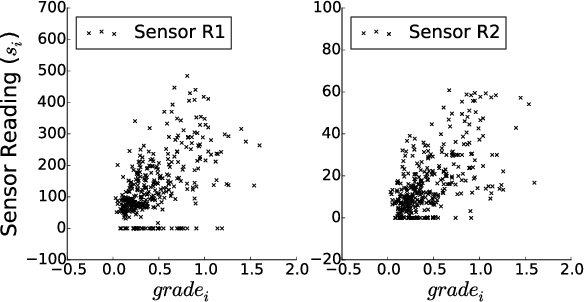
Many evaluation methods exist, each for a particular prediction task, and there are a number of prediction tasks commonly performed including classification and regression. In binarised regression, binary decisions are generated from a learned regression model (or real-valued dependent variable), which is useful when the division between instances that should be predicted positive or negative depends on the utility. For example, in mining, the boundary between a valuable rock and a waste rock depends on the market price of various metals, which varies with time. This paper proposes impact curves to evaluate binarised regression with instance-varying costs, where some instances are much worse to be classified as positive (or negative) than other instances; e.g., it is much worse to throw away a high-grade gold rock than a medium-grade copper-ore rock, even if the mine wishes to keep both because both are profitable. We show how to construct an impact curve for a variety of domains, including examples from healthcare, mining, and entertainment. Impact curves optimize binary decisions across all utilities of the chosen utility function, identify the conditions where one model may be favoured over another, and quantitatively assess improvement between competing models.
A Probabilistic Approach for Predicting Landslides by Learning a Self-Aligned Deep Convolutional Model
Nov 12, 2019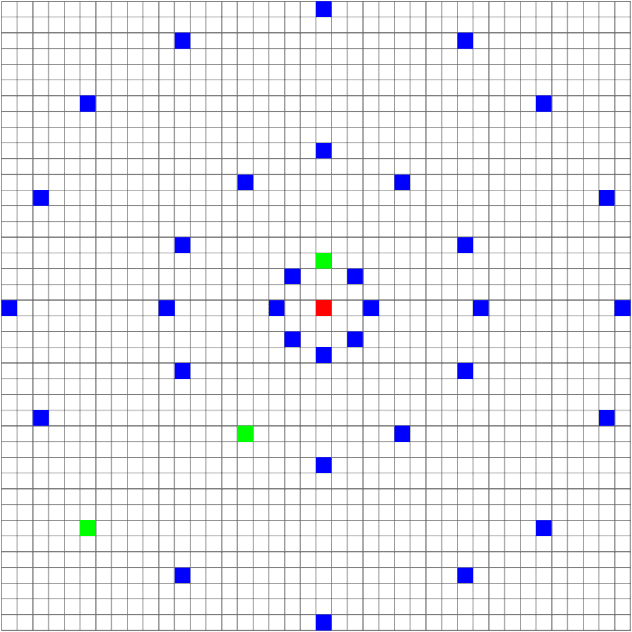
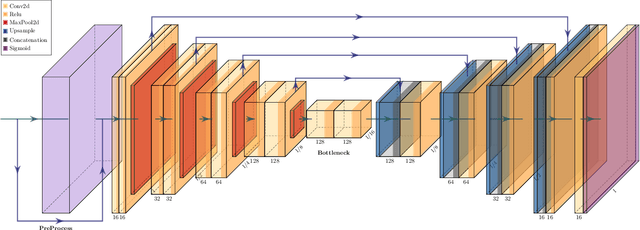
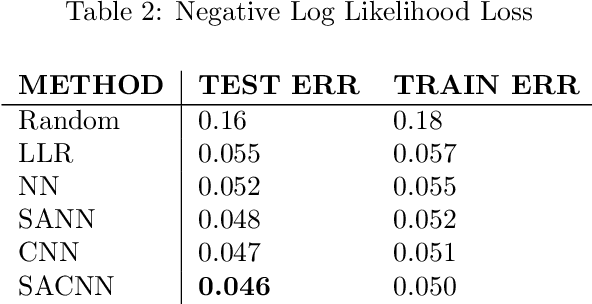
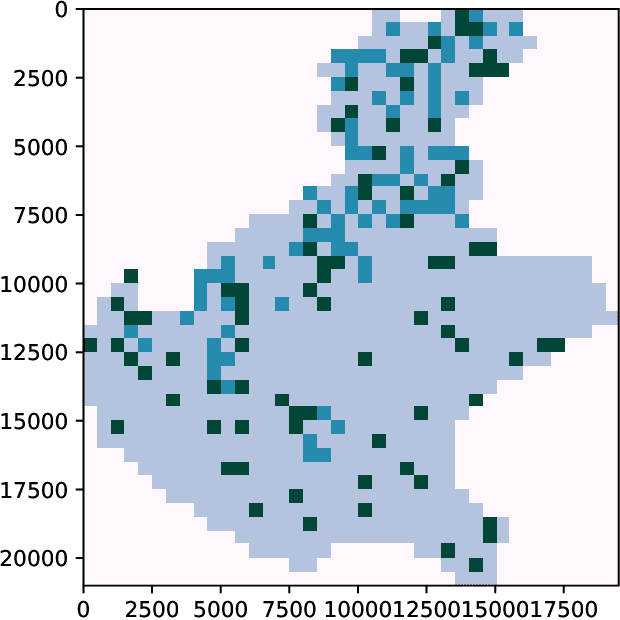
Landslides are movement of soil and rock under the influence of gravity. They are common phenomena that cause significant human and economic losses every year. To reduce the impact of landslides, experts have developed tools to identify areas that are more likely to generate landslides. We propose a novel statistical approach for predicting landslides using deep convolutional networks. Using a standardized dataset of georeferenced images consisting of slope, elevation, land cover, lithology, rock age, and rock family as inputs, we deliver a landslide susceptibility map as output. We call our model a Self-Aligned Convolutional Neural Network, SACNN, as it follows the ground surface at multiple scales to predict possible landslide occurrence for a single point. To validate our method, we compare it to several baselines, including linear regression, a neural network, and a convolutional network, using log-likelihood error and Receiver Operating Characteristic curves on the test set. We show that our model performs better than the other proposed baselines, suggesting that such deep convolutional models are effective in heterogenous datasets for improving landslide susceptibility maps, which has the potential to reduce the human and economic cost of these events.
Knowledge Hypergraphs: Extending Knowledge Graphs Beyond Binary Relations
Jun 01, 2019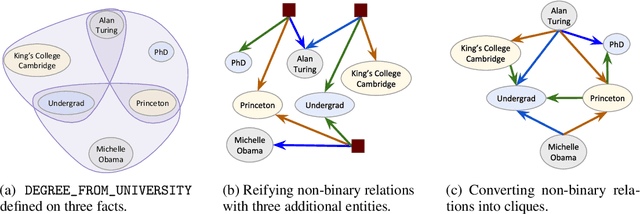
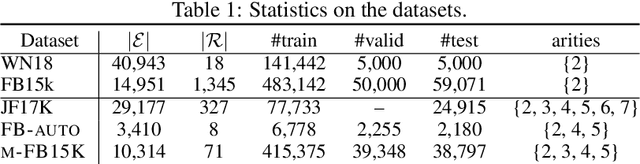
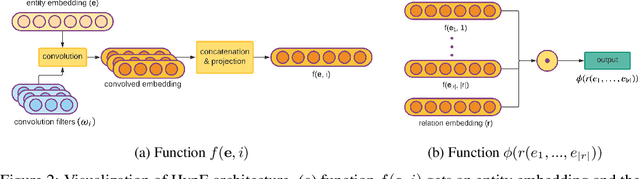
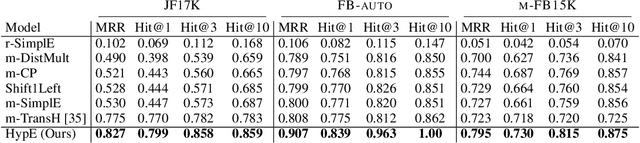
Knowledge graphs store facts using relations between pairs of entities. In this work, we address the question of link prediction in knowledge bases where each relation is defined on any number of entities. We represent facts in a knowledge hypergraph: a knowledge graph where relations are defined on two or more entities. While there exist techniques (such as reification) that convert the non-binary relations of a knowledge hypergraph into binary ones, current embedding-based methods for knowledge graph completion do not work well out of the box for knowledge graphs obtained through these techniques. Thus we introduce HypE, a convolution-based embedding method for knowledge hypergraph completion. We also develop public benchmarks and baselines for our task and show experimentally that HypE is more effective than proposed baselines and existing methods.
Improved Knowledge Graph Embedding using Background Taxonomic Information
Dec 07, 2018
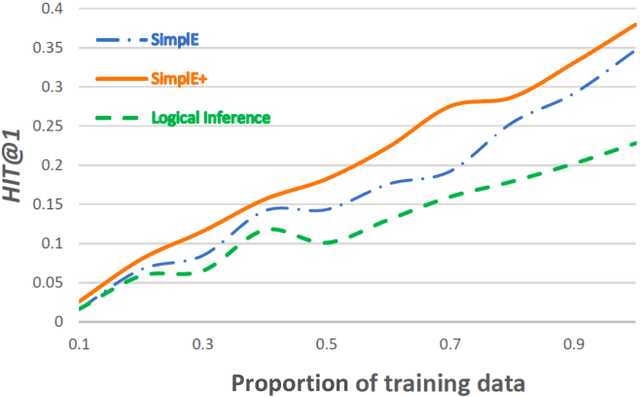

Knowledge graphs are used to represent relational information in terms of triples. To enable learning about domains, embedding models, such as tensor factorization models, can be used to make predictions of new triples. Often there is background taxonomic information (in terms of subclasses and subproperties) that should also be taken into account. We show that existing fully expressive (a.k.a. universal) models cannot provably respect subclass and subproperty information. We show that minimal modifications to an existing knowledge graph completion method enables injection of taxonomic information. Moreover, we prove that our model is fully expressive, assuming a lower-bound on the size of the embeddings. Experimental results on public knowledge graphs show that despite its simplicity our approach is surprisingly effective.
SimplE Embedding for Link Prediction in Knowledge Graphs
Oct 26, 2018
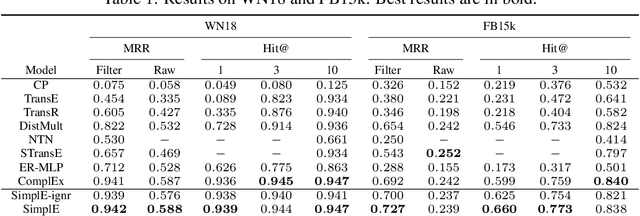

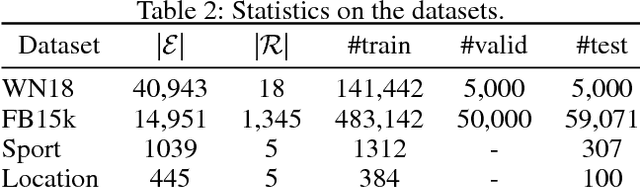
Knowledge graphs contain knowledge about the world and provide a structured representation of this knowledge. Current knowledge graphs contain only a small subset of what is true in the world. Link prediction approaches aim at predicting new links for a knowledge graph given the existing links among the entities. Tensor factorization approaches have proved promising for such link prediction problems. Proposed in 1927, Canonical Polyadic (CP) decomposition is among the first tensor factorization approaches. CP generally performs poorly for link prediction as it learns two independent embedding vectors for each entity, whereas they are really tied. We present a simple enhancement of CP (which we call SimplE) to allow the two embeddings of each entity to be learned dependently. The complexity of SimplE grows linearly with the size of embeddings. The embeddings learned through SimplE are interpretable, and certain types of background knowledge can be incorporated into these embeddings through weight tying. We prove SimplE is fully expressive and derive a bound on the size of its embeddings for full expressivity. We show empirically that, despite its simplicity, SimplE outperforms several state-of-the-art tensor factorization techniques. SimplE's code is available on GitHub at https://github.com/Mehran-k/SimplE.
Structure Learning for Relational Logistic Regression: An Ensemble Approach
Aug 06, 2018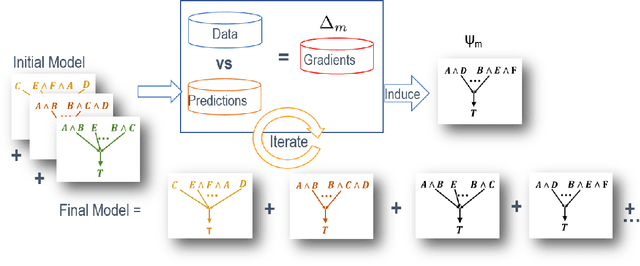
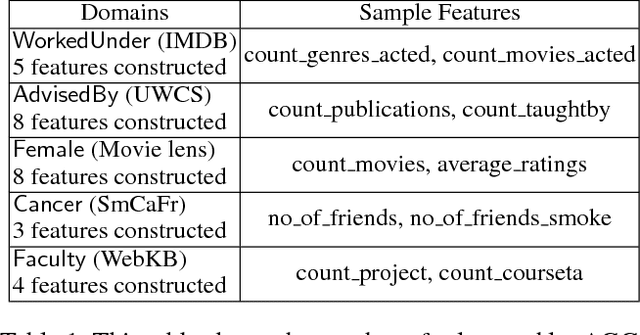
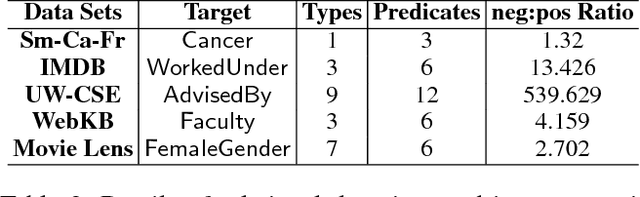
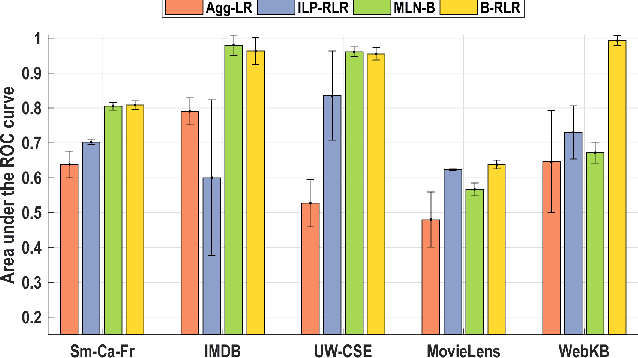
We consider the problem of learning Relational Logistic Regression (RLR). Unlike standard logistic regression, the features of RLRs are first-order formulae with associated weight vectors instead of scalar weights. We turn the problem of learning RLR to learning these vector-weighted formulae and develop a learning algorithm based on the recently successful functional-gradient boosting methods for probabilistic logic models. We derive the functional gradients and show how weights can be learned simultaneously in an efficient manner. Our empirical evaluation on standard and novel data sets demonstrates the superiority of our approach over other methods for learning RLR.
Record Linkage to Match Customer Names: A Probabilistic Approach
Jun 26, 2018


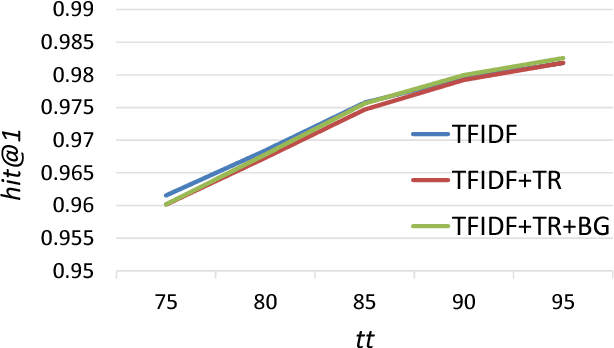
Consider the following problem: given a database of records indexed by names (e.g., name of companies, restaurants, businesses, or universities) and a new name, determine whether the new name is in the database, and if so, which record it refers to. This problem is an instance of record linkage problem and is a challenging problem because people do not consistently use the official name, but use abbreviations, synonyms, different order of terms, different spelling of terms, short form of terms, and the name can contain typos or spacing issues. We provide a probabilistic model using relational logistic regression to find the probability of each record in the database being the desired record for a given query and find the best record(s) with respect to the probabilities. Building on term-matching and translational approaches for search, our model addresses many of the aforementioned challenges and provides good results when existing baselines fail. Using the probabilities outputted by the model, we can automate the search process for a portion of queries whose desired documents get a probability higher than a trust threshold. We evaluate our model on a large real-world dataset from a telecommunications company and compare it to several state-of-the-art baselines. The obtained results show that our model is a promising probabilistic model for record linkage for names. We also test if the knowledge learned by our model on one domain can be effectively transferred to a new domain. For this purpose, we test our model on an unseen test set from the business names of the secondString dataset. Promising results show that our model can be effectively applied to unseen datasets. Finally, we study the sensitivity of our model to the statistics of datasets.