 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecord Linkage to Match Customer Names: A Probabilistic Approach
Paper and Code
Jun 26, 2018


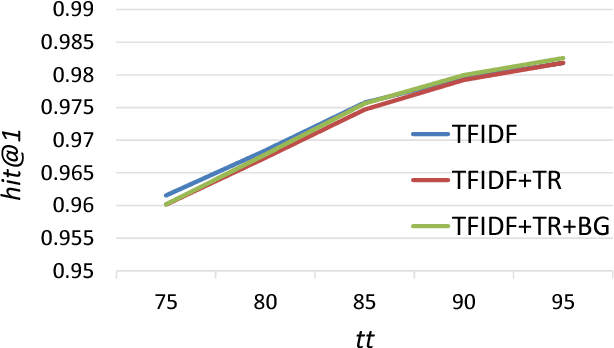
Consider the following problem: given a database of records indexed by names (e.g., name of companies, restaurants, businesses, or universities) and a new name, determine whether the new name is in the database, and if so, which record it refers to. This problem is an instance of record linkage problem and is a challenging problem because people do not consistently use the official name, but use abbreviations, synonyms, different order of terms, different spelling of terms, short form of terms, and the name can contain typos or spacing issues. We provide a probabilistic model using relational logistic regression to find the probability of each record in the database being the desired record for a given query and find the best record(s) with respect to the probabilities. Building on term-matching and translational approaches for search, our model addresses many of the aforementioned challenges and provides good results when existing baselines fail. Using the probabilities outputted by the model, we can automate the search process for a portion of queries whose desired documents get a probability higher than a trust threshold. We evaluate our model on a large real-world dataset from a telecommunications company and compare it to several state-of-the-art baselines. The obtained results show that our model is a promising probabilistic model for record linkage for names. We also test if the knowledge learned by our model on one domain can be effectively transferred to a new domain. For this purpose, we test our model on an unseen test set from the business names of the secondString dataset. Promising results show that our model can be effectively applied to unseen datasets. Finally, we study the sensitivity of our model to the statistics of datasets.