 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Credibility Propagation for Reliable Semi-Supervised Learning
Nov 17, 2022Inferencing unlabeled data from labeled data is an error-prone process. Conventional neural network training is highly sensitive to supervision errors. These two realities make semi-supervised learning (SSL) troublesome. Often, SSL approaches fail to outperform their fully supervised baseline. Proposed is a novel framework for deep SSL, specifically pseudo-labeling, called contrastive credibility propagation (CCP). Through an iterative process of generating and refining soft pseudo-labels, CCP unifies a novel contrastive approach to generating pseudo-labels and a powerful technique to overcome instance-based label noise. The result is a semi-supervised classification framework explicitly designed to overcome inevitable pseudo-label errors in an attempt to reliably boost performance over a supervised baseline. Our empirical evaluation across five benchmark classification datasets suggests one must choose between reliability or effectiveness with prior approaches while CCP delivers both. We also demonstrate an unsupervised signal to subsample pseudo-labels to eliminate errors between iterations of CCP and after its conclusion.
Real-time Drift Detection on Time-series Data
Oct 12, 2021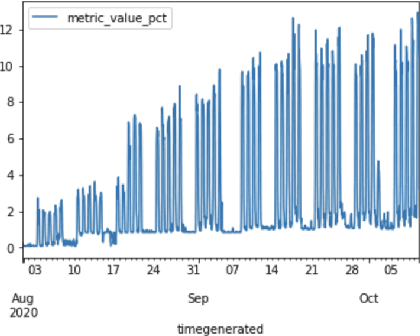
Practical machine learning applications involving time series data, such as firewall log analysis to proactively detect anomalous behavior, are concerned with real time analysis of streaming data. Consequently, we need to update the ML models as the statistical characteristics of such data may shift frequently with time. One alternative explored in the literature is to retrain models with updated data whenever the models accuracy is observed to degrade. However, these methods rely on near real time availability of ground truth, which is rarely fulfilled. Further, in applications with seasonal data, temporal concept drift is confounded by seasonal variation. In this work, we propose an approach called Unsupervised Temporal Drift Detector or UTDD to flexibly account for seasonal variation, efficiently detect temporal concept drift in time series data in the absence of ground truth, and subsequently adapt our ML models to concept drift for better generalization.
Time Series Anomaly Detection with label-free Model Selection
Jun 11, 2021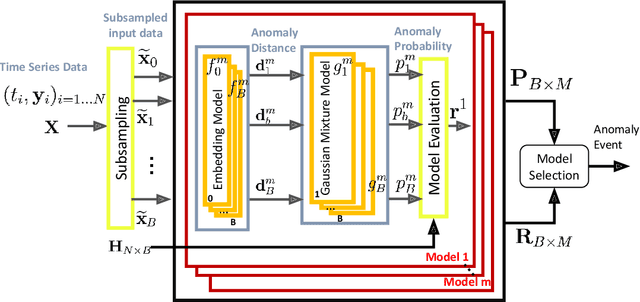

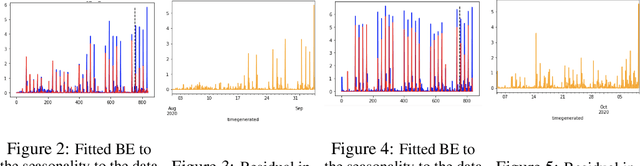
Anomaly detection for time-series data becomes an essential task for many data-driven applications fueled with an abundance of data and out-of-the-box machine-learning algorithms. In many real-world settings, developing a reliable anomaly model is highly challenging due to insufficient anomaly labels and the prohibitively expensive cost of obtaining anomaly examples. It imposes a significant bottleneck to evaluate model quality for model selection and parameter tuning reliably. As a result, many existing anomaly detection algorithms fail to show their promised performance after deployment. In this paper, we propose LaF-AD, a novel anomaly detection algorithm with label-free model selection for unlabeled times-series data. Our proposed algorithm performs a fully unsupervised ensemble learning across a large number of candidate parametric models. We develop a model variance metric that quantifies the sensitivity of anomaly probability with a bootstrapping method. Then it makes a collective decision for anomaly events by model learners using the model variance. Our algorithm is easily parallelizable, more robust for ill-conditioned and seasonal data, and highly scalable for a large number of anomaly models. We evaluate our algorithm against other state-of-the-art methods on a synthetic domain and a benchmark public data set.
Log2NS: Enhancing Deep Learning Based Analysis of Logs With Formal to Prevent Survivorship Bias
May 29, 2021

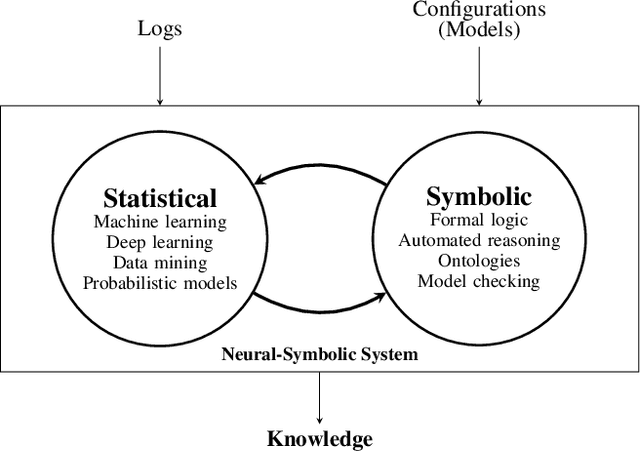

Analysis of large observational data sets generated by a reactive system is a common challenge in debugging system failures and determining their root cause. One of the major problems is that these observational data suffer from survivorship bias. Examples include analyzing traffic logs from networks, and simulation logs from circuit design. In such applications, users want to detect non-spurious correlations from observational data and obtain actionable insights about them. In this paper, we introduce log to Neuro-symbolic (Log2NS), a framework that combines probabilistic analysis from machine learning (ML) techniques on observational data with certainties derived from symbolic reasoning on an underlying formal model. We apply the proposed framework to network traffic debugging by employing the following steps. To detect patterns in network logs, we first generate global embedding vector representations of entities such as IP addresses, ports, and applications. Next, we represent large log flow entries as clusters that make it easier for the user to visualize and detect interesting scenarios that will be further analyzed. To generalize these patterns, Log2NS provides an ability to query from static logs and correlation engines for positive instances, as well as formal reasoning for negative and unseen instances. By combining the strengths of deep learning and symbolic methods, Log2NS provides a very powerful reasoning and debugging tool for log-based data. Empirical evaluations on a real internal data set demonstrate the capabilities of Log2NS.
Boosted Embeddings for Time Series Forecasting
Apr 10, 2021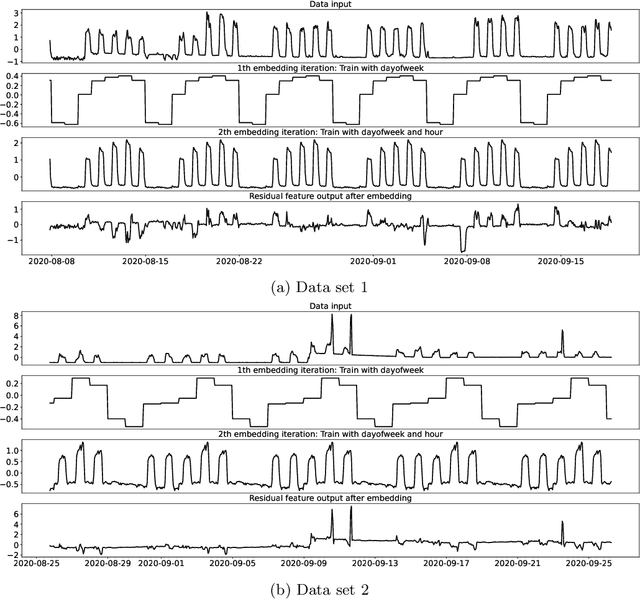

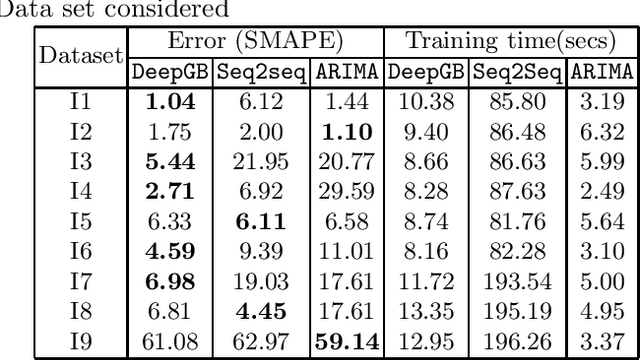
Time series forecasting is a fundamental task emerging from diverse data-driven applications. Many advanced autoregressive methods such as ARIMA were used to develop forecasting models. Recently, deep learning based methods such as DeepAr, NeuralProphet, Seq2Seq have been explored for time series forecasting problem. In this paper, we propose a novel time series forecast model, DeepGB. We formulate and implement a variant of Gradient boosting wherein the weak learners are DNNs whose weights are incrementally found in a greedy manner over iterations. In particular, we develop a new embedding architecture that improves the performance of many deep learning models on time series using Gradient boosting variant. We demonstrate that our model outperforms existing comparable state-of-the-art models using real-world sensor data and public dataset.
One-Shot Induction of Generalized Logical Concepts via Human Guidance
Dec 15, 2019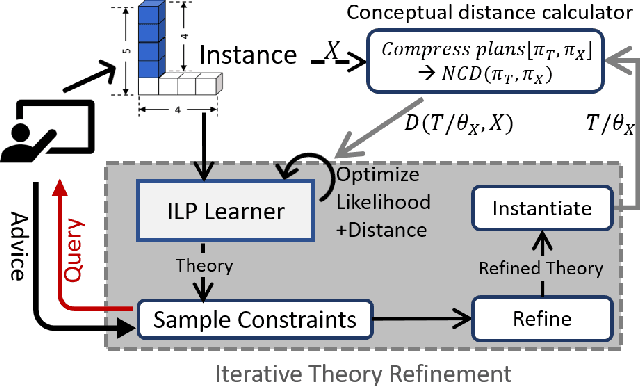

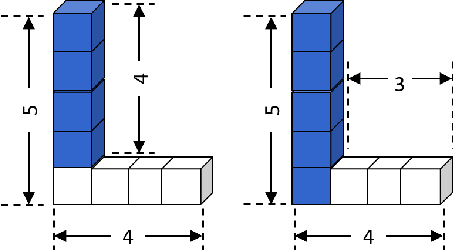
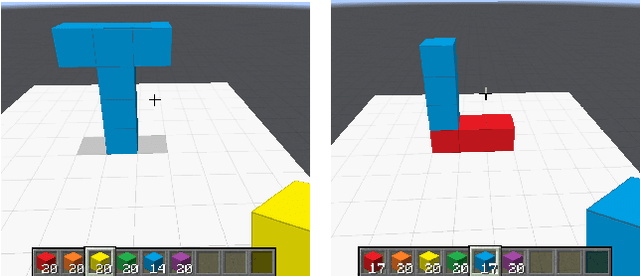
We consider the problem of learning generalized first-order representations of concepts from a single example. To address this challenging problem, we augment an inductive logic programming learner with two novel algorithmic contributions. First, we define a distance measure between candidate concept representations that improves the efficiency of search for target concept and generalization. Second, we leverage richer human inputs in the form of advice to improve the sample-efficiency of learning. We prove that the proposed distance measure is semantically valid and use that to derive a PAC bound. Our experimental analysis on diverse concept learning tasks demonstrates both the effectiveness and efficiency of the proposed approach over a first-order concept learner using only examples.
Structure Learning for Relational Logistic Regression: An Ensemble Approach
Aug 06, 2018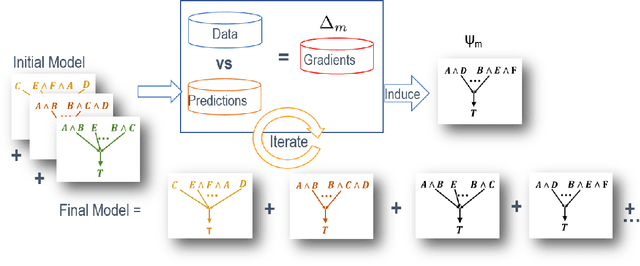
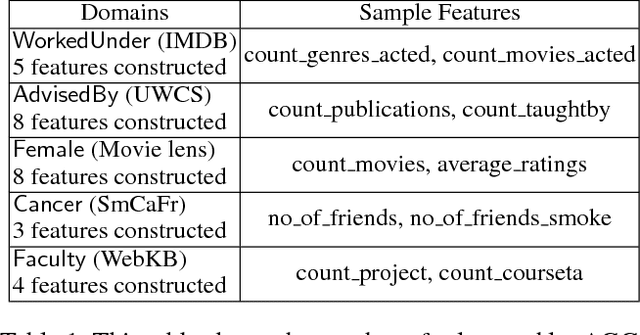
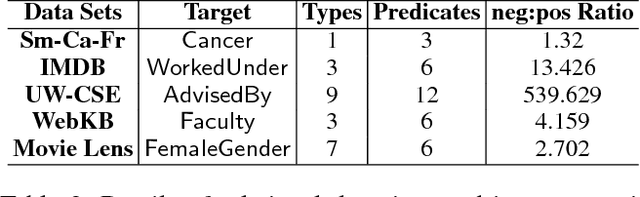
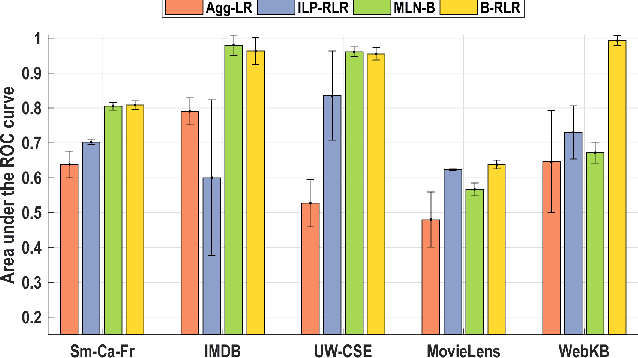
We consider the problem of learning Relational Logistic Regression (RLR). Unlike standard logistic regression, the features of RLRs are first-order formulae with associated weight vectors instead of scalar weights. We turn the problem of learning RLR to learning these vector-weighted formulae and develop a learning algorithm based on the recently successful functional-gradient boosting methods for probabilistic logic models. We derive the functional gradients and show how weights can be learned simultaneously in an efficient manner. Our empirical evaluation on standard and novel data sets demonstrates the superiority of our approach over other methods for learning RLR.