 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Anomaly Detection with label-free Model Selection
Jun 11, 2021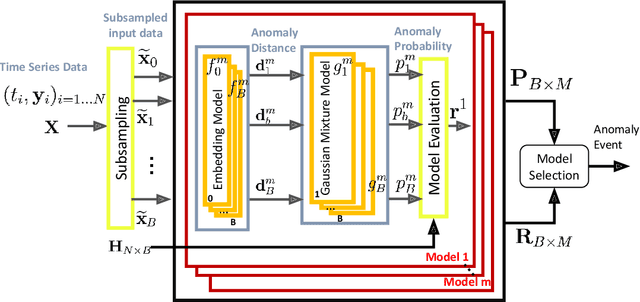

Anomaly detection for time-series data becomes an essential task for many data-driven applications fueled with an abundance of data and out-of-the-box machine-learning algorithms. In many real-world settings, developing a reliable anomaly model is highly challenging due to insufficient anomaly labels and the prohibitively expensive cost of obtaining anomaly examples. It imposes a significant bottleneck to evaluate model quality for model selection and parameter tuning reliably. As a result, many existing anomaly detection algorithms fail to show their promised performance after deployment. In this paper, we propose LaF-AD, a novel anomaly detection algorithm with label-free model selection for unlabeled times-series data. Our proposed algorithm performs a fully unsupervised ensemble learning across a large number of candidate parametric models. We develop a model variance metric that quantifies the sensitivity of anomaly probability with a bootstrapping method. Then it makes a collective decision for anomaly events by model learners using the model variance. Our algorithm is easily parallelizable, more robust for ill-conditioned and seasonal data, and highly scalable for a large number of anomaly models. We evaluate our algorithm against other state-of-the-art methods on a synthetic domain and a benchmark public data set.
Boosted Embeddings for Time Series Forecasting
Apr 10, 2021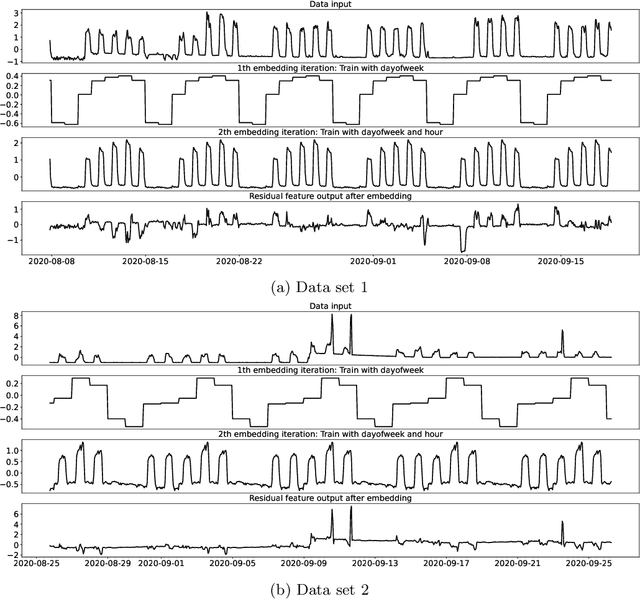

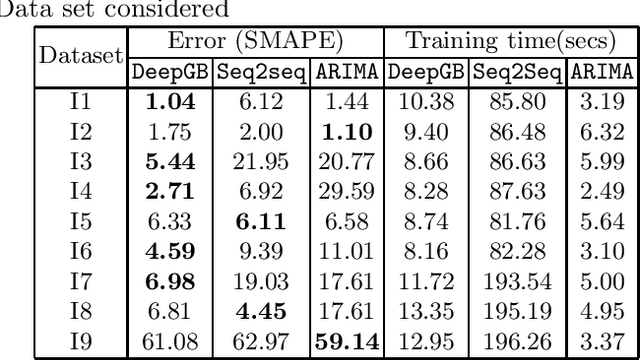
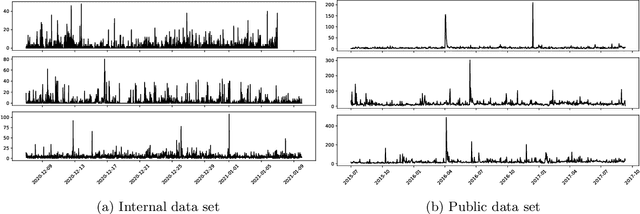
Time series forecasting is a fundamental task emerging from diverse data-driven applications. Many advanced autoregressive methods such as ARIMA were used to develop forecasting models. Recently, deep learning based methods such as DeepAr, NeuralProphet, Seq2Seq have been explored for time series forecasting problem. In this paper, we propose a novel time series forecast model, DeepGB. We formulate and implement a variant of Gradient boosting wherein the weak learners are DNNs whose weights are incrementally found in a greedy manner over iterations. In particular, we develop a new embedding architecture that improves the performance of many deep learning models on time series using Gradient boosting variant. We demonstrate that our model outperforms existing comparable state-of-the-art models using real-world sensor data and public dataset.
Block-Structure Based Time-Series Models For Graph Sequences
Sep 18, 2018


Although the computational and statistical trade-off for modeling single graphs, for instance, using block models is relatively well understood, extending such results to sequences of graphs has proven to be difficult. In this work, we take a step in this direction by proposing two models for graph sequences that capture: (a) link persistence between nodes across time, and (b) community persistence of each node across time. In the first model, we assume that the latent community of each node does not change over time, and in the second model we relax this assumption suitably. For both of these proposed models, we provide statistically and computationally efficient inference algorithms, whose unique feature is that they leverage community detection methods that work on single graphs. We also provide experimental results validating the suitability of our models and methods on synthetic and real instances.