 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Credibility Propagation for Reliable Semi-Supervised Learning
Nov 17, 2022Inferencing unlabeled data from labeled data is an error-prone process. Conventional neural network training is highly sensitive to supervision errors. These two realities make semi-supervised learning (SSL) troublesome. Often, SSL approaches fail to outperform their fully supervised baseline. Proposed is a novel framework for deep SSL, specifically pseudo-labeling, called contrastive credibility propagation (CCP). Through an iterative process of generating and refining soft pseudo-labels, CCP unifies a novel contrastive approach to generating pseudo-labels and a powerful technique to overcome instance-based label noise. The result is a semi-supervised classification framework explicitly designed to overcome inevitable pseudo-label errors in an attempt to reliably boost performance over a supervised baseline. Our empirical evaluation across five benchmark classification datasets suggests one must choose between reliability or effectiveness with prior approaches while CCP delivers both. We also demonstrate an unsupervised signal to subsample pseudo-labels to eliminate errors between iterations of CCP and after its conclusion.
Graph Representation Ensemble Learning
Sep 12, 2019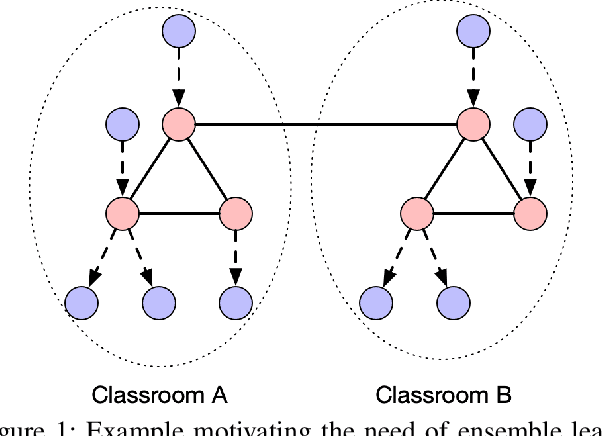
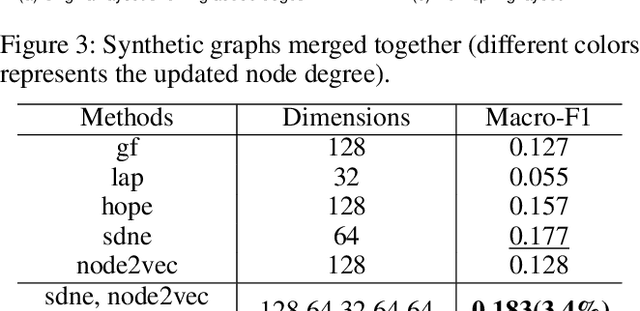
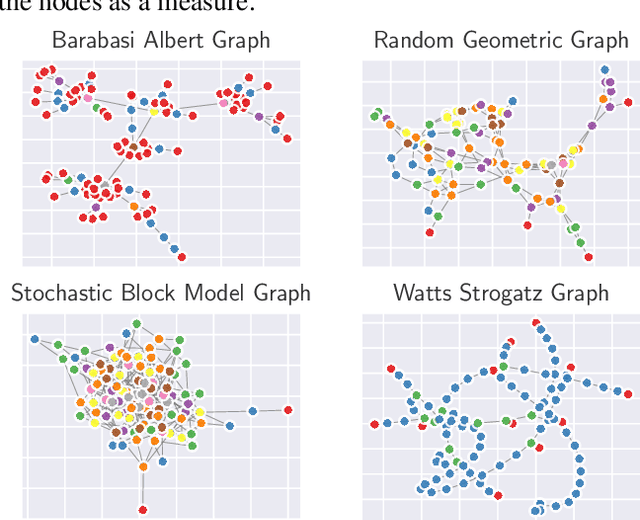
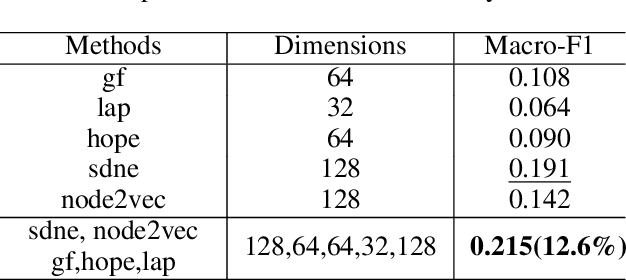
Representation learning on graphs has been gaining attention due to its wide applicability in predicting missing links, and classifying and recommending nodes. Most embedding methods aim to preserve certain properties of the original graph in the low dimensional space. However, real world graphs have a combination of several properties which are difficult to characterize and capture by a single approach. In this work, we introduce the problem of graph representation ensemble learning and provide a first of its kind framework to aggregate multiple graph embedding methods efficiently. We provide analysis of our framework and analyze -- theoretically and empirically -- the dependence between state-of-the-art embedding methods. We test our models on the node classification task on four real world graphs and show that proposed ensemble approaches can outperform the state-of-the-art methods by up to 8% on macro-F1. We further show that the approach is even more beneficial for underrepresented classes providing an improvement of up to 12%.
Benchmarks for Graph Embedding Evaluation
Aug 26, 2019
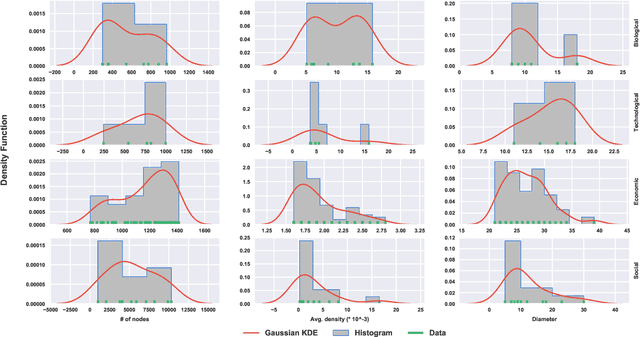
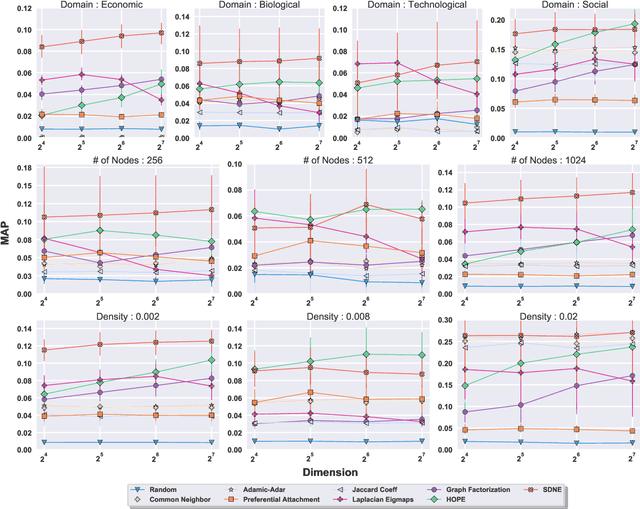
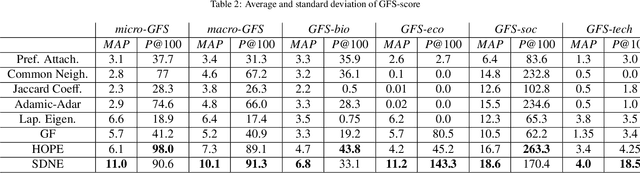
Graph embedding is the task of representing nodes of a graph in a low-dimensional space and its applications for graph tasks have gained significant traction in academia and industry. The primary difference among the many recently proposed graph embedding methods is the way they preserve the inherent properties of the graphs. However, in practice, comparing these methods is very challenging. The majority of methods report performance boosts on few selected real graphs. Therefore, it is difficult to generalize these performance improvements to other types of graphs. Given a graph, it is currently impossible to quantify the advantages of one approach over another. In this work, we introduce a principled framework to compare graph embedding methods. Our goal is threefold: (i) provide a unifying framework for comparing the performance of various graph embedding methods, (ii) establish a benchmark with real-world graphs that exhibit different structural properties, and (iii) provide users with a tool to identify the best graph embedding method for their data. This paper evaluates 4 of the most influential graph embedding methods and 4 traditional link prediction methods against a corpus of 100 real-world networks with varying properties. We organize the 100 networks in terms of their properties to get a better understanding of the embedding performance of these popular methods. We use the comparisons on our 100 benchmark graphs to define GFS-score, that can be applied to any embedding method to quantify its performance. We rank the state-of-the-art embedding approaches using the GFS-score and show that it can be used to understand and evaluate novel embedding approaches. We envision that the proposed framework (https://www.github.com/palash1992/GEM-Benchmark) will serve the community as a benchmarking platform to test and compare the performance of future graph embedding techniques.
Pykg2vec: A Python Library for Knowledge Graph Embedding
Jun 04, 2019
Pykg2vec is an open-source Python library for learning the representations of the entities and relations in knowledge graphs. Pykg2vec's flexible and modular software architecture currently implements 16 state-of-the-art knowledge graph embedding algorithms, and is designed to easily incorporate new algorithms. The goal of pykg2vec is to provide a practical and educational platform to accelerate research in knowledge graph representation learning. Pykg2vec is built on top of TensorFlow and Python's multiprocessing framework and provides modules for batch generation, Bayesian hyperparameter optimization, mean rank evaluation, embedding, and result visualization. Pykg2vec is released under the MIT License and is also available in the Python Package Index (PyPI). The source code of pykg2vec is available at https://github.com/Sujit-O/pykg2vec.
DynamicGEM: A Library for Dynamic Graph Embedding Methods
Nov 26, 2018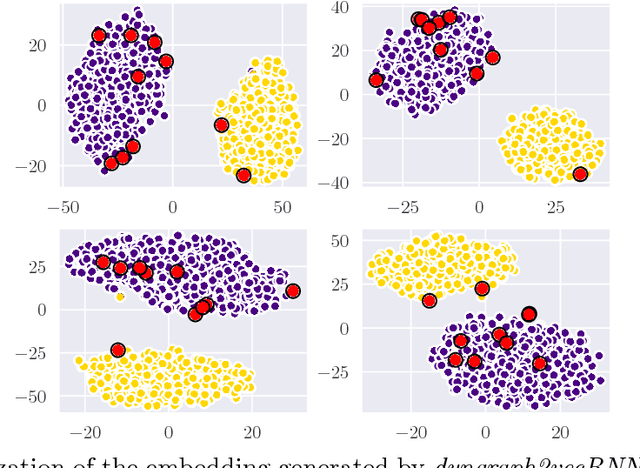
DynamicGEM is an open-source Python library for learning node representations of dynamic graphs. It consists of state-of-the-art algorithms for defining embeddings of nodes whose connections evolve over time. The library also contains the evaluation framework for four downstream tasks on the network: graph reconstruction, static and temporal link prediction, node classification, and temporal visualization. We have implemented various metrics to evaluate the state-of-the-art methods, and examples of evolving networks from various domains. We have easy-to-use functions to call and evaluate the methods and have extensive usage documentation. Furthermore, DynamicGEM provides a template to add new algorithms with ease to facilitate further research on the topic.
dyngraph2vec: Capturing Network Dynamics using Dynamic Graph Representation Learning
Sep 07, 2018
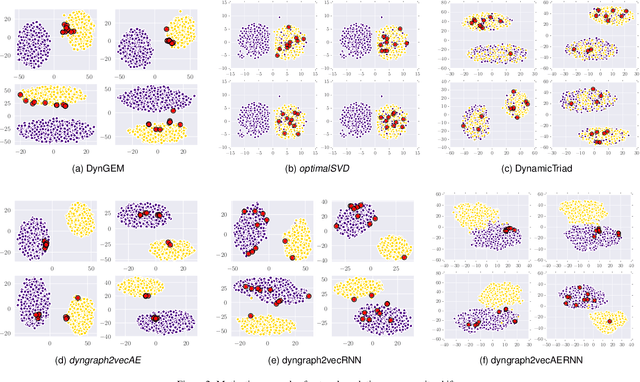
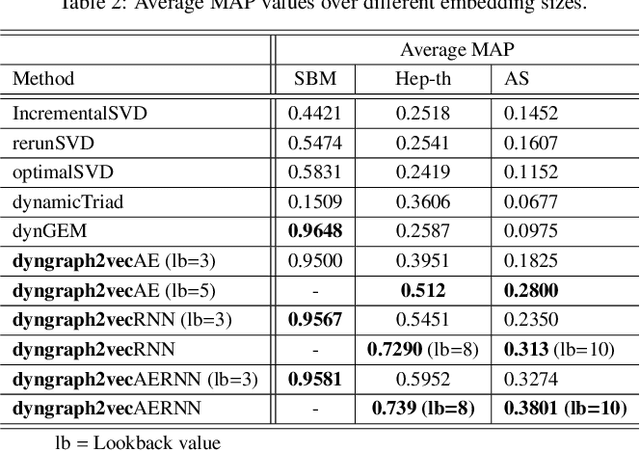
Learning graph representations is a fundamental task aimed at capturing various properties of graphs in vector space. The most recent methods learn such representations for static networks. However, real world networks evolve over time and have varying dynamics. Capturing such evolution is key to predicting the properties of unseen networks. To understand how the network dynamics affect the prediction performance, we propose an embedding approach which learns the structure of evolution in dynamic graphs and can predict unseen links with higher precision. Our model, dyngraph2vec, learns the temporal transitions in the network using a deep architecture composed of dense and recurrent layers. We motivate the need of capturing dynamics for prediction on a toy data set created using stochastic block models. We then demonstrate the efficacy of dyngraph2vec over existing state-of-the-art methods on two real world data sets. We observe that learning dynamics can improve the quality of embedding and yield better performance in link prediction.
Future Automation Engineering using Structural Graph Convolutional Neural Networks
Aug 24, 2018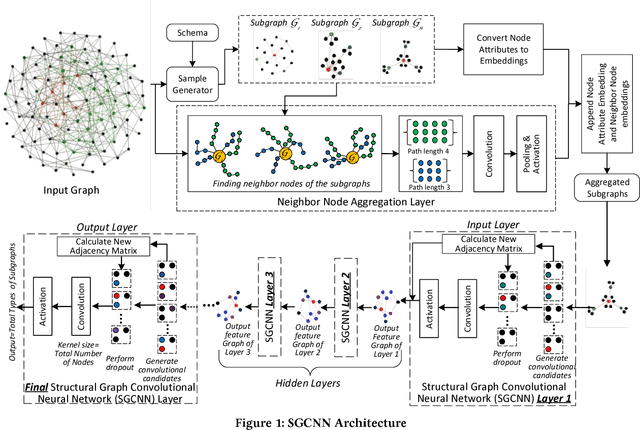
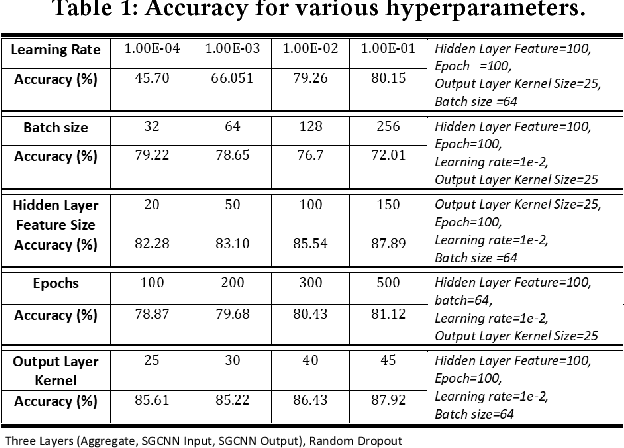
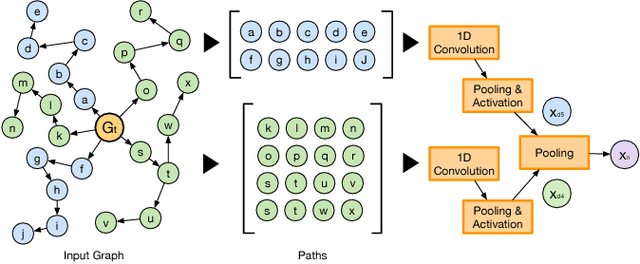
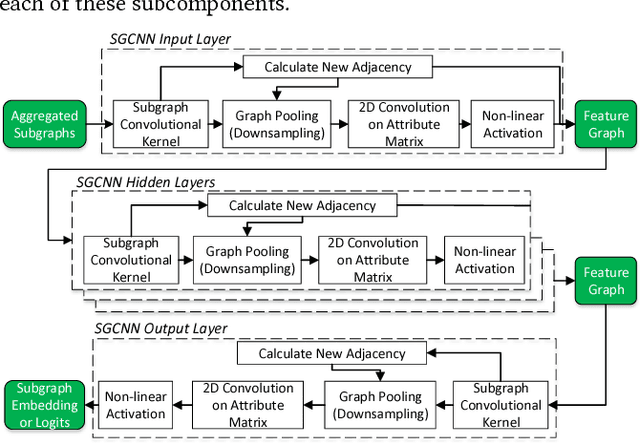
The digitalization of automation engineering generates large quantities of engineering data that is interlinked in knowledge graphs. Classifying and clustering subgraphs according to their functionality is useful to discover functionally equivalent engineering artifacts that exhibit different graph structures. This paper presents a new graph learning algorithm designed to classify engineering data artifacts -- represented in the form of graphs -- according to their structure and neighborhood features. Our Structural Graph Convolutional Neural Network (SGCNN) is capable of learning graphs and subgraphs with a novel graph invariant convolution kernel and downsampling/pooling algorithm. On a realistic engineering-related dataset, we show that SGCNN is capable of achieving ~91% classification accuracy.