 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShrinking Bigfoot: Reducing wav2vec 2.0 footprint
Apr 01, 2021
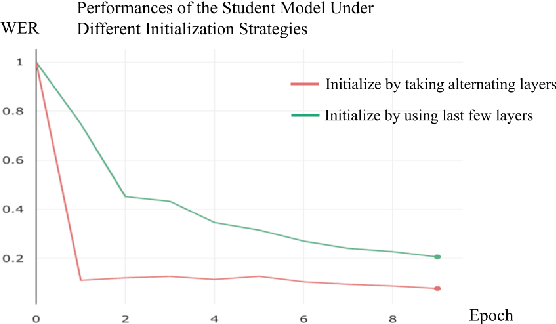
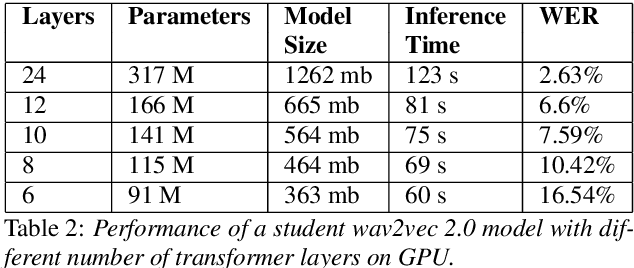
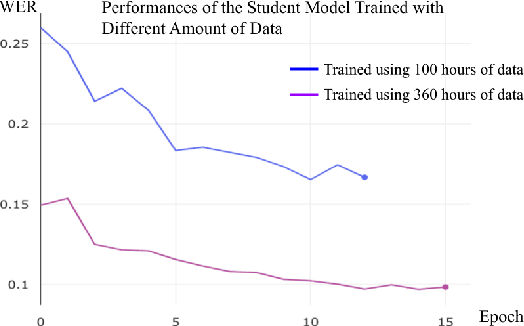
Wav2vec 2.0 is a state-of-the-art speech recognition model which maps speech audio waveforms into latent representations. The largest version of wav2vec 2.0 contains 317 million parameters. Hence, the inference latency of wav2vec 2.0 will be a bottleneck in production, leading to high costs and a significant environmental footprint. To improve wav2vec's applicability to a production setting, we explore multiple model compression methods borrowed from the domain of large language models. Using a teacher-student approach, we distilled the knowledge from the original wav2vec 2.0 model into a student model, which is 2 times faster and 4.8 times smaller than the original model. This increase in performance is accomplished with only a 7% degradation in word error rate (WER). Our quantized model is 3.6 times smaller than the original model, with only a 0.1% degradation in WER. To the best of our knowledge, this is the first work that compresses wav2vec 2.0.
Writing Style Invariant Deep Learning Model for Historical Manuscripts Alignment
Jun 07, 2018
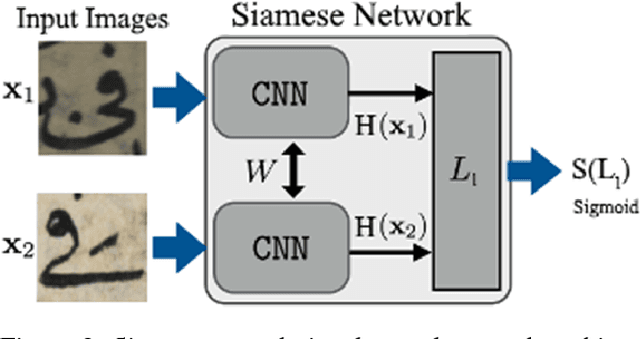


Historical manuscript alignment is a widely known problem in document analysis. Finding the differences between manuscript editions is mostly done manually. In this paper, we present a writer independent deep learning model which is trained on several writing styles, and able to achieve high detection accuracy when tested on writing styles not present in training data. We test our model using cross validation, each time we train the model on five manuscripts, and test it on the other two manuscripts, never seen in the training data. We've applied cross validation on seven manuscripts, netting 21 different tests, achieving average accuracy of $\%92.17$. We also present a new alignment algorithm based on dynamic sized sliding window, which is able to successfully handle complex cases.