 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigation Objects Extraction for Better Content Structure Understanding
Aug 26, 2017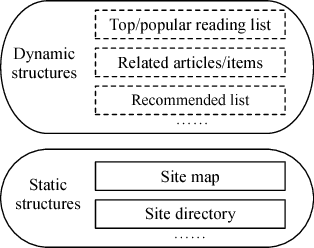
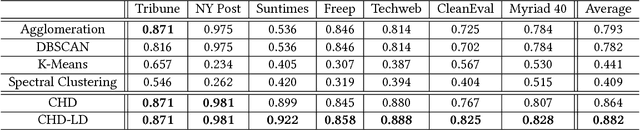
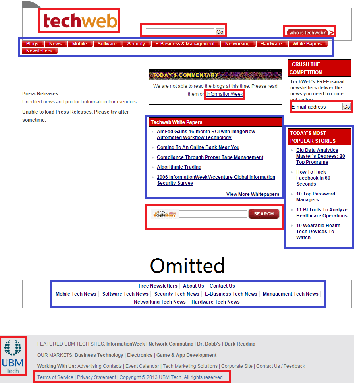
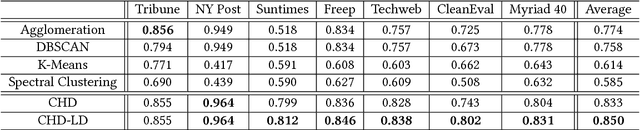
Existing works for extracting navigation objects from webpages focus on navigation menus, so as to reveal the information architecture of the site. However, web 2.0 sites such as social networks, e-commerce portals etc. are making the understanding of the content structure in a web site increasingly difficult. Dynamic and personalized elements such as top stories, recommended list in a webpage are vital to the understanding of the dynamic nature of web 2.0 sites. To better understand the content structure in web 2.0 sites, in this paper we propose a new extraction method for navigation objects in a webpage. Our method will extract not only the static navigation menus, but also the dynamic and personalized page-specific navigation lists. Since the navigation objects in a webpage naturally come in blocks, we first cluster hyperlinks into different blocks by exploiting spatial locations of hyperlinks, the hierarchical structure of the DOM-tree and the hyperlink density. Then we identify navigation objects from those blocks using the SVM classifier with novel features such as anchor text lengths etc. Experiments on real-world data sets with webpages from various domains and styles verified the effectiveness of our method.