 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaLeNet: Multimodal Learning for Disaster Prediction, Management and Relief
Jun 18, 2022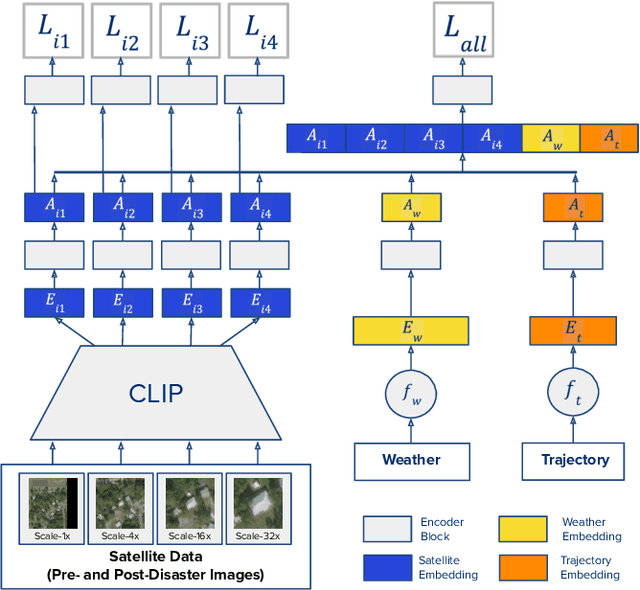
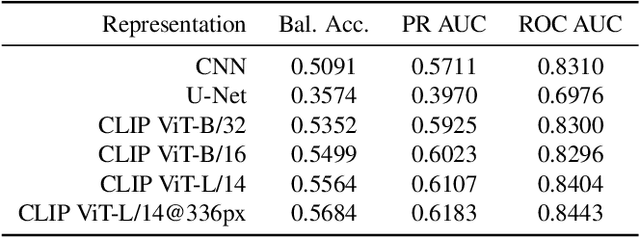
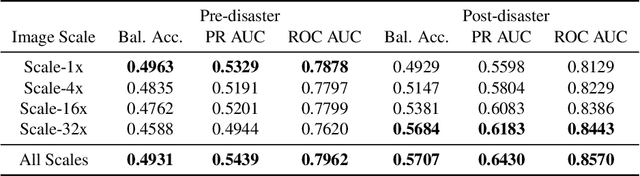
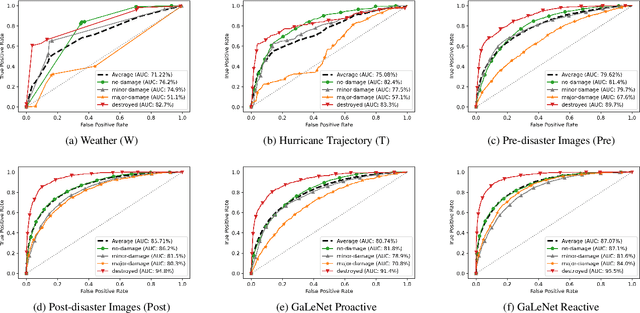
After a natural disaster, such as a hurricane, millions are left in need of emergency assistance. To allocate resources optimally, human planners need to accurately analyze data that can flow in large volumes from several sources. This motivates the development of multimodal machine learning frameworks that can integrate multiple data sources and leverage them efficiently. To date, the research community has mainly focused on unimodal reasoning to provide granular assessments of the damage. Moreover, previous studies mostly rely on post-disaster images, which may take several days to become available. In this work, we propose a multimodal framework (GaLeNet) for assessing the severity of damage by complementing pre-disaster images with weather data and the trajectory of the hurricane. Through extensive experiments on data from two hurricanes, we demonstrate (i) the merits of multimodal approaches compared to unimodal methods, and (ii) the effectiveness of GaLeNet at fusing various modalities. Furthermore, we show that GaLeNet can leverage pre-disaster images in the absence of post-disaster images, preventing substantial delays in decision making.
On the Trustworthiness of Tree Ensemble Explainability Methods
Sep 30, 2021
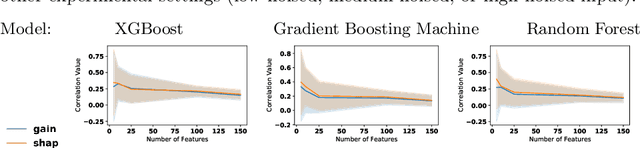
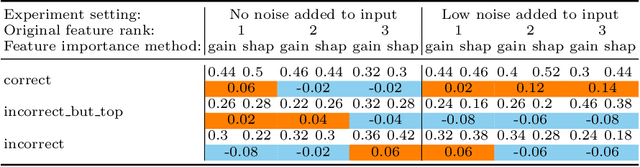

The recent increase in the deployment of machine learning models in critical domains such as healthcare, criminal justice, and finance has highlighted the need for trustworthy methods that can explain these models to stakeholders. Feature importance methods (e.g. gain and SHAP) are among the most popular explainability methods used to address this need. For any explainability technique to be trustworthy and meaningful, it has to provide an explanation that is accurate and stable. Although the stability of local feature importance methods (explaining individual predictions) has been studied before, there is yet a knowledge gap about the stability of global features importance methods (explanations for the whole model). Additionally, there is no study that evaluates and compares the accuracy of global feature importance methods with respect to feature ordering. In this paper, we evaluate the accuracy and stability of global feature importance methods through comprehensive experiments done on simulations as well as four real-world datasets. We focus on tree-based ensemble methods as they are used widely in industry and measure the accuracy and stability of explanations under two scenarios: 1) when inputs are perturbed 2) when models are perturbed. Our findings provide a comparison of these methods under a variety of settings and shed light on the limitations of global feature importance methods by indicating their lack of accuracy with and without noisy inputs, as well as their lack of stability with respect to: 1) increase in input dimension or noise in the data; 2) perturbations in models initialized by different random seeds or hyperparameter settings.
Prediction of New Onset Diabetes after Liver Transplant
Dec 03, 2018



25% of people who received a liver transplant will go on to develop diabetes within the next 5 years. These thousands of individuals are at 2-fold higher risk of cardiovascular events, graft loss, infections, as well as lower long-term survival. This is partly due to the medication used during and/or after transplant that significantly impacts metabolic balance. To assess which medication best suits the patient's condition, clinicians need an accurate estimate of diabetes risk. Both patient's historical data and observations at the current visit are informative in predicting whether the patient will develop diabetes within the following year. In this work we compared a variety of time-to-event prediction models as well as classifiers predicting the likelihood of the event within a year from the current checkup. We are particularly interested in comparing two types of models: 1) standard time-to-event predictors where the historical measurements are merely concatenated, 2) incorporating Deep Markov Model to first obtain low-dimensional embedding of historical data and then using this embedding as an additional input into the model. We compared a variety of algorithms including standard and regularized Cox proportional-hazards model (CPH), mixed effect random forests, survival-forests and Weibull Time-To-Event Recurrent Neural Network (WTTE-RNN). The results show that although all methods' performances varied from year to year and there was no clear winner across all the time points, regularized CPH model that used 1 to 3 years of historical visits data on average achieved a high, clinically relevant Concordance Index of .863. We thus recommend this model for further prospective clinical validation and hopefully, an eventual use in the clinic to improve clinicians' ability to personalize post-operative care and reduce the incidence of new-onset diabetes post liver transplant.