 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegalLens Shared Task 2024: Legal Violation Identification in Unstructured Text
Oct 15, 2024


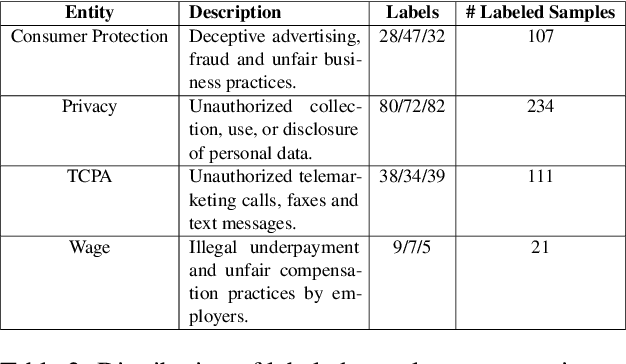
This paper presents the results of the LegalLens Shared Task, focusing on detecting legal violations within text in the wild across two sub-tasks: LegalLens-NER for identifying legal violation entities and LegalLens-NLI for associating these violations with relevant legal contexts and affected individuals. Using an enhanced LegalLens dataset covering labor, privacy, and consumer protection domains, 38 teams participated in the task. Our analysis reveals that while a mix of approaches was used, the top-performing teams in both tasks consistently relied on fine-tuning pre-trained language models, outperforming legal-specific models and few-shot methods. The top-performing team achieved a 7.11% improvement in NER over the baseline, while NLI saw a more marginal improvement of 5.7%. Despite these gains, the complexity of legal texts leaves room for further advancements.
LegalLens: Leveraging LLMs for Legal Violation Identification in Unstructured Text
Feb 06, 2024In this study, we focus on two main tasks, the first for detecting legal violations within unstructured textual data, and the second for associating these violations with potentially affected individuals. We constructed two datasets using Large Language Models (LLMs) which were subsequently validated by domain expert annotators. Both tasks were designed specifically for the context of class-action cases. The experimental design incorporated fine-tuning models from the BERT family and open-source LLMs, and conducting few-shot experiments using closed-source LLMs. Our results, with an F1-score of 62.69\% (violation identification) and 81.02\% (associating victims), show that our datasets and setups can be used for both tasks. Finally, we publicly release the datasets and the code used for the experiments in order to advance further research in the area of legal natural language processing (NLP).
GaLeNet: Multimodal Learning for Disaster Prediction, Management and Relief
Jun 18, 2022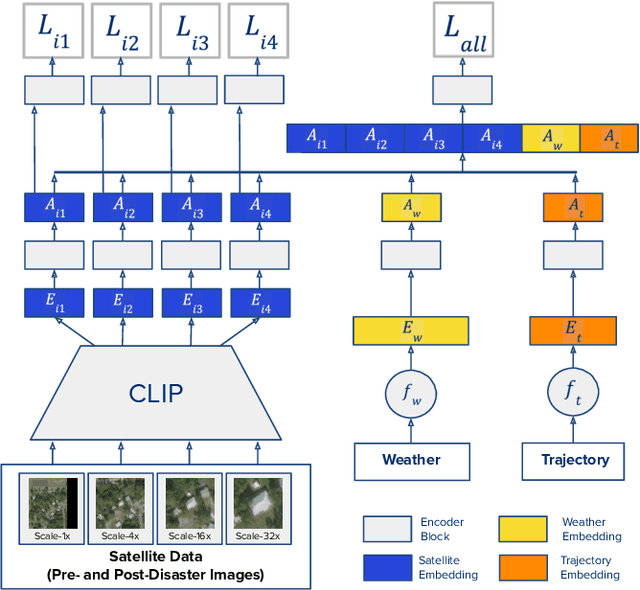
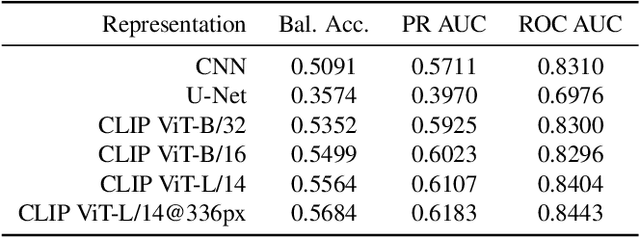
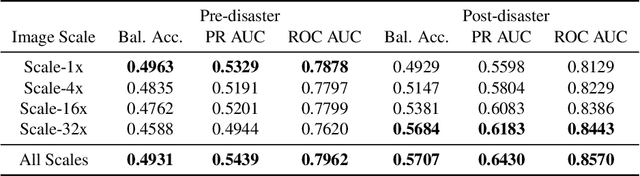
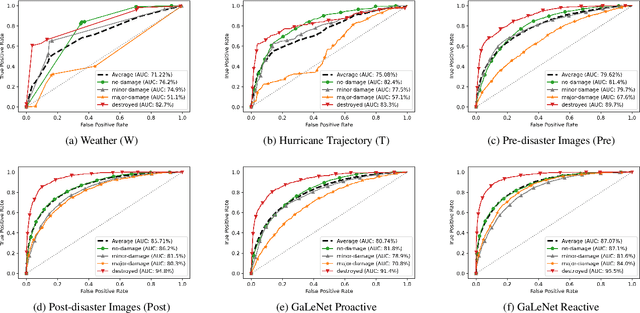
After a natural disaster, such as a hurricane, millions are left in need of emergency assistance. To allocate resources optimally, human planners need to accurately analyze data that can flow in large volumes from several sources. This motivates the development of multimodal machine learning frameworks that can integrate multiple data sources and leverage them efficiently. To date, the research community has mainly focused on unimodal reasoning to provide granular assessments of the damage. Moreover, previous studies mostly rely on post-disaster images, which may take several days to become available. In this work, we propose a multimodal framework (GaLeNet) for assessing the severity of damage by complementing pre-disaster images with weather data and the trajectory of the hurricane. Through extensive experiments on data from two hurricanes, we demonstrate (i) the merits of multimodal approaches compared to unimodal methods, and (ii) the effectiveness of GaLeNet at fusing various modalities. Furthermore, we show that GaLeNet can leverage pre-disaster images in the absence of post-disaster images, preventing substantial delays in decision making.