 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoFraudNet: A Multimodal Network to Detect Fraud in the Auto Insurance Industry
Jan 15, 2023In the insurance industry detecting fraudulent claims is a critical task with a significant financial impact. A common strategy to identify fraudulent claims is looking for inconsistencies in the supporting evidence. However, this is a laborious and cognitively heavy task for human experts as insurance claims typically come with a plethora of data from different modalities (e.g. images, text and metadata). To overcome this challenge, the research community has focused on multimodal machine learning frameworks that can efficiently reason through multiple data sources. Despite recent advances in multimodal learning, these frameworks still suffer from (i) challenges of joint-training caused by the different characteristics of different modalities and (ii) overfitting tendencies due to high model complexity. In this work, we address these challenges by introducing a multimodal reasoning framework, AutoFraudNet (Automobile Insurance Fraud Detection Network), for detecting fraudulent auto-insurance claims. AutoFraudNet utilizes a cascaded slow fusion framework and state-of-the-art fusion block, BLOCK Tucker, to alleviate the challenges of joint-training. Furthermore, it incorporates a light-weight architectural design along with additional losses to prevent overfitting. Through extensive experiments conducted on a real-world dataset, we demonstrate: (i) the merits of multimodal approaches, when compared to unimodal and bimodal methods, and (ii) the effectiveness of AutoFraudNet in fusing various modalities to boost performance (over 3\% in PR AUC).
GaLeNet: Multimodal Learning for Disaster Prediction, Management and Relief
Jun 18, 2022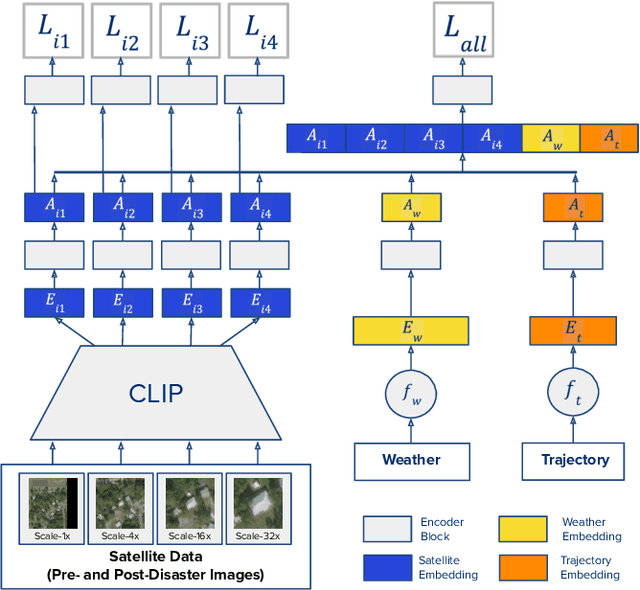
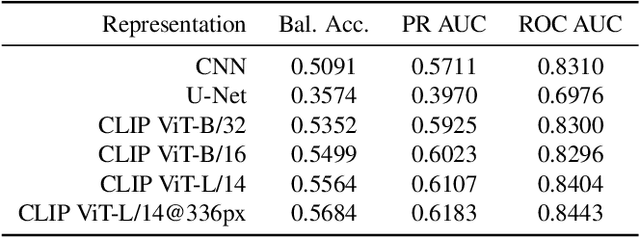
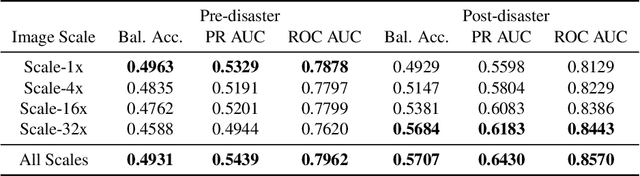
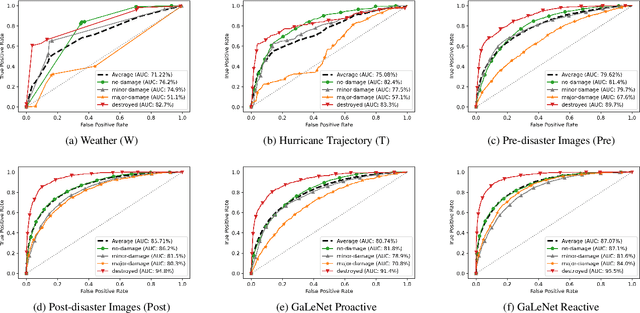
After a natural disaster, such as a hurricane, millions are left in need of emergency assistance. To allocate resources optimally, human planners need to accurately analyze data that can flow in large volumes from several sources. This motivates the development of multimodal machine learning frameworks that can integrate multiple data sources and leverage them efficiently. To date, the research community has mainly focused on unimodal reasoning to provide granular assessments of the damage. Moreover, previous studies mostly rely on post-disaster images, which may take several days to become available. In this work, we propose a multimodal framework (GaLeNet) for assessing the severity of damage by complementing pre-disaster images with weather data and the trajectory of the hurricane. Through extensive experiments on data from two hurricanes, we demonstrate (i) the merits of multimodal approaches compared to unimodal methods, and (ii) the effectiveness of GaLeNet at fusing various modalities. Furthermore, we show that GaLeNet can leverage pre-disaster images in the absence of post-disaster images, preventing substantial delays in decision making.
On the Trustworthiness of Tree Ensemble Explainability Methods
Sep 30, 2021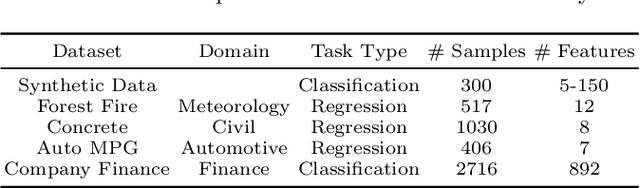
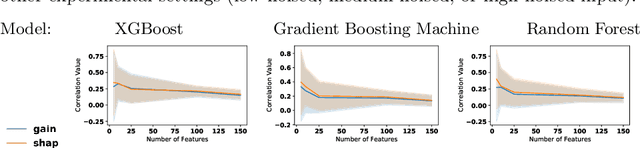
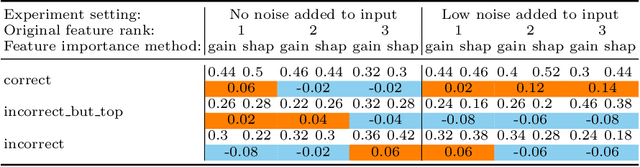

The recent increase in the deployment of machine learning models in critical domains such as healthcare, criminal justice, and finance has highlighted the need for trustworthy methods that can explain these models to stakeholders. Feature importance methods (e.g. gain and SHAP) are among the most popular explainability methods used to address this need. For any explainability technique to be trustworthy and meaningful, it has to provide an explanation that is accurate and stable. Although the stability of local feature importance methods (explaining individual predictions) has been studied before, there is yet a knowledge gap about the stability of global features importance methods (explanations for the whole model). Additionally, there is no study that evaluates and compares the accuracy of global feature importance methods with respect to feature ordering. In this paper, we evaluate the accuracy and stability of global feature importance methods through comprehensive experiments done on simulations as well as four real-world datasets. We focus on tree-based ensemble methods as they are used widely in industry and measure the accuracy and stability of explanations under two scenarios: 1) when inputs are perturbed 2) when models are perturbed. Our findings provide a comparison of these methods under a variety of settings and shed light on the limitations of global feature importance methods by indicating their lack of accuracy with and without noisy inputs, as well as their lack of stability with respect to: 1) increase in input dimension or noise in the data; 2) perturbations in models initialized by different random seeds or hyperparameter settings.
Prediction of Workplace Injuries
Jun 05, 2019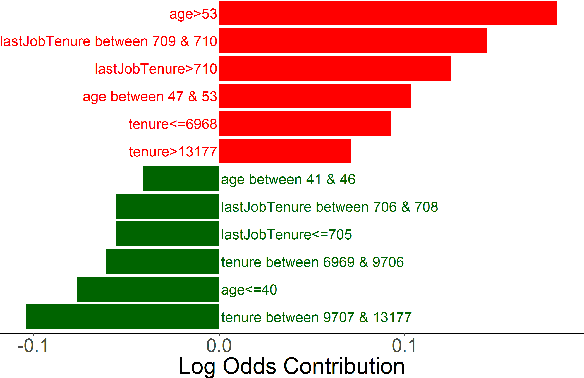
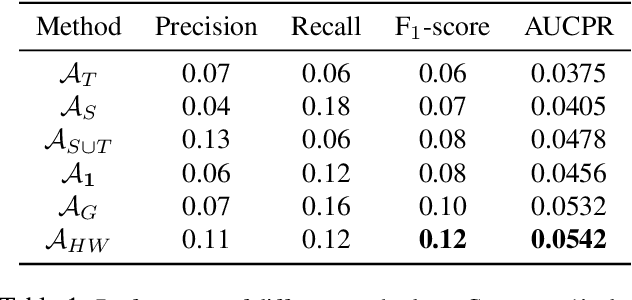
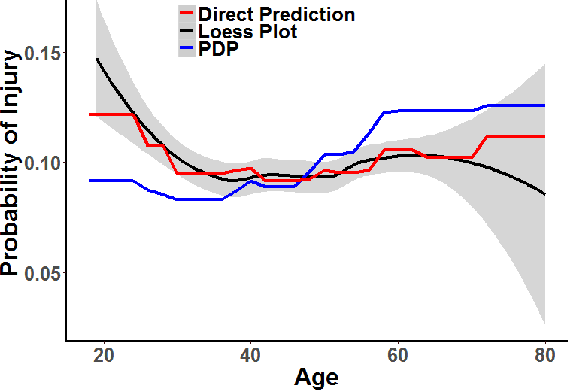
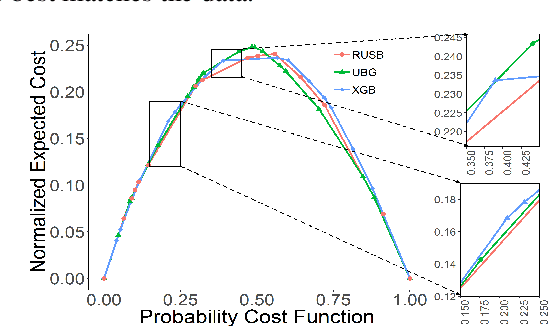
Workplace injuries result in substantial human and financial losses. As reported by the International Labour Organization (ILO), there are more than 374 million work-related injuries reported every year. In this study, we investigate the problem of injury risk prediction and prevention in a work environment. While injuries represent a significant number across all organizations, they are rare events within a single organization. Hence, collecting a sufficiently large dataset from a single organization is extremely difficult. In addition, the collected datasets are often highly imbalanced which increases the problem difficulty. Finally, risk predictions need to provide additional context for injuries to be prevented. We propose and evaluate the following for a complete solution: 1) several ensemble-based resampling methods to address the class imbalance issues, 2) a novel transfer learning approach to transfer the knowledge across organizations, and 3) various techniques to uncover the association and causal effect of different variables on injury risk, while controlling for relevant confounding factors.
Limitations and Biases in Facial Landmark Detection -- An Empirical Study on Older Adults with Dementia
May 17, 2019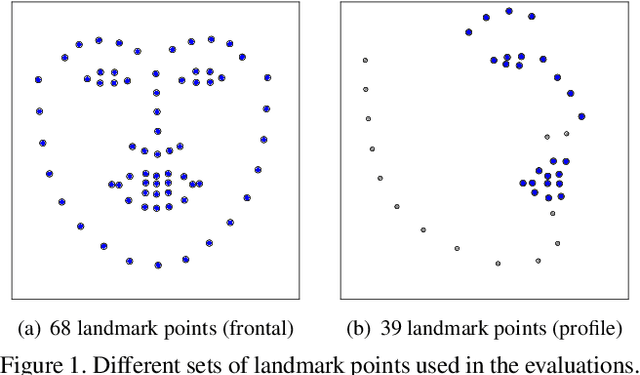
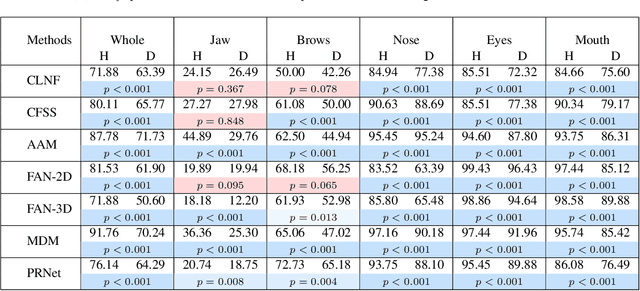
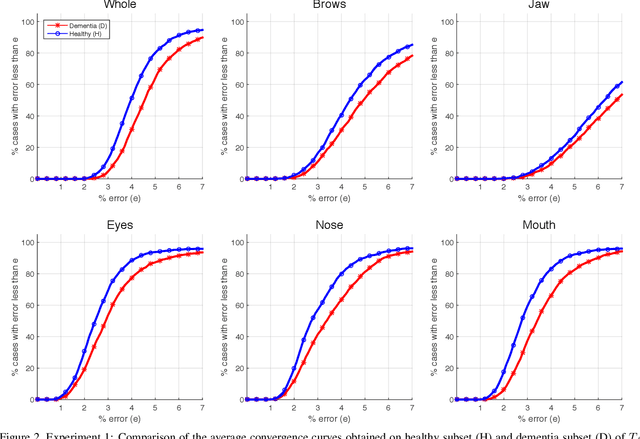
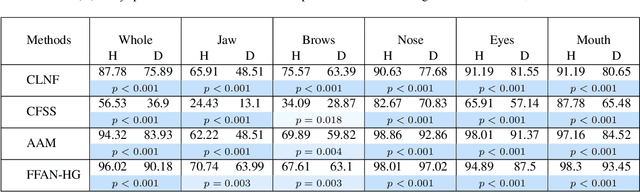
Accurate facial expression analysis is an essential step in various clinical applications that involve physical and mental health assessments of older adults (e.g. diagnosis of pain or depression). Although remarkable progress has been achieved toward developing robust facial landmark detection methods, state-of-the-art methods still face many challenges when encountering uncontrolled environments, different ranges of facial expressions, and different demographics of the population. A recent study has revealed that the health status of individuals can also affect the performance of facial landmark detection methods on front views of faces. In this work, we investigate this matter in a much greater context using seven facial landmark detection methods. We perform our evaluation not only on frontal faces but also on profile faces and in various regions of the face. Our results shed light on limitations of the existing methods and challenges of applying these methods in clinical settings by indicating: 1) a significant difference between the performance of state-of-the-art when tested on the profile or frontal faces of individuals with vs. without dementia; 2) insights on the existing bias for all regions of the face; and 3) the presence of this bias despite re-training/fine-tuning with various configurations of six datasets.
A Hybrid Instance-based Transfer Learning Method
Dec 03, 2018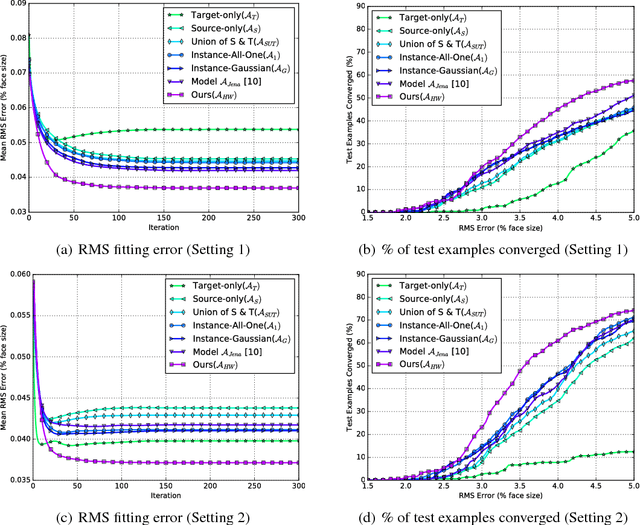
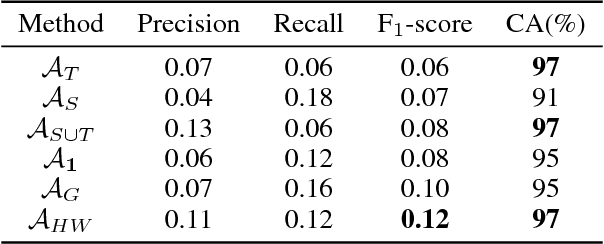
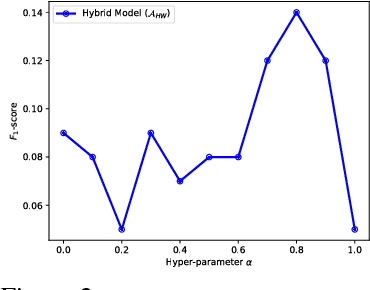

In recent years, supervised machine learning models have demonstrated tremendous success in a variety of application domains. Despite the promising results, these successful models are data hungry and their performance relies heavily on the size of training data. However, in many healthcare applications it is difficult to collect sufficiently large training datasets. Transfer learning can help overcome this issue by transferring the knowledge from readily available datasets (source) to a new dataset (target). In this work, we propose a hybrid instance-based transfer learning method that outperforms a set of baselines including state-of-the-art instance-based transfer learning approaches. Our method uses a probabilistic weighting strategy to fuse information from the source domain to the model learned in the target domain. Our method is generic, applicable to multiple source domains, and robust with respect to negative transfer. We demonstrate the effectiveness of our approach through extensive experiments for two different applications.
Subspace Selection to Suppress Confounding Source Domain Information in AAM Transfer Learning
Oct 03, 2017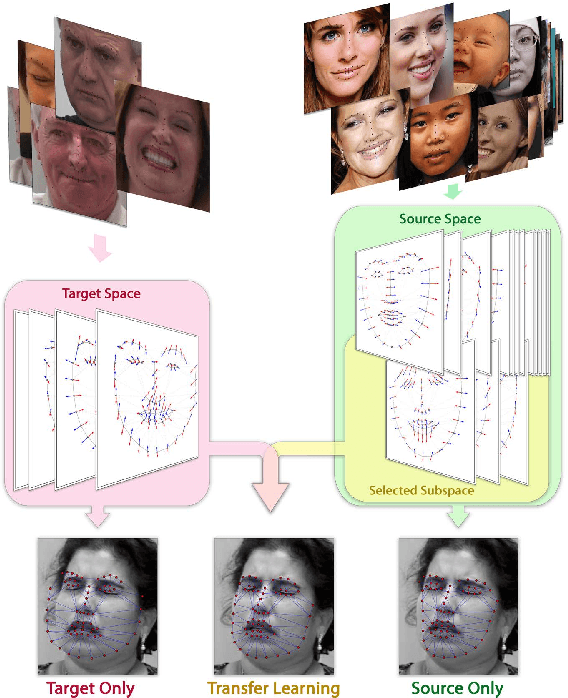
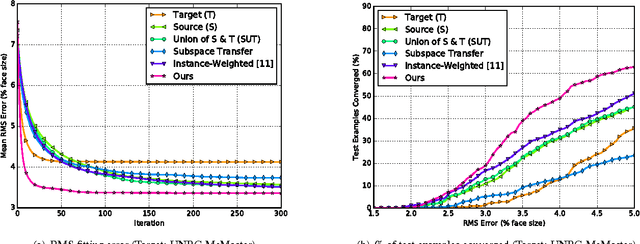
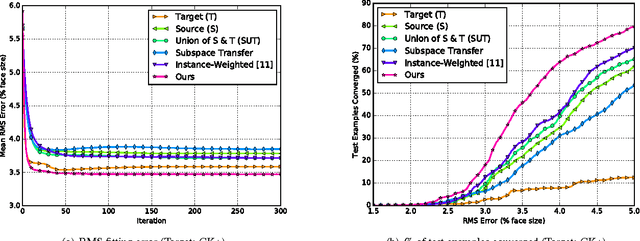
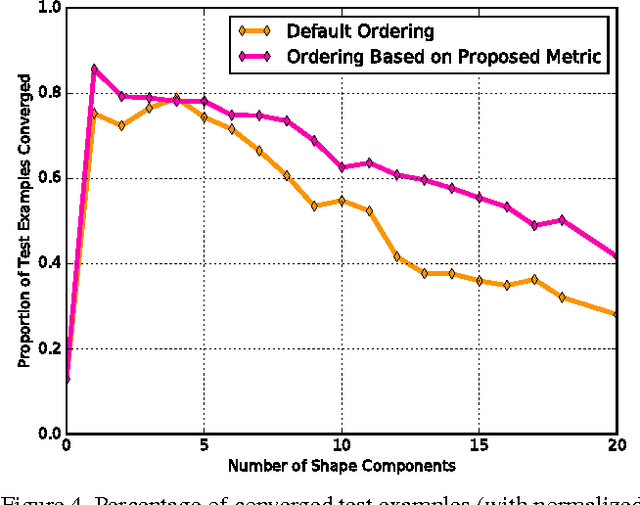
Active appearance models (AAMs) are a class of generative models that have seen tremendous success in face analysis. However, model learning depends on the availability of detailed annotation of canonical landmark points. As a result, when accurate AAM fitting is required on a different set of variations (expression, pose, identity), a new dataset is collected and annotated. To overcome the need for time consuming data collection and annotation, transfer learning approaches have received recent attention. The goal is to transfer knowledge from previously available datasets (source) to a new dataset (target). We propose a subspace transfer learning method, in which we select a subspace from the source that best describes the target space. We propose a metric to compute the directional similarity between the source eigenvectors and the target subspace. We show an equivalence between this metric and the variance of target data when projected onto source eigenvectors. Using this equivalence, we select a subset of source principal directions that capture the variance in target data. To define our model, we augment the selected source subspace with the target subspace learned from a handful of target examples. In experiments done on six publicly available datasets, we show that our approach outperforms the state of the art in terms of the RMS fitting error as well as the percentage of test examples for which AAM fitting converges to the ground truth.