 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn information-Theoretic Approach to Semi-supervised Transfer Learning
Jun 11, 2023Transfer learning is a valuable tool in deep learning as it allows propagating information from one "source dataset" to another "target dataset", especially in the case of a small number of training examples in the latter. Yet, discrepancies between the underlying distributions of the source and target data are commonplace and are known to have a substantial impact on algorithm performance. In this work we suggest novel information-theoretic approaches for the analysis of the performance of deep neural networks in the context of transfer learning. We focus on the task of semi-supervised transfer learning, in which unlabeled samples from the target dataset are available during network training on the source dataset. Our theory suggests that one may improve the transferability of a deep neural network by incorporating regularization terms on the target data based on information-theoretic quantities, namely the Mutual Information and the Lautum Information. We demonstrate the effectiveness of the proposed approaches in various semi-supervised transfer learning experiments.
AutoFraudNet: A Multimodal Network to Detect Fraud in the Auto Insurance Industry
Jan 15, 2023In the insurance industry detecting fraudulent claims is a critical task with a significant financial impact. A common strategy to identify fraudulent claims is looking for inconsistencies in the supporting evidence. However, this is a laborious and cognitively heavy task for human experts as insurance claims typically come with a plethora of data from different modalities (e.g. images, text and metadata). To overcome this challenge, the research community has focused on multimodal machine learning frameworks that can efficiently reason through multiple data sources. Despite recent advances in multimodal learning, these frameworks still suffer from (i) challenges of joint-training caused by the different characteristics of different modalities and (ii) overfitting tendencies due to high model complexity. In this work, we address these challenges by introducing a multimodal reasoning framework, AutoFraudNet (Automobile Insurance Fraud Detection Network), for detecting fraudulent auto-insurance claims. AutoFraudNet utilizes a cascaded slow fusion framework and state-of-the-art fusion block, BLOCK Tucker, to alleviate the challenges of joint-training. Furthermore, it incorporates a light-weight architectural design along with additional losses to prevent overfitting. Through extensive experiments conducted on a real-world dataset, we demonstrate: (i) the merits of multimodal approaches, when compared to unimodal and bimodal methods, and (ii) the effectiveness of AutoFraudNet in fusing various modalities to boost performance (over 3\% in PR AUC).
Lautum Regularization for Semi-supervised Transfer Learning
Apr 02, 2019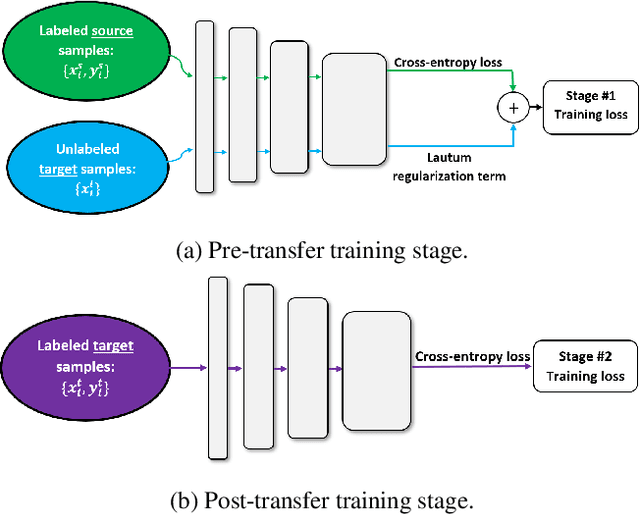
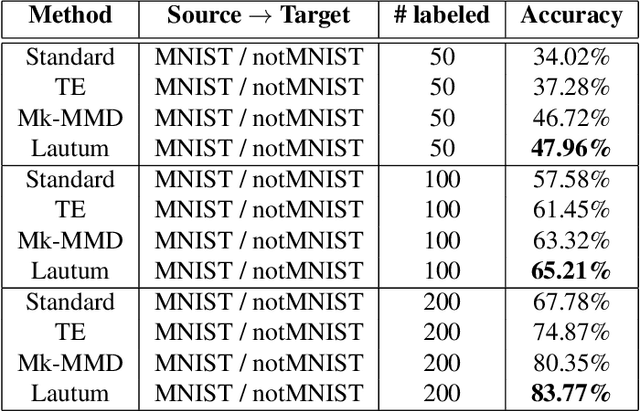
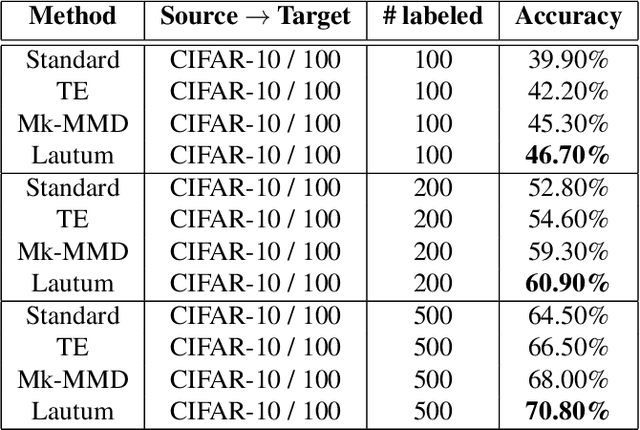
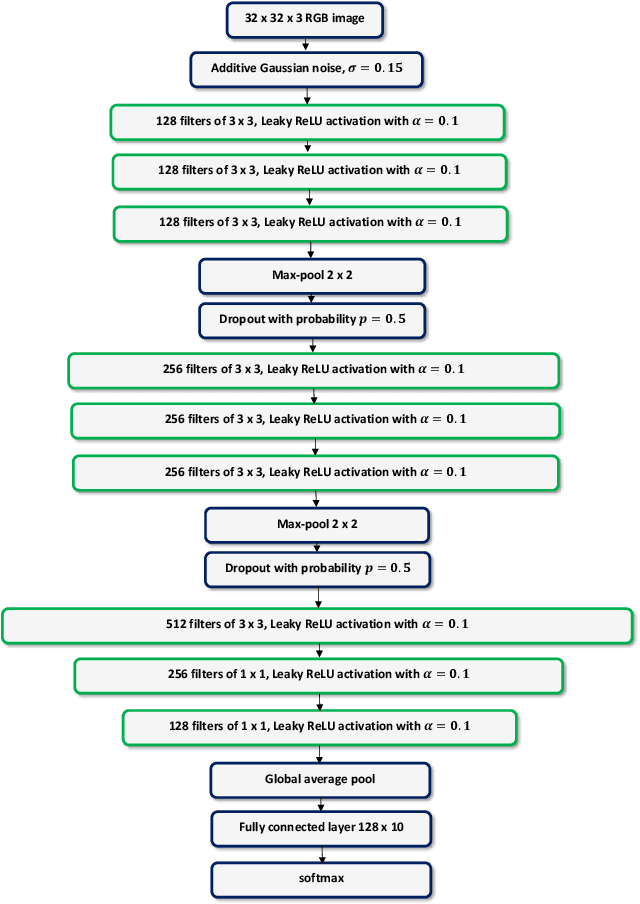
Transfer learning is a very important tool in deep learning as it allows propagating information from one "source dataset" to another "target dataset", especially in the case of a small number of training examples in the latter. Yet, discrepancies between the underlying distributions of the source and target data are commonplace and are known to have a substantial impact on algorithm performance. In this work we suggest a novel information theoretic approach for the analysis of the performance of deep neural networks in the context of transfer learning. We focus on the task of semi-supervised transfer learning, in which unlabeled samples from the target dataset are available during the network training on the source dataset. Our theory suggests that one may improve the transferability of a deep neural network by imposing a Lautum information based regularization that relates the network weights to the target data. We demonstrate in various transfer learning experiments the effectiveness of the proposed approach.
Improving DNN Robustness to Adversarial Attacks using Jacobian Regularization
Aug 26, 2018
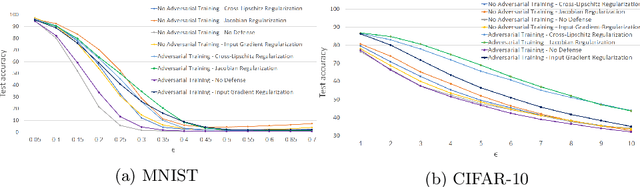

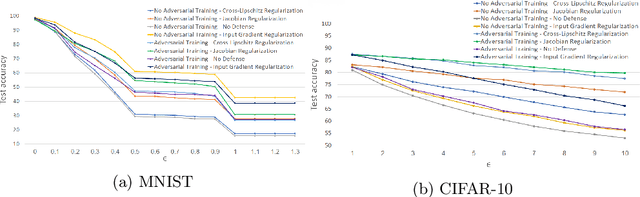
Deep neural networks have lately shown tremendous performance in various applications including vision and speech processing tasks. However, alongside their ability to perform these tasks with such high accuracy, it has been shown that they are highly susceptible to adversarial attacks: a small change in the input would cause the network to err with high confidence. This phenomenon exposes an inherent fault in these networks and their ability to generalize well. For this reason, providing robustness to adversarial attacks is an important challenge in networks training, which has led to extensive research. In this work, we suggest a theoretically inspired novel approach to improve the networks' robustness. Our method applies regularization using the Frobenius norm of the Jacobian of the network, which is applied as post-processing, after regular training has finished. We demonstrate empirically that it leads to enhanced robustness results with a minimal change in the original network's accuracy.
Generalization Error in Deep Learning
Aug 03, 2018

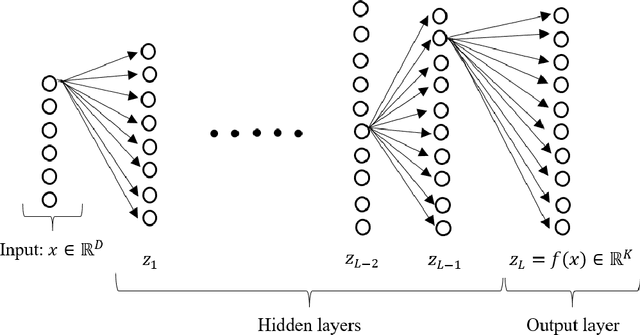

Deep learning models have lately shown great performance in various fields such as computer vision, speech recognition, speech translation, and natural language processing. However, alongside their state-of-the-art performance, it is still generally unclear what is the source of their generalization ability. Thus, an important question is what makes deep neural networks able to generalize well from the training set to new data. In this article, we provide an overview of the existing theory and bounds for the characterization of the generalization error of deep neural networks, combining both classical and more recent theoretical and empirical results.